使用Mongodb爬取中国大学排名并写入数据库
一、实例运用——爬取中国大学排名并写入数据库
1、安装Mongodb
https://www.mongodb.com/download-center/community
请下载对应的系统
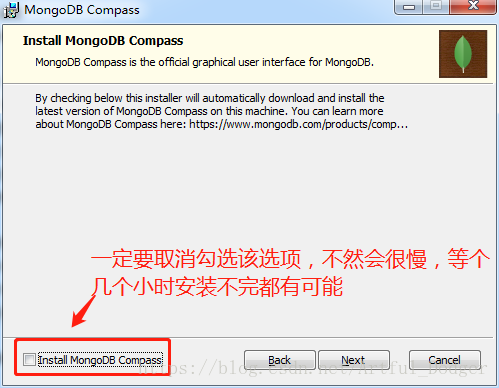
安装过程请不要选择
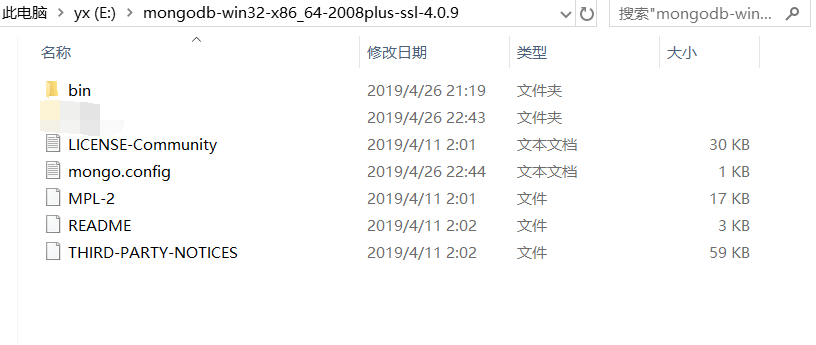
当所有的步骤值完成的时候,找到你的安装的目录,会有以下结果
2、设置环境变量
参考链接 https://www.cnblogs.com/zhoulifeng/p/9429597.html
3、Studio 3T 安装 https://studio3t.com/
解压压缩包到3T的安装目录下,例如 E:\Studio 3T
启动时候请选择 【解压出来的exe(破解版,请联系博主)】
4、数据库的可视化
1.打开Studio 3T
点击左上角的
2、
3、
4.完成后类似这个样子

5、创建数据库并加入数据
import pymongo myclient = pymongo.MongoClient(host='localhost', port=27017) #连接 my_set1 = myclient.University.test #连接University,如果没有则创建一个数据库 my_set2 = myclient.University.test2 #连接University,如果没有则创建一个数据库 dblist = myclient.list_database_names() #所有的数据库名字列表 print(dblist) #查看已有的数据库 my_set1.insert_one({"name":"zhangsan"}) #插入一个数据 my_set2.insert_one({"name":"zhangsan"}) for i in my_set1.find(): print(i) #输出
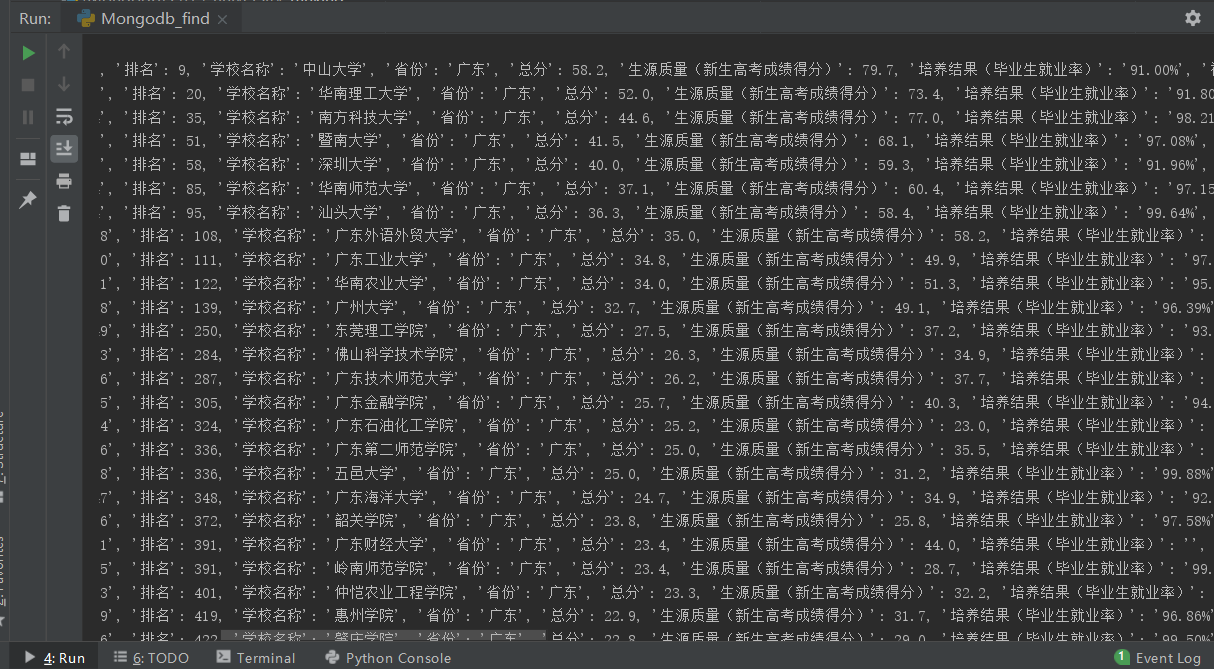
•效果图
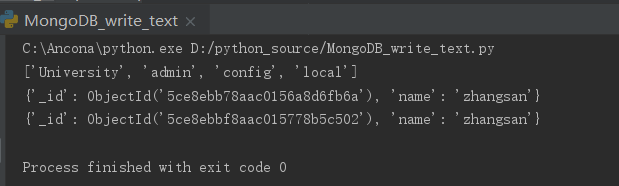
6、爬取过程中到的数据写入数据库
from bs4 import BeautifulSoup import requests import pandas as pd import pymongo def client_Mongodb(port, path): myclient = pymongo.MongoClient(host='localhost', port=port) # 连接 my_set = myclient.path # 连接path,如果没有则创建一个数据库 return my_set def save_mongo(result): myclient = pymongo.MongoClient(host='localhost', port=27017) my_set = myclient.University.ranking try: if