函数
函数
一、函数的基本使用
1.函数简介
使用函数目的就是为了减少重复编写代码
循环:在相同的地方反复执行代码
函数:在不同的地方反复执行代码
没有函数:维修工每次工作的时候都要先创造工具再工作
有函数:维修工再工作的时候直接拿工具过来工作
2.函数的语法结构
定义阶段
def 函数名(形参):
'''函数注释'''
函数体代码
return 返回值
调用阶段
函数名(实参)
1.def
定义函数的关键字
2.函数名
命名等同于变量名 要做到见名知意
3.形参
可以写 (单个或多个)也可以不写
主要用于接受外界传递给函数体代码内部的数据
可以理解为使用该函数的条件
4.函数体注释
类似于说明说 介绍函数的功能和使用方法
5.函数体代码
整个函数的核心 写逻辑代码的地方
6.return
使用完函数后有没有相应的反馈
3.函数的的定义与调用
函数名()执行优先级最高(定义阶段除外)
- 函数必须先定义在调用
- 函数在定义阶段只检测函数体代码的语法 不执行函数体代码
- 函数在调用阶段才会执行函数体代码
- 定义函数用def 调用函数用函数名()
4.函数的分类
-
内置函数
解释器直接定义好的可以直接用的 eg:len() #数据类型的内置方法也是算内置函数 必须要用.的方式才能使用 -
自定义函数
-
空函数
函数体代码为空 用pass或...补全 空函数主要作为前期项目搭建 def func(): pass -
无参函数
函数定义阶段括号内没有填写参数 def func(): print('xxx') #无参函数直接函数名加括号调用即可使用 -
有参函数
函数名定义阶段括号里写参数 def func(a): print(a) func(123) #123 #有参函数需要函数名加括号并传对应个数的实参才能调用
-
5.函数的返回值
-
什么是返回值
调用函数之后返回给调用者的结果 也可以理解为函数体代码执行完有没有反馈
-
如何获取返回值
变量名 = 函数名()
def func(): a = 666 print(123) return a res = func() print(res) #666 123 ''' 函数定义阶段 不执行函数体代码 看同一级别 res=func() 函数名加括号调用 执行函数体代码 a = 666 打印123 return 返回666 结束函数体代码 把结果绑定给res 打印res ''' -
函数返回值的多种情况
-
函数体代码中没有return关键字 :默认返回None
def func(): pass res=func() print(res) #结果为:None -
函数体代码有return关键字:后面不写东西也返回None
def func(): pass return res=func() print(res) #结果为:None -
函数体代码有return关键字:后面有什么就返回什么(变量名就返回对应的数据值)
def func(): pass return 123 #如果是变量名则返回对应的值 res=func() print(res) #结果为:123 -
函数体代码有return关键字:后面多个数据之用逗号隔开 默认自动组织成元组返回 列表需要自己定义
def func(): pass return 1,2 #多个数据值用逗号隔开 res=func() print(res) #结果为:(1,2) ''' 列表字典需自己定义 return [1,2] 如果有一个没定义则外层用元组包起来([1,2],3) ''' -
当函数体代码遇到return关键字会立刻结束函数体代码的运行(类似于break)
def func(): print('上面') return 'a' print('下面') #永远不会执行 func() #结果为:上面
-
二、函数的参数
1.形式参数与实际参数
-
形式参数
函数在定义阶段括号内填写的参数 def func(a): pass -
实际参数
函数在调用阶段括号内填写的参数 func(1) -
形参与实参的关系
1.形参类似于变量名 实参类似于数据值 def func(name): pass func('jason') #此时jason与name临时绑定 2.函数在调用阶段 形参与实参会动态绑定 函数体代码运行结束会立刻解除绑定 def func(name): print(name) func(1) func(2) #第一次1与name绑定 函数体代码结束 解除绑定 name与2绑定
1.位置形参 与位置实参
位置形参:函数在定义阶段括号内从左往右依次填写的变量名
位置实参:函数在调用阶段括号内从左往右依次填写的数据值
def func(a,b,c):# 位置形参
pass
func(1,2,3)# 位置实参
'''
1.实参可以是数据值,也可以是绑定了数据值的变量名。
2.位置实参在给位置形参传值的时候个数必须一致,不能多也不能少会报错。
'''
2.关键字实参与默认值形参(关键字形参)
关键字实参:函数在调用阶段括号内以什么等于什么传值(name=‘jason’)
def func(a,b):
print(a,b)
func(a=10,b=20) # 关键字实参 也可以:(b=20,a=10)
func(10,b=20) # 位置实参与关键字实参可以一起使用
'''
1.关键字实参给位置形参传值时打破了位置的限制,不用按照从左到右依次赋值。
2.需注意当位置实参和关键字实参一起用时,位置实参要在最后。
【简单在前,复杂在后,同复杂随便。但是需满足第三点】
3.调用函数时,一个形参只能接收一个实参
eg:
func(10,a=10) 此时由于位置形参a已经等于10了,关键字实参又给a赋了20的值,所以报错
'''
默认值形参:也可以叫做关键字形参 函数在定义阶段括号内以什么等于什么填写参数
用了默认值形参 用户传值就用用户传的值 用户不传就用默认的值
'默认值形参的定义也遵循【简单在前,复杂在后,同复杂随便】,但是一个形参只能接收一个实参'
def register(name,gender='男'): # 默认值形参
print(name,gender)
1) register('jason') # 第二个可以不传实参
#结果为:jason 男
2) register('jason','女') # 第二个可以传位置实参
#结果为:jason 女
3) register('jason',gender='女') # 第二个可以传关键字实参
#结果为:jason 女
————————————————————————————————————————————
def register(gender='男'): # 默认值形参
print(gender)
register() # 不传实参
#结果为:男
3.默认长形参(*与**在形参中的作用)
*在形参中:接收多余的位置参数 并整理成元组赋值给后面的变量名>> * args
def func(*args):
print(args)
func() # () 没有参数给args所以是空元组
func(1) # (1,)
func(1,2,3) # (1,2,3)
——————————————————————————————————
def func(a,*args):
print(a,args)
func() # 结果会报错 因为a需要传一个参数
func(1) # 1 () 1赋值给a,没有参数给args所以是空元组
func(1,2,3) # 1 (2,3) 1赋值给a,2,3赋值给args组成元组
**在形参中:接收多余的关键字参数并组成字典赋值给后面的>> * * kargs
def func(**kwargs):
print(kwargs)
func() # {} 没有关键字实参给kwargs所以是空字典
func(a=1) # {'a':1}
func(a=1,b=2) # {'a':1,'b':2}
——————————————————————————————————
def func(a,**kwargs):
print(a,kwargs)
func() # 结果会报错 因为a需要传一个参数
func(1) # 1 {}
func(1,b=22) # 1 {'b':22}
*与 * *结合使用:无论怎么传值都可以执行
