
面对对象的学习
1、面对对象的总结
•面向对象是一种编程方式,此编程方式的实现是基
于对 类 和 对象 的使用
•类 是一个模板,模板中包装了多个“函数”供使用(可以讲多函数中
公用的变量封装到对象中)
•对象,根据模板创建的实例(即:对象),实例用于调用被包装在
类中的函数
•属性:类中所定义的变量
• 方法:类中所定义的函数
•实例化:通过类创建对象的过程
总结:对象的抽象是类,类的具体化就是对象;也可以说类的实例化是对象,对象是类的实例。
2、特征
(1) 概念:封装是将对象运行时所需的资源封装在程序对象中。简单来说,就是将内容封装起来,以后再去调用被封装的内容。
(2) 调用封装的内容有2种方法:
——通过对象直接调用
——通过self间接调用
•经典代码
# -*- encoding:utf-8 -*- class Student: def __init__(self, name, age): self.name = name self.age = age def detail(self): print(self.name) print(self.age) obj1 = Student('Jack',15) print(obj1.name) print(obj1.age) obj2 = Student('Sahra',13) obj2.detail()
(1) 概念:继承可以使得子类别具有父类别的各种属性和方法,而不需要再次编写相同的代码。在令子类别继承父类别的同时,可以重新定义某些属性,并重写某些方法,即覆盖父类别的原有属性和方法,使其获得与父类别不同的功能。
(2) 多继承
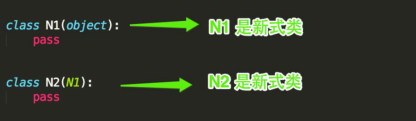
注:Python的类可以继承多个类,而Java和C#中则只能继承一个类
Python的类如果继承了多个类,那么其寻找方法的方式有2种:
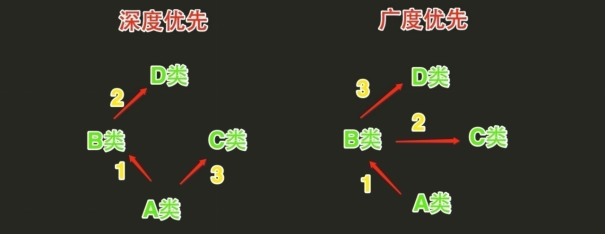
- 当类为经典类时会按照深度优先方式查找

- 当类为新式类时会按照广度优先方式查找
•经典代码
# -*- encoding:utf-8 -*- class Person(object): def talk(self): print("Person can talk.") class Chinese(Person): def talkC(Person): print("Chinese can talk Mandarin.") class Characters(Chinese): def people(self): print("Chinese are clever and diligent.") class American(Person): def talkA(self): print("American can talk English.") C = Characters() A = American() C.talk() A.talkA() C.people()
3. 多态
概念:多态指同一个实体同时具有多种形式,在赋值之后,不同的子类对象调用相同的父类方法,产生的执行结果不同。
•经典代码
# -*- encoding:utf-8 -*-
import abc
class Animal(metaclass=abc.ABCMeta):
@abc.abstractmethod
def talk(self):
pass
class People(Animal):
def talk(self):
print('say hello')
class Dog(Animal):
def talk(self):
print('say wangwang')
class Pig(Animal):
def talk(self):
print('say aoao')
peo = People()
dog = Dog()
pig = Pig()
peo.talk()
dog.talk()
pig.talk()
三、三维向量类
(1) 简述:实现向量的加减法、向量与标量的乘除法。
(2) 代码实现:
# --coding: gb2312-- ''' 三维向量 ''' class vector3: def __init__(self, x_ = 0, y_ = 0, z_ = 0): #构造函数 self.x = x_ self.y = y_ self.z = z_ def __add__(self, obj): #重载+作为加号 return vector3(self.x+obj.x, self.y+obj.y, self.z+obj.z) def __sub__(self, obj): #重载-作为减号 return vector3(self.x-obj.x, self.y-obj.y, self.z-obj.z) def __mul__(self,n): #重载*作为点乘 return vector3(self.x*n, self.y*n, self.z*n) def __truediv__(self, obj): #重载/作为除法 return vector3(self.x/n, self.y/n, self.z/n) def __str__(self): return str(self.x)+','+str(self.y)+','+str(self.z) if __name__ == "__main__": n = int(input("请输入一个标量:")) a,b,c = map(int,input("请输入第一个向量:").split()) v1 = vector3(a,b,c) a,b,c = map(int,input("请输入第二个向量:").split()) v2 = vector3(a,b,c) print("两向量的加法:",v1 + v2) print("两向量的减法:",v1 - v2) print("标量与向量的乘法:",v1 * n) print("标量与向量的除法:",v1 / n)
2. 英文字符串处理
(1) 简述:用户输入一段英文,得到这段英文中所以长度为3的单词,并去除重复的单词。
(2) 代码实现:
方法一: 使用 jieba 库
# -*- encoding:utf-8 -*- ''' 将一段英文中长度为3的单词输出,并去掉重复的单词 ''' import jieba class ProString: Str = "" Dict = {} Ls = [] def __init__(self,string,length = 3): #初始化 self.string = string self.length = length def SignalWord(self): #去除重复的单词 self.words = jieba.lcut(self.string) #jieba分词 for _ in self.words: #与词频算法相似 self.Dict[_] = self.Dict.get(_,0) + 1 del(self.Dict[' ']) #删除空格项 self.Ls = list(self.Dict.keys()) #字典类型转化成列表类型 self.StubbenWord(self.Ls) def StubbenWord(self,Ls): #利用去除重复的单词,得到固定长度的单词 for _ in Ls: if len(_) == self.length: self.Str += _ + ' ' self.printf(self.Str) def printf(self,Str): print("处理后的字符串为:",Str) if __name__ == "__main__": str = input("请输入字符串:") process = ProString(str,3) process.SignalWord()
方法二: 使用 re库 (正则表达式)
# -*- encoding:utf-8 -*- ''' 将一段英文中长度为3的单词输出,并去掉重复的单词 ''' import re class ProStr: a = [] def __init__(self, words, length = 3): self.words = words self.length = length def process(self): word_list = re.split('[\. ]+',self.words) for _ in word_list: if len(_) == self.length: if _ not in self.a: self.a.append(_) else: continue self.printf() def printf(self): print("处理后的字符串为:", end = '') for _ in range(len(self.a)): print(self.a[_],end=' ') if __name__ == "__main__": words = input("请输入字符串:") process = ProStr(words, 3) process.process()