my_set.product.insert_one(result): #如果保存成功 pass#print("数据保存成功") except Exception: print("数据保存失败") def save_list_to_Mongodb(lists): my_set = client_Mongodb(27017, 'University.ranking') product = { '排名': lists[0], '学校名称': lists[1], '省份': lists[2], '总分': lists[3], '生源质量(新生高考成绩得分)': lists[4], '培养结果(毕业生就业率': lists[5], '社会声誉(社会捐赠收入·千元': lists[6], '科研规模(论文数量·篇)': lists[7], '科研质量(论文质量·FWCI)': lists[8], '顶尖成果(高被引论文·篇)': lists[9], '顶尖人才(高被引学者·人)': lists[10], '科技服务(企业科研经费·千元': lists[11], '成果转化(技术转让收入·千元)': lists[12], '学生国际化(留学生比例)': lists[13], } # 字典类型数据 save_mongo(product) def getHTMLText(url): try: r = requests.get(url, timeout=10) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "" def filUnivList(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd) == 0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) save_list_to_Mongodb(singleUniv) def main(): url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html' html = getHTMLText(url) soup = BeautifulSoup(html, "html.parser") filUnivList(soup) print("完成") for i in pymongo.MongoClient(host='localhost', port=27017).University.ranking.product.find(): print(i) # 输出 main()
结果:
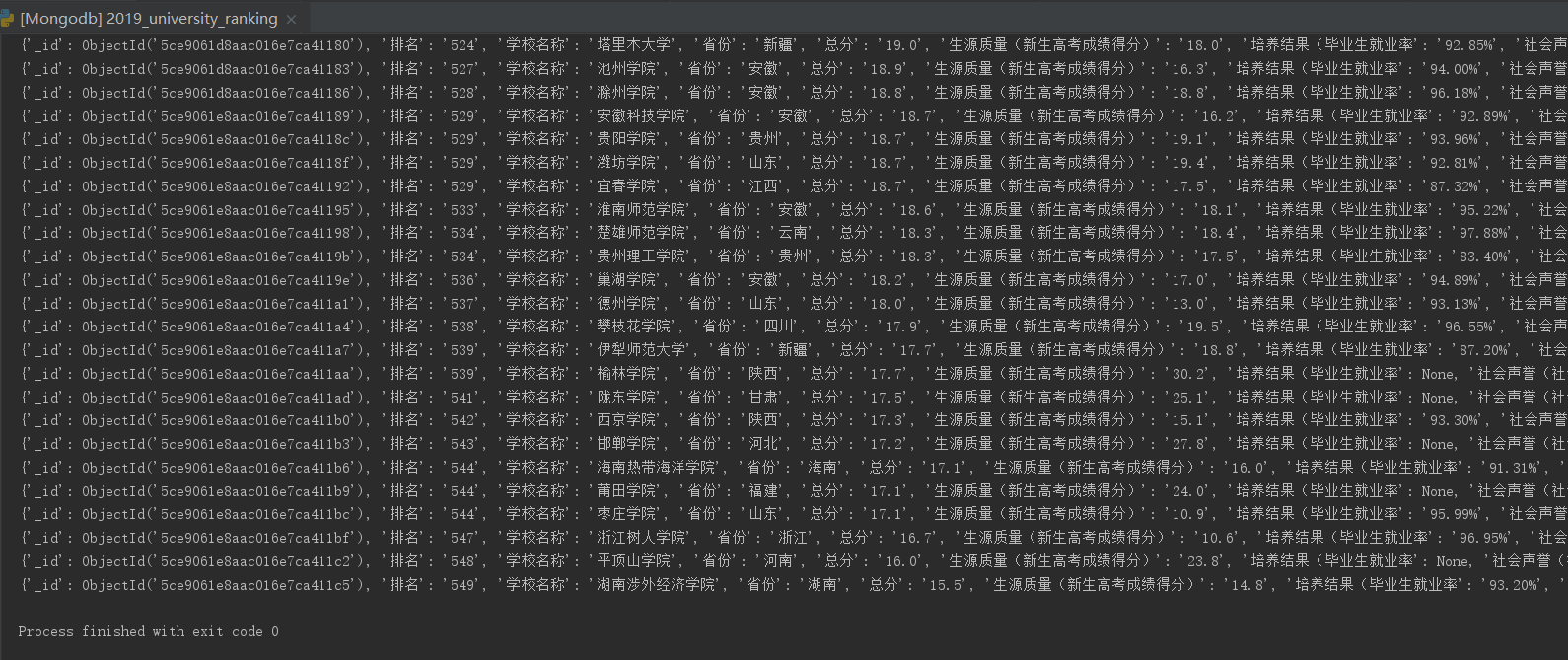
7、csv格式文件写入到Mongodb数据库中