def func(*args,**kwargs):
print(args,kwargs)
func() # () {}
func(1,a=2) # (1,) {'a':2}
'位置实参给*结果是元组'
'关键字实参给**结果是字典'
4.可变长形参(* 与 ** 在实参中的作用)
*在实参中:相当于把列表、字典、字符串、元组、集合利用for循环取出一次性传给函数
def func(a,b):
print(a,b)
l1=[1,2]
s1='zz'
d1={'a':1,'b':2} #字典在做循环时只有键参与
func(*l1) # 结果为:1 2
func(*s1) # 结果为:z z
func(*d1) # 结果为:a b
'当形参中没有*与**时,结果就是一个一个的数据值'
————————————————————————————————————
def func(*args,**kwargs):
print(args,kwargs)
l1=[1,2]
s1='zz'
d1={'a':1,'b':2} #字典在做循环时只有键参与
func(*l1) # 结果为:(1, 2) {}
func(*s1) # 结果为:('z', 'z') {}
func(*d1) # 结果为:('a', 'b') {}
'当形参中有*与**时,结果*就是元组,**就是字典'
** 在实参中:仅针对字典 把字典的键值对当作关键字实参 一次性传给函数
def func(**kwargs):
print(kwargs)
d={'name':'jason','age':18}
func(**d) # 结果为:{'name': 'jason', 'age': 18}
'**d就等同于 name="jason" age=18'
5.命名关键字参数
当要求形参必须使用关键字实参传值
def func(*args,c,**kwargs):#注意c的位置要在**kwargs前
print(args,c,kwargs)
func(1,2,c=3,a=4,b=5)
#结果为:(1,2) 3 {'a':4,'b':5}
'1和2给*args,关键字实参c=3给形参c,多余的关键字实参给**kwargs'
三、名称空间
1.名称空间
名称空间就是用来存放变量名与数据值绑定关系的地方 也可以理解为是存储变量名的地方
name = '张三'
#底层原理:
1.在内存中申请一块空间存储'张三'
2.给'张三'绑定一个变量名name
3.此时变量名与数据值之间的绑定关系就会存放在名称空间中
4.后续使用变量名name就可以找到'张三'
'del 变量名 其实就是清除变量名与数据值的绑定关系'
名称空间的分类
-
内置名称空间
python解释器运行时立刻创建的名称空间(里面存放内置的名字>>len()input()等
-
全局名称空间
py文件运行代码的过程中产生的名字就会储存在改空间中>>普通代码的变量名、分支循环的变量名、函数名、类名
-
局部名称空间
函数体代码/类体代码 执行过程中内部产生的名字都会被存放在该空间中
2.名称空间存户哦周期及作用范围(作用域)
名称空间存活周期:
-
内置名称空间
创建:解释器运行 销毁:解释器结束
-
全局名称空间
创建:py文件运行 销毁:py文件结束
-
局部名称空间
创建:函数体/类体代码运行 销毁:函数体/类体代码结束
作用域:
-
内置名称空间
程序的任何位置都可以使用
-
全局名称空间
程序的任何位置都可以使用
-
局部名称空间
只能在局部名称空间使用 且不互通
3.名字的查找顺序
a = '全局'
def func():
a = '局部'
func()
print(a)
#结果是:全局
——————————————————————————————————————————————
#查找名字时要先确定自己在哪个名称空间
1.当前在局部名称空间时
局部名称空间 >> 全局名称空间 >> 内置名称空间
2.当前在全局名称空间时
全局名称空间 >> 内置名称空间
4.局部名称空间案例
-
相互独立的局部名称空间默认不能互相访问
def func1(): name='jason' print(age) def func2(): age=18 print(name) #此时调用以上两个函数会报错,因为局部名称空间不互通 -
局部名称空间嵌套
def func1(): #1 x = 2 #3 def func2(): #4 x=3 #6 def func3(): #7 x=4 #9 print(x) #10 func3() #8 func2() #5 func1() #2 结果为4 当函数嵌套调用时,一直打开到最内层的func3,则print(x)会从最内层往外查找 哪个最先有x就用哪个 '这里需要注意:当func3里的x=4如果在print(x)下面 就会报错,因为函数在定义阶段名字的查找顺序就已经固定好了,它知道要在func3里查找 但是由于x=4还没定义出来 所以会报错。除非把func3中的x=4去掉才会往外一层找x=3'
5.global与nonlocal
了解:修改不可变类型(整型、浮点、字符串、元组)需用关键字声明
修改可变类型(列表、字典、集合)不需要关键字声明
不过经过实验可变类型加上关键字也不影响!所以不用纠结什么类型,都加上关键字也问题不大!!
- 局部修改全局的数据 golabal
【不可变类型】:
a = 10
def func():
global a # 局部修改全局数据
a = 99 # 把全局a=99
func()
print(a) # 结果为:99
————————————————————————————————
【可变类型】:
a = [1,2,3]
def func():
a[0] = 99 # 把全局a列表索引0改为99
func()
print(a) # 结果为:[99,2,3]
-
内层局部修改外层局部的数据(函数嵌套)nonlocal
【不可变类型】: def outer(): a = 10 def inner(): nonlocal a # 内层局部改外层局部数据 a = 99 # 把外层局部a=99 inner() print(a) # 结果为99 outer() ———————————————————————————————— 【可变类型】: def outer(): a = [1,2,3] def inner(): a[0] = 99 # 把外层局部a列表索引0改为99 inner() print(a) # 结果为:[99,2,3] outer()
四、装饰器
1.函数名的多种用法
打印函数名发现:函数名其实绑定的就是一个内存地址 该地址里存放着一段代码 函数名加括号就会找到该代码然后去执行
-
可以当作变量名多次赋值
def func(): pass a=b=func # 让a和b同时绑定func a() # 此时a加括号可以调用func函数 b() # b加括号也可以调用func函数 -
可以当作函数的参数
def func(): print('我是另外一个函数func') def func1(a): a() # 2.传进来的func加括号就可以调用func函数 func1(func) # 1.把func函数名当作参数传给func1 #结果为:我是另外一个函数func -
可以当作函数的返回值
def index(): print('index') def func(): print('func') return index # 返回值也可以写一个函数名 res=func() # 变量名res接收func的返回值 接收的就是index函数名 print(res) # 打印res就是index的内存地址 res() # res()就等同于index() -
可以当作容器类型的数据(列表、字典、元组、集合)
def func(): pass l1 = [1,2,func] # 函数名可以放在列表中当作数据值 l1[-1]() # 列表取值加括号也可以调用函数 ———————————————————————————————————— def func(): print(111) d1 = {'1':func} # 函数名可以放在字典中当作值 d1.get('1')() # 字典取值加括号也可以调用函数 -
编程套路
#编程套路 def register(): print('注册功能') def login(): print('登录功能') dict={ '1':register, '2':login, } while True: print(""" 1.注册 2.登录 """) choice=input('输入指令:').strip() if choice in dict: dict.get(choice)() else: print('指令不存在')
2.闭包函数
闭包函数:定义在函数内部的函数(函数嵌套) 且内部函数用到外部函数名称空间中的名字
闭包函数的作用:提供了另一种给函数传参的方式
#给函数体传参的方式:
方式一:直接传参
def register(name):
print(name)
register('jason')
#结果为:jason
方式二:闭包函数
def outer(name):
def inner():
print(name) # 内部函数用外部函数的名字name
return inner
res=outer('jason') # 给外部函数传一个值jason并把返回值(内部函数名)赋给res
res() # res()等同于inner()
#结果为:jason
3.装饰器简介
-
装饰器本质
在不改变被装饰对象原来的调用方式和内部代码下 给被装饰对象添加新的功能
-
装饰器原则
不许修改 只许扩展
-
储备知识 time模块
#时间相关操作 import time #导入一个时间模块 print(time.time())# 1665482833.111403 距离1970年1月1日0时0分0秒所经历的秒数 time.sleep(3) # 让程序原地等待3秒 _____________________________________________ import time count = 0 start_time = time.time() # 循环前获取一下时间为开始时间 while count < 1000: print(123) count += 1 end_time = time.time() # 循环后获取一下时间为结束时间 print('执行时间:', end_time - start_time) #结束时间-开始时间=共用时多久
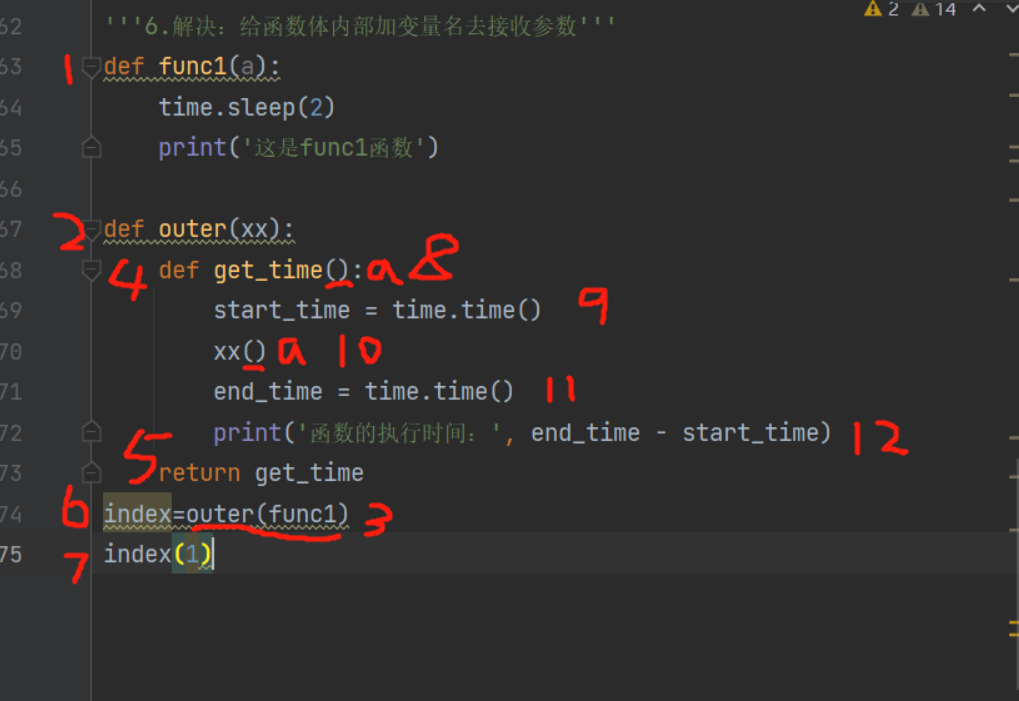
4.装饰器推导流程
要求:1.再不改变被装饰对象原代码和调用方式的情况下给被装饰对象添加新的功能
2.统计index函数的执行时间
import time
def index():
time.sleep(3)
print('这是index函数')
def func():
time.sleep(1)
print('这是func函数')
'''1.直接在调用index函数的前后添加代码'''
start_time=time.time()
index()
end_time=time.time()
print('函数的执行时间:',end_time-start_time)
#缺陷:当index调用的地方较多时,反复拷贝代码太麻烦
'''2.解决:相同的代码在不同地方反复执行,用函数包起来'''
def get_time():
start_time = time.time()
index()
end_time = time.time()
print('函数的执行时间:', end_time - start_time)
get_time()
#缺陷1.函数体代码写死了,只能统计index函数的执行时间
#缺陷2.改变了原代码的调用方式
'''3.解决缺陷1:利用传参来让统计的函数写活'''
def get_time(xx):
start_time = time.time()
xx()
end_time = time.time()
print('函数的执行时间:', end_time - start_time)
get_time(func) #要统计哪个函数就把哪个函数当作参数传进来
get_time(index) #要统计哪个函数就把哪个函数当作参数传进来
'''4.解决缺陷2:直接传参不行就用闭包函数传参'''
def outer(xx):
def get_time():
start_time = time.time()
xx()
end_time = time.time()
print('函数的执行时间:', end_time - start_time)
return get_time
res=outer(index) #要统计哪个函数就把哪个函数当作参数传进来
res()
res=outer(func) #要统计哪个函数就把哪个函数当作参数传进来
res()
#缺陷:改变了原代码的调用方式
'''5.解决:把接收返回值的变量名写死,写成index'''
def outer(xx):
def get_time():
start_time = time.time()
xx()
end_time = time.time()
print('函数的执行时间:', end_time - start_time)
return get_time
index=outer(index) #要统计哪个函数就把哪个函数当作参数传进来
index()
#缺陷:只可以用无参函数,如果是有参函数会报错
'''6.解决:给函数体内部加变量名去接收参数'''
def func1(a):
time.sleep(2)
print('这是func1函数')
def outer(xx): #xx就是func1
def get_time(a):
start_time = time.time()
xx(a)
end_time = time.time()
print('函数的执行时间:', end_time - start_time)
return get_time
index=outer(func1) #index就是get_time
index(1) #index()就是get_time()
#缺陷:有参函数如果是多个参数也不兼容
'''7.解决:接收参数的变量名用可变长参数代替'''
def func1(a):
time.sleep(2)
print('这是func1函数')
def func2(a,b,c,d):
time.sleep(2)
print('这是func2函数')
return 123
def outer(xx): #xx就是func1
def get_time(*args,**kwargs):
start_time = time.time()
xx(*args,**kwargs)
end_time = time.time()
print('函数的执行时间:', end_time - start_time)
return get_time
index=outer(func2) #index就是get_time
index(1,2,3,4) #index()就是get_time()
res=index(1,2,3,4)
print(res)#结果是None 因为现在的index其实是get_time!
#缺陷:如果被装饰的函数有返回值则会返回一个None
'''8.找到真正要执行函数的位置让一个res去接收他的返回值(xx就是真正执行的)'''
def func1(a):
time.sleep(2)
print('这是func1函数')
def func2(a,b,c,d):
time.sleep(2)
print('这是func2函数')
return 123
def outer(xx): #xx就是func1
def get_time(*args,**kwargs):
start_time = time.time()
res=xx(*args,**kwargs)
end_time = time.time()
print('函数的执行时间:', end_time - start_time)
return res
return get_time
index=outer(func2) #index就是get_time
res=index(1,2,3,4)
print(res)#结果就是对应函数的返回值!
5.装饰器模板
def func1():
print('func1')
return 111
def func2(a):
print('func2')
return 222
——————————————————————————————————————————————————————
#装饰器模板:
def outer(func): #func用来绑定真正被装饰的对象内存地址
def inner(*args,**kwargs):
#执行被装饰对象之前做的额外操作
res = func(*args,**kwargs)
#执行被装饰对象之后做的额外操作
return res
return inner
————————————————————————————————————————————————————————
#调用:
【无参】
func1=outer(func1) #左边func1就是inner 右边的func1就是把真正函数名当参数传给装饰器
res=func1() #func1()就是inner() 并接收inner的返回值 inner的返回值就是真的函数的返回值
print(res) #打印真正被装饰的函数的返回值
【有参】
func2=outer(func2)
res=func2(1)
print(res)
6.装饰器语法糖
语法糖会自动将下面紧挨着的函数名当作第一个参数自动穿给@函数调用
【定义】
def outer(func_name):
def inner(*args, **kwargs):
print('执行被装饰对象之前可以做的额外操作')
res = func_name(*args, **kwargs)
print('执行被装饰对象之后可以做的额外操作')
return res
return inner
_________________________________
@outer # 等同于调用阶段的func=outer(func)
def func():
print('这是func函数')
return '111func'
@outer # 等同于调用阶段的index=outer(index)
def index():
print('这是index函数')
return '111index'
_________________________________
【调用】
#func = outer(func) 加了语法糖则不需要该操作
func()
#index=outer(index) 加了语法糖则不需要该操作
index()
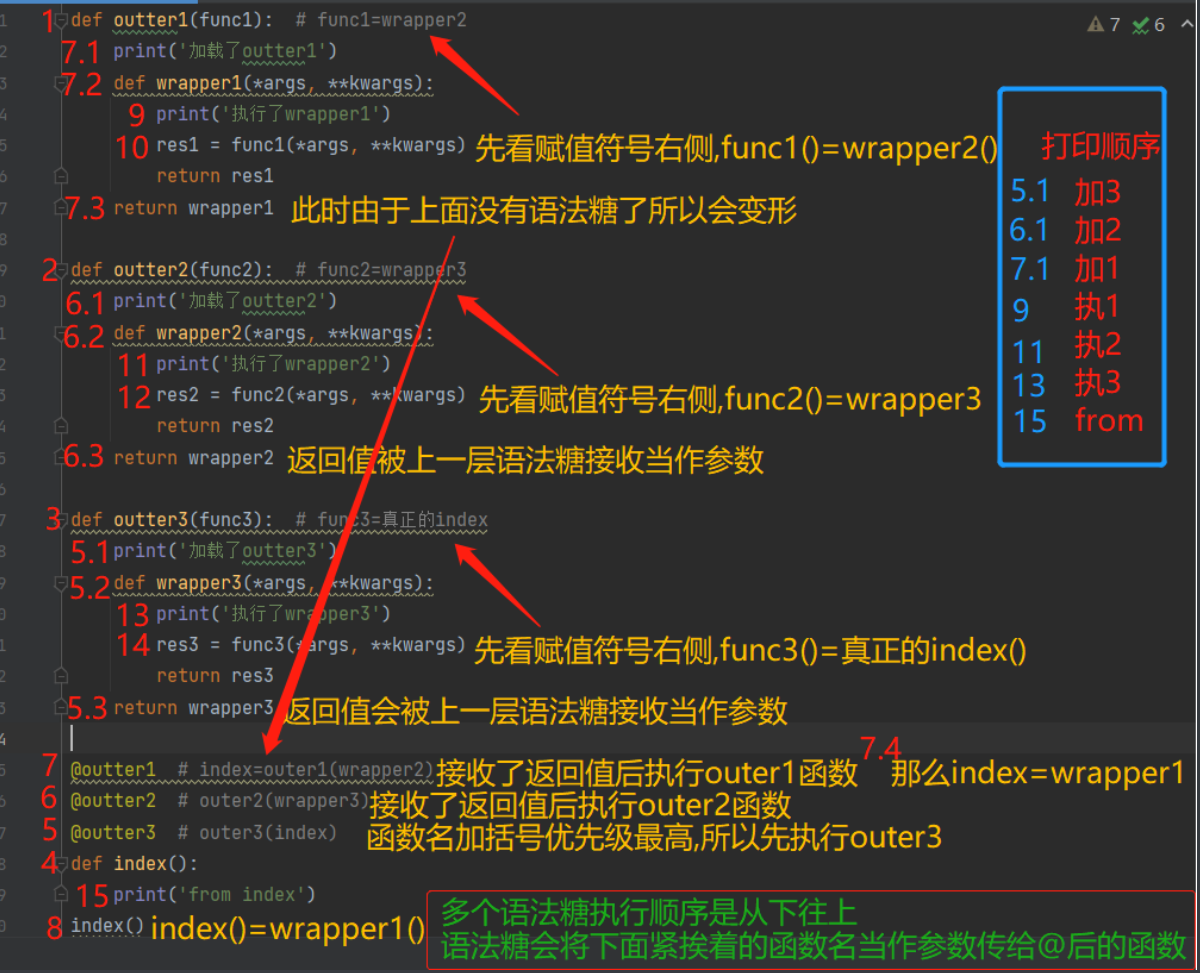
7.多层语法糖
def outter1(func1): #func1=wrapper2
print('加载了outter1')
def wrapper1(*args, **kwargs):
print('执行了wrapper1')
res1 = func1(*args, **kwargs)
return res1
return wrapper1
def outter2(func2): #func2=wrapper3
print('加载了outter2')
def wrapper2(*args, **kwargs):
print('执行了wrapper2')
res2 = func2(*args, **kwargs)
return res2
return wrapper2
def outter3(func3): # func3=真正的index
print('加载了outter3')
def wrapper3(*args, **kwargs):
print('执行了wrapper3')
res3 = func3(*args, **kwargs)
return res3
return wrapper3
@outter1 # index=outer1(wrapper2)>>返回值为wrapper1
@outter2 # outer2(wrapper3)>>返回值为wrapper2
@outter3 # outer3(index)>>返回值为wrapper3
def index():
print('from index')
index()
'''
运行结果:
加载了outter3
加载了outter2
加载了outter1
执行了wrapper1
执行了wrapper2
执行了wrapper3
from index
'''
注意
1.多层语法糖的顺序是从下往上的
2.语法糖h会自动将他紧挨着的函数名当作参数传给@的函数调用
3.多次语法糖在每次执行后如果上面还有语法糖则直接将返回的数据传给上面的语法糖
如果上面没有语法糖后变形为index = outer1(wrapper2)
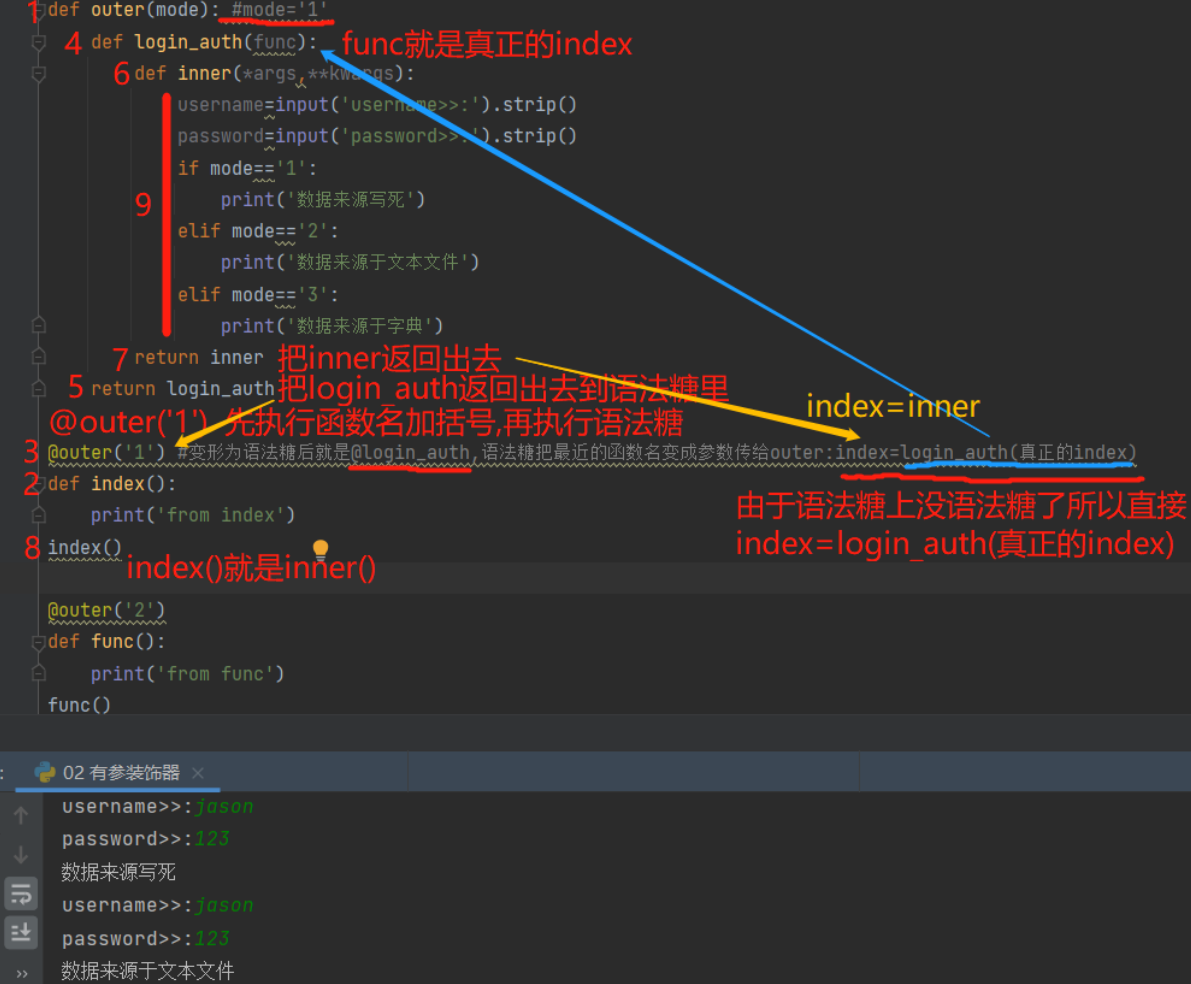
8.有参装饰器
当装饰器中需要额外的参数的时候就要用到有参装饰器
'函数名加括号执行优先级最高'
有参装饰器流程:
@outer('1')
1.先看函数名加括号的执行 outer('1')
2.再看语法糖的操作 @outer
# 校验用户是否登录装饰器
def outer(mode): #mode='1'
def login_auth(func):
def inner(*args,**kwargs):
username=input('username>>:').strip()
password=input('password>>:').strip()
if mode=='1':
print('数据来源写死')
elif mode=='2':
print('数据来源于文本文件')
elif mode=='3':
print('数据来源于字典')
#res=func(*args,**kwargs) #此处不写则不会执行真正index里的print
#return res #此处不写则不会执行真正index里的print
return inner
return login_auth
@outer('1') #变形为语法糖后就是@login_auth,语法糖把最近的函数名变成参数传给outer:index=login_auth(真正的index)
def index():
print('from index')
index()
@outer('2')
def func():
print('from func')
func()
9.有参装饰器与无参装饰器模板
无参:
def outer(func):
def inner(*args,**kargs):
#执行装饰器之前做的操作
res = func(*args,**kargs)
#执行装饰器之后做的操作
return res
return inner
@outde
def index():
pass
有参:
def oouter(mode)
def outer(func):
def inner(*args,**kargs):
#执行装饰器之前做的操作
res = func(*args,**kargs)
#执行装饰器之后做的操作
return res
return inner
return outer
@outde(1)
def index():
pass
10.装饰器修复技术
help(函数名)
#补充知识:
def func():
"""这是index函数"""
pass
help(func) #会告诉这个名字的基本信息
#结果为:func()
# 这是index函数
让装饰器看起来更逼真:
from functools import wraps # 导入一个wraps模块
def outer(func_name):
@wraps(func_name) # 仅仅是为了让装饰器更逼真(用户用help方法也看不出来)
def inner(*args, **kwargs):
"""我是inner 我擅长让人蒙蔽"""
res = func_name(*args, **kwargs)
return res
return inner
@outer
def func():
"""我是真正的func 我很强大 我很牛 我很聪明"""
pass
help(func)#help查看该函数真正信息就会发现是真正的func函数信息
'如果不加wraps模块查看的就是inner函数信息'
print(func)#<function func at 0x000002DB3568EE50>
五、递归函数
1.递归函数
使用递归函数注意:
- 函数直接或者间接调用自己就叫递归调用
- 每次调用都必须比上一次简单 且要有一个明确的结束条件
递归函数的应用场景:
-
递推:一层一层往下寻找答案
-
回溯:根据明确的条件往上得出结果
1.递归——直接调用:('自己调自己') def index():#1 print('这是index函数')#3 index()#4 index()#2 #执行顺序:12343434一直重复 —————————————————————————————————————————— 2.递归——间接调用:('别人调我,我调别人') def index():#1 print('这是index函数')#6 func()#7 def func():#2 print('这是func函数')#4 index()#5 func()#3 #执行顺序:123456745674567一直重复pycharm允许函数最大调用的次数是1000 实际略有偏差
count = 0 def index(): print('这是index') global count count + = 1 print(count) index() index() #结果为:会一直执行到996或997
练习:
问A年龄,A说我比B大2岁
问B年龄,B说我比C大2岁
问C年龄,c说我比D大2岁
问D年龄,D说我比E大2岁
问E年龄,E说我18岁
"""
get_age(5) = get_age(4) + 2
get_age(4) = get_age(3) + 2
get_age(3) = get_age(2) + 2
get_age(2) = get_age(1) + 2
get_age(1) = 18
"""
def get_age(n):
if n == 1:
return 18
return get_age(n-1) + 2
res = get_age(5)
print(res)
六、算法、三元表达式、各种生成式
算法:解决问题的有效方法
应用场景:推荐算法(视频推送)、成像算法(线上试衣)
常见算法:二分法、冒泡、快排、插入...等等
1.二分法
二分法:不断地对数据进行切割分成两份进行判断 只要找到张耀的结果
要求:待查找的数据必须是有序的
缺陷:因为是从中间开始切割 开头或者结尾查找效率低
#eg:用算法二分法判断82在不在列表中,如果在则取出
l1=[11,23,35,43,55,62,75,82,94]
def get_num(l1,num):
#添加一个结束条件
if len(l1)==0:
print('没找到')
return
#1.获取列表中间数据的索引值
middle=len(l1)//2 # 整除:要除完后的整数 4
#2.比较目标82与中间数4的大小
if num>l1[middle]: # 82>l1[4]
#切片保留右半边列表
right_l1=l1[middle+1:] # 索引4的55比较过 所以切索引4+1
print(right_l1)#[62,75,82,94]
return get_num(right_l1,num)
elif num<l1[middle]:
# 切片保留左半边列表
left_l1=l1[:middle] # 切片索引取值顾头不顾尾 所以索引4默认切到索引3
print(left_l1)#[11, 23, 35, 43]
return get_num(left_l1,num)
else:
print(f'找到了')
get_num(l1,82)
get_num(l1,20)
"""
将想要查找的列表和数据传到函数里
对列表的长度进行整除
判断 想要查找的数据 和整除得出的中间数是否相等
大于 就往右切[middle:]middle要加1 因为顾头不顾尾 中间数已经比过一次了 返回切好的列表和查找数据 接着切 直到找到位置
