
DS博客作业03--树
| 这个作业属于哪个班级 | 数据结构--网络2011/2012 |
| ---- | ---- | ---- |
| 这个作业的地址 | DS博客作业03--树 |
| 这个作业的目标 | 学习树结构设计及运算操作 |
| 姓名 | 雷正伟 |
0.PTA得分截图

1.本周学习总结
1.1 二叉树结构
1.1.1 二叉树的2种存储结构
- 二叉树的顺序存储结构

1. 定义:把一个满二叉树自上而下、从左到右顺序编号,依次存放在数组内
2. 类型声明:
typedef ElemType SqBinTree[MaxSize]
通常将下标为0的位置空着,空结点用'#'值表示
3. 性质:
(1)如果i = 0,此结点为根结点,无双亲
(2)如果i > 0,则其双亲结点为(i -1) / 2(int类型整除,舍弃小数的部分)
(3)结点i的左孩子为2i + 1,右孩子为2i + 2
(4)如果i > 0,当i为奇数时,它是双亲结点的左孩子,它的兄弟为i + 1;当i为偶数时,它是双新结点的右孩子,它的兄弟结点为i – 1
(5)深度为k的满二叉树需要长度为2 k-1的数组进行存储
4. 优缺点:读取某个指定的节点的时候效率比较高O(0),但会浪费空间(在非完全二叉树的时候)
- 二叉树的链式存储结构

1. 定义:用一个链表来存储一棵二叉树,二叉树中每一个结点用链表中的一个链结点来存储
2. 类型声明:
typedef struct node
{
ElemType data;
struct node* lchild;
struct node* rchild;
}BTNode;
这种链式存储结构通常简称二叉链;二叉链中通过根结点指针b来唯一标识整个存储结构
3. 优缺点:对于一般的二叉树比较节省存储空间,在二叉链中访问一个结点的孩子很方便,但访问一个结点的双亲结点需要扫描所有节点
4. 二叉树的三叉链表:
有时为了高效地访问一个结点的双亲结点,可在每个结点中再增加一个指向双亲的指针域parent,这样就构成了二叉树的三叉链表

1.1.2 二叉树的构造
- 先序遍历和中序遍历构造二叉树

先序序列的作用是确定一棵二叉树的根结点(其第一个元素即为根结点),中序序列的作用是确定左、右子树的中序序列(包含确定其含的结点个数),进而可以确定左、右子树的先序序列
BTNode* CreateBT1(char* pre, char* in, int n)
//pre存放先序序列,in存放中序序列,n为二叉树的结点个数,算法执行后返回构造的二叉树的根
//结点指针b
{
BTNode* b;
char* p; int k;
if (n <= 0) return NULL;
b = (BTNode*)malloc(sizeof(BTNode));
b->data = *pre;
for (p = in;p < in + n;p++)
if (*P == *pre)
break;
k = p - in;
b->lchild = CreateBT1(pre + 1, in, k);
b->rchild = CreateBT1(pre + k + 1, p + 1, n - k - 1);
return b;
}
- 后序遍历和中序遍历构造二叉树