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/10/21 11:31 # @Author : deli Guo # @Site : # @File : csv文件存入mongoDB.py # @Software : PyCharm # 导包 import pymongo import csv # 创建连接MongoDB数据库函数 def connection(): # 1:连接本地MongoDB数据库服务 myclient = pymongo.MongoClient("localhost") # 2:连接本地数据库(guazidata)。没有时会自动创建 db = myclient.University # 3:创建集合 my_set = db.ranking.product_test # 4:看情况是否选择清空 my_set.delete_many({}) return my_set #返回集合 def insertToMongoDB(my_set): # 打开文件guazi.csv with open("E://testcsv.csv", 'r') as csvfile: # 调用csv中的DictReader函数直接获取数据为字典形式 reader = csv.DictReader(csvfile) # 创建一个counts计数一下 看自己一共添加了了多少条数据 counts = 0 for each in reader: # 将数据中需要转换类型的数据转换类型。原本全是字符串(string)。 '''each['index']=int(each['index']) each['价格']=float(each['价格']) each['原价']=float(each['原价']) each['上牌时间']=int(each['上牌时间']) each['表显里程']=float(each['表显里程']) each['排量']=float(each['排量']) each['过户数量']=int(each['过户数量']) ''' my_set.insert_one(each) counts += 1 print('成功添加了'+str(counts)+'条数据 ') # 创建主函数 def main(): my_set = connection() insertToMongoDB(my_set) # 判断是不是调用的main函数。这样以后调用的时候就可以防止不会多次调用 或者函数调用错误 if __name__=='__main__': main()
8、查询某大学排名,查询某省份所有大学,排序X条件的大学
import pymongo myclient = pymongo.MongoClient(host='localhost', port=27017)#连接 mydb = myclient.University #数据库 mycol = mydb.ranking.product_test #集合 myquery = {"学校名称": "广东技术师范大学"} for i in mycol.find(myquery): print(i)
输出结果:{'_id': ObjectId('5cea018c8aac013e249fe115'), '': '286', '排名': '287', '学校名称': '广东技术师范大学', '省份': '广东',..........................省略..}
myquery = {"省份": "广东"}
输出结果: