


python文件读写及形式转化和CGI的简单应用
一丶python文件读写学习笔记
- open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
- filename:包含了你要访问的文件名称的字符串值。
- mode:决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。打1啊大苏dada

- f.read() 为了读取一个文件的内容,调用 f.read(size), 这将读取一定数目的数据, 然后作为字符串或字节对象返回。size 是一个可选的数字类型的参数。当 size 被忽略了或者为负, 那么该文件的所有内容都将被读取并且返回。
>>> f=open('H:\\ceshi.txt','r') >>> a=f.read() >>> a "'1 2 3\\n4 5 6\\nHello, seniusen!\\n'"
-
f.readline() 会从文件中读取单独的一行。换行符为 'n'。f.readline() 如果返回一个空字符串, 说明已经已经读取到最后一行。
-
>>> f = open('H:\\ceshi.txt', 'r') >>> b = f.readline() >>> b '1 2 3\n' >>> b[0] '1' >>> b[1] ' ' >>> b[2] '2' >>> b = f.readline() >>> b '4 5 6\n' >>> b = f.readline() >>> b 'Hello, seniusen!\n' >>> b = f.readline() >>> b ''
f.readlines() 将返回该文件中包含的所有行。如果设置可选参数 sizehint, 则读取指定长度的字节, 并且将这些字节按行分割。
>>> f = open('H:\\ceshi.txt', 'r') >>> for i in f.readlines(): ... print(i) ... 1 2 3 4 5 6 Hello, seniusen!
- f.write(string) 将 string 写入到文件中, 然后返回写入的字符数。如果要写入一些不是字符串的东西, 那么将需要先进行转换。
- f.tell() 返回文件对象当前所处的位置, 它是从文件开头开始算起的字节数。
-
如果要改变文件当前的位置, 可以使用 f.seek(offset, from_what) 函数。from_what 的值, 如果是 0 表示开头, 如果是 1 表示当前位置, 2 表示文件的结尾,from_what 值为默认为0,即文件开头。
- seek(x, 0) :从起始位置即文件首行首字符开始移动 x 个字符
- seek(x, 1) :表示从当前位置往后移动 x 个字符
- seek(-x, 2):表示从文件的结尾往前移动 x 个字符
- 当你处理完一个文件后, 调用 f.close() 来关闭文件并释放系统的资源。
- 当处理一个文件对象时, 使用 with 关键字是非常好的方式。在结束后, 它会帮你正确的关闭文件。
-
>>> f = open('H:\\ceshi.txt', 'r') >>> f.tell() >>> b = f.readline() >>> f.tell() >>> f.seek(2, 0) >>> f.read(1) '2' >>> f.close() >>> f <_io.TextIOWrapper name='H:\\ceshi.txt' mode='r' encoding='UTF-8'> >>> f.closed True >>> with open('H:\\ceshi.txt') as f: ... print(f.readline()) ... 2 3 >>> f.closed True
-
二丶用Python读入excel文件存为csv文件
逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。通常都是纯文本文件。建议使用WORDPAD或是记事本来开启,再则先另存新档后用EXCEL开启,也是方法之一。CSV文件格式的通用标准并不存在,但是在RFC 4180中有基础性的描述。使用的字符编码同样没有被指定,但是bitASCII是最基本的通用编码。 -