小于就往左切[:middle]
"""
2.三元表达式
作用:主要是用来精简代码
场景:当二选一的时候使用三元大表达式比较简单 但是不建议多个三元表达式嵌套
- 如果name是张三则打印''你好'',否则打印''你谁啊'
#普通代码:
name='张三'
if name=='张三':
print('你好')
else:
print('你谁啊')
——————————————————————————————————
#使用了三元表达式:
name='张三'
res='你好'if name=='张三'else '你谁啊'
print(res)
-
函数比较两个数的大小,返回较大的数字
#普通代码: def max_func(a,b): if a>b: return a else: return b res=max_func(1,10) print(res) —————————————————————————————— #使用了三元表达式: def max(a,b): return a if a>b else b res=max(1,10) print(res)
3.各种生成式(表达式/推导式)
-
列表生成式
#语法结构: 【简单】: new_list=[数据操作 for i in 列表变量名] 【复杂】: new_list=[数据操作 for i in 列表变量名 if 条件] """ 列表生成式只能出现for和if,不能后面再加else,因为系统识别不出来else属于谁 执行流程: 1.先执行for循环把一个一个数据值给if判断 2.if判断完直接把数据值交给前面进行数据操作然后组成一个新列表 """#给l1所有值后面加一个你好 l1=['a','b','c'] 【普通代码】: l2=[] for i in l1: l2.append(i+'你好') print(l2) # ['a你好', 'b你好', 'c你好'] —————————————————————————————————————————— 【简单列表生成式】: l2=[i+'你好' for i in l1] print(l2) # ['a你好', 'b你好', 'c你好'] 'for循环把一个一个数据值给前面进行数据操作 然后组成一个新列表' ——————————————————————————————————————————— 【复杂列表生成式】: l1=['a','b','c'] l2=[i+'你好' for i in l1 if i=='a'] print(l2) # ['a你好'] 'for循环把一个一个数据值给后面的if判断条件,把满足该条件的数据给前面进行数据操作 然后组成一个新列表' -
字典生成式
#补充知识: enumerate() #for循环一个列表时还会同时产生一个默认从0开始的编号(括号里加start=1则是从1开始) s1='a,b,c' for i,j in enumerate(s1,start=1): print(i,j) #结果为: 1 a # 2 b # 3 cs1='abc' d1={i:j for i,j in enumerate(s1)} print(d1) #{0:'a',1:'b',2:'c'} """for循环s1字符串,并调用一个enumerate函数,编号赋值给i,字符串里单个值赋值给j。 然后再给到数据操作上组成i:j""" -
集合生成式
s1='abbbbcc' res={i for i in s1} print(res) #{'b','c','a'} """for循环s1字符串 并把一个一个字符给前面的数据操作上组成集合(集合自动去重且无序)"""
没有元组生成式 元组该操作后面叫迭代器/生成器
七、匿名函数
匿名函数就是没有名字的函数 要用关键字lambda
#语法结构:
lambda 形参:要返回的值
#使用场景:(主要用在简单的逻辑功能上)
一般都是配合'内置函数一起使用',主要用来减少代码
#eg:用函数统计a+b的结果
【普通代码:】
def func(a,b):
return a+b
res=func(1,10)
print(res)#结果为:11
——————————————————————————————————————
【匿名函数:】#只是为了了解匿名函数怎么回事!并不是真正使用方法
res=lambda a,b:a+b
print(res)#<function <lambda> at 0x000001C91F375280>
a=res(1,10)
print(a)#结果为:11
"""这样做就是给匿名函数变成了有名函数,不符合匿名函数的应用场景!。此处只做简单介绍,真正要配合下面内置函数一起使用!!!"""
八、重要的内置函数
1.map()映射
把一个东西经过函数的操作变成另一个东西 或称就叫做映射
#eg:让列表每一个数据值加1
"""不使用匿名函数"""
l1=[1,2,3]
def func(a):
return a+1
res=map(func,l1)#map()括号里填写一个函数,和可迭代对象。返回值让res接收
print(list(res))#map也类似于一个工厂,你找他要才会给你,所以要用一个list括起来打印
#结果为:[2,3,4]
——————————————————————————————————
"""使用匿名函数"""
l1=[1,2,3]
res=map(lambda a:a+1,l1) #map(lambda 形参:返回值,可迭代对象)
print(list(res))#结果为:[2,3,4]
#结果为:[2,3,4]
以上可以看出用匿名函数就是为了简化一下需要简单操作的函数代码
2.max() 求最大 min() 求最小
==默认括号内不用传函数 如果是字典要传函数比较v值 则在括号内写key=func 会自动加括号调用 比大小
【列表操作】
#取列表中最大的数据值
l1=[1,2,3,4]
res=max(l1)#底层也是用for循环取每一个数据值判断最大值
print(res)
【字典操作】
"""错误做法"""
#字典在做for循环的时候只是在循环键!!键在比较大小时会用ASCII码来比较!
d1 = {
'zj': 100,
'jason': 8888,
'berk': 99999999,
'oscar': 1}
res=max(d1)
print(res) #错误做法!这里比较的是键的ascii码大小
————————————————————————————————————————————————————
"""不使用匿名函数"""
def func(a):
return d1.get(a)
res=max(d1,key=func) #for循环字典的每一个键当作参数执行func函数,返回值为字典V值然后做比较
print(res)
#结果为:break 返回的结果是K键(比较用V值比较,返回K键)
————————————————————————————————————————————————————
"""使用匿名函数"""
res=max(d1,key=lambda a:d1.get(a))#max(key=lambda 形参:返回值,可迭代对象)
print(res)
#结果为:break 返回的结果是K键(比较用V值比较,返回K键)
以上可以看出用匿名函数就是为了简化一下需要简单操作的函数代码
3.reduce()传多个值经过操作返回一个值
#语法结构:
reduce(函数,可迭代对象)
#用reduce时注意python3解释器把它移到了模块里,需要先导入模块
"""使用匿名函数操作"""
from functools import reduce #需导入模块
l1=[1,2,3]
res=reduce(lambda a,b:a+b,l1)#reduce(lambda 形参1,形参2:返回值,可迭代对象)
print(res)
#结果为:6
for循环可迭代对象,'让a和b接收列表的前两个值'然后返回(a+b的结果),再循环依次让加过给a,取列表下一个值给b然后返回(a+b的结果)
4.zip() 拼接多个数据集并组成元组
把多个数据集用for循环依次取出 然后分别组成员组 也需要list括起来
木桶原理 数据集个数不同时按照最短的来拼接
eg:把以下数据集中的数据拼接为一个列表
l1 = [1,2,3,4]
s1 = 'abc'
t1 = (1,2,3,4)
res = zip(l1, s1, t1)
print(list(res))
#结果为:[(1,'a',1), (2,'b',2), (3,'c',3)]
——————————————————————————————————————————————————
还可以把以上数据解压赋值
l1 = [1, 2, 3, 4]
s1 = 'abc'
t1 = (1, 2, 3, 4)
a,b,c= zip(l1, s1, t1)
print(a,b,c)
#结果为:(1,'a',1) (2,'b',2) (3,'c',3)
5.filter()过滤筛选
#语法结构:
filter(函数,可迭代对象)
#底层原理是for循环可迭代对象然后当作参数给函数去处理后返回满足的结果
eg:过滤取出列表里大于2的数据
l1 = [5,2,3,4]
"""不使用匿名函数操作"""
def index(a):
return a>2
res = filter(index,l1)
print(list(res))
#结果为:[5,3,4]
——————————————————————————————
"""使用匿名函数操作"""
res = filter(lambda a:a>2,l1)#filter(lambda 形参:返回值,可迭代对象)
print(list(res))
#结果为:[5,3,4]
6.sorted()排序
#语法结构
sorted(可迭代对象) #默认升序
'括号内加reverse=True 则为降序'
#给列表升序排序:
l1=[1,8,3,6]
res=sorted(l1)
print(res)
#结果为:[1,3,6,8]
————————————————————————————
#给列表降序排序:
l1=[1,8,3,6]
res=sorted(l1,reverse=True)
print(res)#[8, 6, 3, 1]
九、常见内置函数
1.abs()
把数据值变成绝对值(正数)
print(abs(10)) #10
print(abs(-10))#10
2.all()
判断容器类型中所有数据值对应的布尔值都是True结果就是True 否则就是False 类似于and
print(all([1,2,3])) # True
print(all([0,1,2])) # False
3.any()
判断容器类型中所有数据值对应的布尔值有一个结果就是True 类似于or
print(any([0,None,''])) # False
print(any([1,0,None,''])) # True
4.bin()oct()hex()int()
print(bin(10)) # 十 >> 二
print(oct(10)) # 十 >> 八
print(hex(10)) # 十 >> 十六
print(int(0b1010)) # 二 >> 十
print(int(0o12)) # 八 >> 十
print(int(0xa)) # 十六 >> 十
5.bytes()
类似于编码解码
s1='哈'
res=s1.encode('utf8') # 编码
print(res) # b'\xe5\x93\x88'
res1=res.decode() # 解码
print(res1) # 哈
res=bytes(s1,'utf8') # 转为bytes类型用utf8
print(res) #结果为:b'\xe5\x93\x88'
res1=str(res,'utf8') # 转为字符串类型用utf8
print(res1) #结果为:哈
6.callable()
判断一个名字是否可以加括号调用
name = 'jason'
def func():
pass
print(callable(name)) # False
print(callable(func)) # True
7.chr()ord()
根据ASCII码表左数字语字母转换
print(chr(65))#A
print(ord('A'))#65
8.dir()
获取对象内部可以通过句点符调用的方法名字
print(dir(name))
9.divnod()
获取出完后的整数与余数
i,j=divmod(10,2)
print(i,j)
#结果为:5 0
10.enumerate()枚举
for循环可迭代对象时还会同时产生一个默认从0开始的编号(括号内加start=1 则是从1开始)
s1='abc'
for i,j in enumerate(l1,start=1)
print(i,j)
#结果为:1 a
# 2 b
# 3 c
11.eval()exec()
可以识别字符串中的python代码并执行
区别:eval只能识别简单的
exec可以识别复杂的
s1 = 'print(123)'
eval(s1) # 只能识别简单的结构
#结果为:123
——————————————————————————————————————
s2='for i in range(10):print(i)'
exec(s2) # 能识别复杂的结构
#结果为:循环打印1~9
12.hash()
加密 返回的是密文
print(hash('123'))
#结果为:5474369475686684015
13.id()input()isinstance()
id() # 获取对象的内存地址
s1='aaa'
print(id(s1)) # 2996384812336
input() # 接收用户输入的信息
choice = input('输入指令:').strip()
isinstance() # 判断某个数据类型是否属于某个数据类型
print(isinstance(123,int)) # True
print(isinstance(123,str)) # False
14.open()
文件操作:打开一个文件
with open(r'a.txt','r',encoding='utf8')as f:
print(f.read())
#结果为:文件里的内容
15.pow()
求幂指数
print(pow(2,3)) # 8
print(pow(2,4)) # 16
16.range()
类似于工厂生产数据 要什么给什么
for i in range(10):
print(i)
#结果为:打印0~9的数字
17.round()
五舍六入(python对数字不敏感)
print(round(10.5)) # 10
print(round(10.6)) # 11
18.sum()
求和
l1=[1,2,3]
print(sum(l1)) # 6
十、可迭代对象
可迭代对象在python中可以理解为能否被for循环
1.可迭代对象:
对象内置方法里面有__iter__方法的就是可迭代对象
2.迭代的含义:
就是更新换代 每次更新都基于上一次的结果
3.可迭代对象的范围
可迭代对象:str、list、dict、set、tuple、文件对象
不可迭代对象:int、float、bool、函数对象
十一、迭代器对象
1.迭代器对象:
可迭代对象调用__iter__方法后 就是迭代器对象
只要内置方法里有__iter__和__next__方法的都是
__next__方法就是迭代取值 for循环的本质
2.简写:
__iter__简写:iter()
__next__简写:next()
3.迭代器对象的作用:
提供了一种不依赖于索引取值的方式
迭代器对象可以让字典、集合这些无序的类型能够被for循环
4.注意事项:
可迭代对象调用完__iter__后会变成迭代器对象
迭代器对象如果在调用__iter__则不会有任何变化 还是迭代器对象本身
5.迭代器对象实操:
-
不用for循环依次打印出字符串的单个字符
s1 = 'abc' # 字符串是可迭代对象 res = s1.__iter__() # 可迭代对象调用双下iter方法后变成迭代器对象 print(res.__next__()) # 结果未:a print(res.__next__()) # 结果为:b print(res.__next__()) # 结果未:c print(res.__next__()) # 当没有值可获取了会报错 -
不用for循环一次发引出列表所有值
l1 = [1, 2, 3] # 列表是可迭代对象 count = 0 res = l1.__iter__() # 可迭代对象调用双下iter方法后变成迭代器对象 while count < 3: print(res.__next__()) # 迭代取值 count += 1
6.for循环内部原理
#语法结构:
for 变量名 in 可迭代对象:
循环体代码
#底层逻辑:
"""
1.for循环会先将可迭代对象调用__iter__方法变成迭代器对象
2.然后依次让迭代器对象调用__next__方法取值
3.一但__next__取不到值后报错,但是for循环会【自动捕获并处理】
"""
十二、异常捕获/异常处理
1.异常
代码在运行中的报错就是异常 也叫bug
2.异常的分类
语法错误:不允许出现
逻辑错误:允许出现
3.异常结构
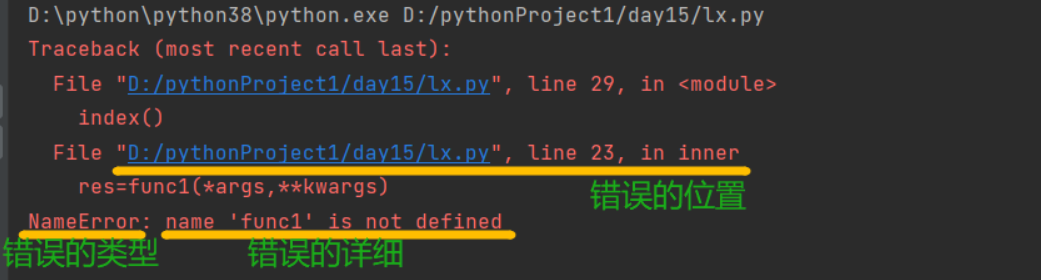
一般最后一条报错信息就是真正的错误位置
4.异常的常见类型
SyntaxError: 语法错误
NameError: 名称错误
IndexError: 索引错误
KeyError: 键错误
TypeError: 类型错误
IndentationError: 缩进错误
......