# -*- coding: utf-8 -*- """ Spyder Editor This is a temporary script file. 18信计二班黎志柱 """ import pandas as pd def ExcelToCsv_1(StartName, SheetName, EndName): ''' 函数功能: 将excel格式文件转换为csv格式文件,使用iat方法 StartName: excel表格的文件路径 SheetNmae: excel表格中的表格名称 EndName: csv文件的保存路径 ''' grade = pd.read_excel(StartName, sheet_name=SheetName) for i in range(len(grade.index)): for j in range(1, len(grade.columns)): if grade.iloc[i, j] == '优秀': grade.iat[i, j] = 90 elif grade.iloc[i, j] == '良好': grade.iat[i, j] = 80 elif grade.iloc[i, j] == '合格': grade.iat[i, j] = 60 else: grade.iat[i, j] = 0 grade.to_csv(EndName) def ExcelToCsv_2(StartName, SheetName, EndName): ''' 函数功能: 将excel格式文件转换为csv格式文件,使用replace方法 StartName: excel表格的文件路径 SheetNmae: excel表格中的表格名称 EndName: csv文件的保存路径 ''' grade = pd.read_excel(StartName, sheet_name=SheetName) Grade = grade.replace("优秀", "90") Grade = Grade.replace("良好", "80") Grade = Grade.replace("不合格", "60") Grade = Grade.replace("合格", "60") Grade = Grade.fillna(value = 0) Grade.to_csv(EndName) ExcelToCsv_2("H:\\biaoge\\Python_1.xlsx", "Sheet1", "H:\\biaoge\\Python1.csv") ExcelToCsv_1("H:\\biaoge\\Python_2.xlsx", "Sheet1", "H:\\biaoge\\Python2.csv")
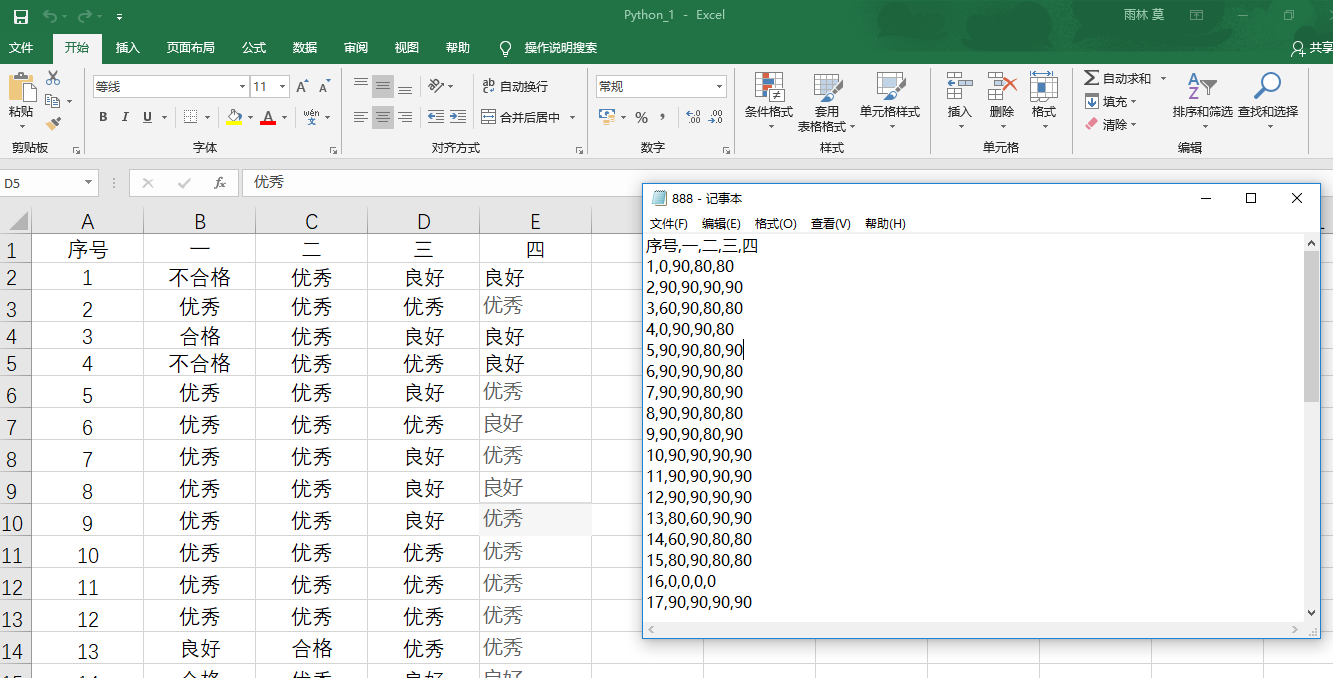
-
-
三丶将csv文件格式转化为html格式
超文本标记语言或超文本链接标示语言(标准通用标记语言下的一个应用)HTML(HyperText Mark-up Language)是一种制作万维网页面的标准语言,是万维网浏览器使用的一种语言,它消除了不同计算机之间信息交流的障碍。它是目前网络上应用最为广泛的语言,也是构成网页文档的主要语言。HTML文件是由HTML命令组成的描述性文本,HTML命令可以说明文字、图形、动画、声音、表格、链接等。HTML文件的结构包括头部(Head)、主体(Body)两大部分,其中头部描述浏览器所需的信息,而主体则包含所要说明的具体内容。# -*- coding: utf-8 -*- """ Created on Mon May 6 10:40:04 2019 @author: lzz """ #e13.1csv2html.py seg1 = ''' <!DOCTYPE HTML>\n<html>\n<body>\n<meta charset=gb2312> <h2 align=center>python成绩</h2> <table border='1' align="center" width=70%> <tr bgcolor='orange'>\n''' seg2 = "</tr>\n" seg3 = "</table>\n</body>\n</html>" def fill_data(locls): seg = '<tr><td align="center">{}</td><td align="center">{}</td><td align="center">{}</td><td align="center">{}</td><td align="center">{}</td></tr>\n'.format(*locls) return seg fr = open("H:\\biaoge\\Python1.csv", "r",encoding='UTF-8') ls = [] for line in fr: line = line.replace("\n","") ls.append(line.split(",")) fr.close() fw = open("H:\\biaoge\\Python1.html", "w") fw.write(seg1) fw.write('<th width="20%">{}</th>\n<th width="20%">{}</th>\n<th width="20%">{}</th>\n<th width="20%">{}</th>\n<th width="20%">{}</th>\n'.format(*ls[0])) fw.write(seg2) for i in range(len(ls)-1): fw.write(fill_data(ls[i+1])) fw.write(seg3) fw.close()
-

-
-