5.异常的多种语法结构
-
基本语法结构
错误类型后可跟
as e:打印e就是系统提示的错误原因#基本语法结构 try: 可能会出错的代码(待检测的代码) except 错误类型: 针对上述错误类型指定的方案 —————————————————————————————————————— try: name except NameError: print('名字没被定义就使用') #结果为:当异常类型为名称错误时会执行下面的打印,其他类型的错误会报错#升级版语法结构(可把系统提示的异常原因打印出来) try: 可能会出错的代码(待检测的代码) except 错误类型 as e: 针对上述错误类型指定的方案 print(e) #可把系统提示的异常原因打印出来 —————————————————————————————————————— try: name except NameError: print('名字没被定义就使用') print(e)#name 'name' is not defined -
给不同的错误类型制定不同的解决方案
try: 可能会出错的代码 except 错误类型1 as e: 针对错误类型1的解决措施 except 错误类型2 as e: 针对错误类型2的解决措施 ... -
万能异常
任何错误信息都可以使用该方案
try: 待检测的代码 except Exception as e: 处理方案 -
结合else使用
当检测的代码中没有报错则执行else子代码
try: 可能会出错的代码 except Exception as e: 针对所有错误类型统一的处理方案 else: 当以上没有报错时执行的子代码 -
结合finally使用
检测的代码无论报不报错最后都要走finally子代码
try: 可能会出错的代码 except Exception as e: 针对所有错误类型统一的处理方案 finally: 无论以上代码是否报错都会执行的子代码 -
断言
预测接受的数据是什么类型 不对就报错 对就正常执行
name='张三' assert isinstance(name,str) #预测name是不是字符串,对则往下执行,不对就报错 print('猜对咯') -
主动报错
主动报错 当没错误的时候报错 有错误才正常走
name='张三' if name=='张三': raise Exception('一样的?报错!不走了!') else: print('不一样?好小子我喜欢,走我')
6.异常处理练习题
注意:异常处理能少用就少用 只有出现无法控制的情况才应该考虑使用
1.用while循环+异常处理+迭代器对象 完成for循环迭代取值的功能。
l1=[1,2,3,4,5]
res=l1.__iter__()
while True:
try: #异常捕获
print(res.__next__())
except Exception as e: #当报错时结束
break
十三、生成器对象
1.生成器对象
本质还是迭代器对象
只不过生成器是 自己定义 出来的 迭代器对象是 解释器自动提供的
2.生成器对象语法结构
-
函数体代码中有yield关键字 那么函数名加括号不会调用函数体代码 而是产生了一个生成器对象 (也叫迭代器对象)用变量名接收 可以理解为调用了__iter__
def my_iter(): print('嘿嘿嘿') yield res=my_iter() #res内置方法中有__iter__、__next__方法,所以res就是生成器对象 -
打印该变量名出来的是生成器对象 只有用该变量名点__next__()方法才会迭代取值
def my_iter(): print('嘿嘿嘿') yield res=my_iter() print(res) # <generator object my_iter at 0x000001E5D260C890> res.__next__() #结果为:嘿嘿嘿 -
每次执行完__next__() 方法后代码会停在yield位置 等下次执行该方法时才会继续下一个值
def my_iter(): print('嘿嘿嘿') yield print('哈哈哈') yield res=my_iter() res.__next__() # 结果为:嘿嘿嘿 res.__next__() # 结果为:哈哈哈 -
yield类似于返回值
def my_iter(): yield 123 res=my_iter() print(res.__next__()) #结果为:123 ______________________________________ def my_iter(): print('嘿嘿') yield 123 res=my_iter() print(res.__next__()) #结果为:嘿嘿 和 123各一行 -
yield冷门用法:用yield去接收数据
#send(数据值) 将数据值传给yield前面的变量名,然后会自动调用__next__方法 def eat(name,food=None): print(f'{name}正在吃东西') while True: food=yield print(f'{name}正在吃{food}') res=eat('张三') res.__next__() #结果为:张三正在吃东西 res.send('包子') #结果为:张三正在吃包子
3.生成器对象练习题
1.自定义生成器对标range功能(一个参数 两个参数 三个参数 迭代器对象)
def my_range(start_num,end_num=None,step=1):
# 传3个参数时就把+=1的1改为step,不传值默认未1,传几则间隔几
# 传一个参数时:
if not end_num:
end_num=start_num
start_num=0
# 传两个参数时:
while start_num<end_num:
yield start_num
start_num+=step
# for i in my_range(1,10,2):
# print(i)
for i in range(100,50,-1):
print(i)
4.生成器表达式
生成器表达式就是生成器的简化写法!主要就是为了节省内存
#列表生成式:
l1=[i for i in range(5)]
print(l1) #结果为:[0,1,2,3,4]
#生成器表达式(没有元组生成式)
l1=(i for i in range(5))
print(l1) #结果为:<generator object <genexpr> at 0x000002CECB2BE120>
#print(l1.__next__()) #结果为:0
#print(l1.__next__()) #结果为:1 需打印调用多次才可以取完
for i in l1:
print(i) #结果为:把0~4循环打印出来
5.生成器面试题
def add(n, i): # 1.普通函数 返回两个数的和 求和函数
return n + i
def test(): # 3.生成器
for i in range(4): #i为 0 1 2 3
yield i
g = test() # 2.激活生成器 g的值为 0 1 2 3
for n in [1, 10]:
g = (add(n, i) for i in g)
"""
第一次for循环
g = (add(n, i) for i in g) #此时的n为1
第二次for循环
g = (add(n, i) for i in (add(n, i) for i in g)) #此时的n为10
""" #10+0 10+0
res = list(g)
print(res)
#A. res=[10,11,12,13]
#B. res=[11,12,13,14]
#C. res=[20,21,22,23] √
#D. res=[21,22,23,24]
'''不用深入研究 大致知道起始数即可'''
十四、索引取值与迭代取值的差异
| 索引取值 | 迭代取值 | |
|---|---|---|
| 优点 | 可以任意位置任意次数取值 | 支持所有类型的数据取值(无序、有序) |
| 缺点 | 不支持无序类型的数据值(字典、集合) | 只能从前往后依次取值 |