BTNode* CreateBT2(char* post, char* in, int n)
//post存放后序序列,in存放中序序列,n为二叉树的结点个数,算法执行后返回构造的二叉树的根
//结点指针b
{
BTNode* b;
char* p; int k;
if (n <= 0) return NULL;
r = *(post + n - 1);
b = (BTNode*)malloc(sizeof(BTNode));
b->data = r;
for (p = in;p < in + n;p++)
if (*P == r)
break;
k = p - in;
b->lchild = CreateBT2(post, in, k);
b->rchild = CreateBT2(post + k, p + 1, n - k - 1);
return b;
}
1.1.3 二叉树的遍历
- 先序遍历二叉树
void PreOrder(BTNode* b)
{
if (b != NULL)
{
printf("%c", b->data);
PreOrder(b->lchild);
PreOrder(b->rchild);
}
}
- 中序遍历二叉树
void InOrder(BTNode* b)
{
if (b != NULL)
{
PreOrder(b->lchild);
printf("%c", b->data);
PreOrder(b->rchild);
}
}
- 后序遍历二叉树
void PostOrder(BTNode* b)
{
if (b != NULL)
{
PreOrder(b->lchild);
PreOrder(b->rchild);
printf("%c", b->data);
}
}
- 层次遍历二叉树
void LevelOrder(BTNode* b)
{
BTNode* p;
SqQueue* qu;
InitQueue(qu);
enQueue(qu, b);
while (!QueueEmpty(qu))
{
deQueue(qu, p);
printf("%c", p->data);
if (p->lchild != NULL)
enQueue(qu, p->lchild);
if (p->rchild != NULL)
enQueue(qu, p->rchild);
}
}
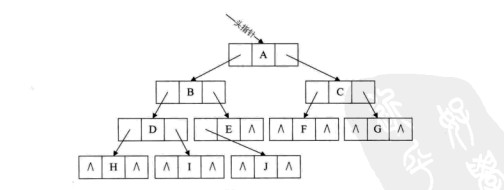
1.1.4 线索二叉树
- 原理:n各结点的二叉链表共有2n个链域,非空链域为n-1个,但其中的空链域却有n+1个
- 类型声明:
typedef struct node
{
ElemType data;
int ltag, rtag; //增加的线索标记
struct node* lchild;
struct node* rchild;
}TBTNode; //线索二叉树中的节点类型
- 中序线索二叉树
TBTNode* pre;//全局变量
void Thread(TBTNode*& p)//对二叉树p进行中序线索化
{
if (p != NULL)
{
Thread(p->lchild);//左子树线索化
if (p->lchild == NULL)//左孩子不存在,进行前驱结点线索化
{
p->lchild = pre;//建立当前结点的前驱结点线索
p->ltag = 1;
}
else//p结点的左子树已线索化
p->ltag = 0;
if (pre->rchild == NULL)//对pre的后继结点线索化
{
pre->rchild = p;//建立前驱结点的后继结点线索
pre->rtag = 1;
}
else
p->rtag = 0;
pre = p;
Thread(p->rchild);//右子树线索化
}
}
TBTNode* CreateThread(TBTNode* b)//中序线索化二叉树
{
TBTNode* root;
root = (TBTNode*)malloc(sizeof(TBTNode));//创建头结点
root->ltag = 0; root->rtag = 1;
root->rchild = b;
if (b == NULL)//空二叉树
root->lchild = root;
else
{
root->lchild = b;
pre = root;//pre是结点p的前驱结点,供加线索用
Thread(b);//中序遍历线索化二叉树
pre->rchild = root;//最后处理,加入指向头结点的线索
pre->rtag = 1;
root->rchild = pre;//头结点右线索化
}
return root;
}
1.1.5 二叉树的应用--表达式树
- 构造表达式树
void InitExpTree(BTree& T, string str)//建表达式树
{
stack<BTree> s;//存放数字
stack<char> op;//存放运算符
op.push('#');
int i = 0;
while (str[i])//树结点赋值
{
if (!In(str[i]))//数字
{
T = new BiTNode;
T->data = str[i++];
T->lchild = T->rchild = NULL;
s.push(T);
}
else
{
switch (Precede(op.top(), str[i]))
{
case'<':
op.push(str[i]);
i++; break;
case'=':
op.pop();
i++; break;
case'>':
T = new BiTNode;
T->data = op.top();
T->rchild = s.top();
s.pop();
T->lchild = s.top();
s.pop();
s.push(T);
op.pop();
break;
}
}
}
while (op.pop() != '#')
{
T = new BiTNode;
T->data = op.top();
op.pop();
T->rchild = s.top();
s.pop();
T->lchild = s.top();
s.pop();s.push(T);
}
}
- 计算表达式树
double EvaluateExTree(BTree T)
{
double a, b;
if (T)
{
if (!T->lchild && !T->rchild)
return T->data - '0';
a = EvaluateExTree(T->lchild);
b = EvaluateExTree(T->rchild);
switch (T->data)
{
case'+': return a + b; break;
case'-': return a - b; break;
case'*': return a * b; break;
case'/':
if (b == 0)
{
cout << "divide 0 erroe!" << endl;
exit(0);
}
return a / b; break;
}
}
}
1.2 多叉树结构
1.2.1 多叉树结构
孩子兄弟链:

孩子兄弟表示法就是既表示出每个结点的第一个孩子结点,也表示出每个结点的下一个兄弟结点。孩子兄弟表示法需要为每个结点设计三个域:一个数据元素域、一个指向该结点的第一个孩子结点的指针域、一个指向该结点的下一个兄弟结点的指针域。
typedef struct TNode
{
ElemType data;//结点的值
struct TNode* hp;//指向兄弟结点
struct TNode* vp;//指向孩子结点
}TSBNode;//孩子兄弟链存储结构中的结点类型
1.2.2 多叉树遍历
void preorder(TR* T)
{
if (T)
{
cout << T->data << " ";
preorder(T->fir);
preorder(T->sib);
}
}
1.3 哈夫曼树
1.3.1 哈夫曼树定义
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
1.3.2 哈夫曼树的结点类型
typedef struct
{
char data;//结点值
double weight;//权重
int parent;//双亲结点
int lchild, rchild;//左右孩子结点
}HTNode;
1.3.2 哈夫曼树构建及哈夫曼编码
- 哈夫曼树构建
void CreateHT(HTNode ht[], int n)
{
int i, k, lnode, rnode;
double min1, min2;
for (i = 1;i < 2 * n - 1;i++)//所有结点的相关域置初值-1
ht[i].parent = ht[i].lchild = ht[i].rchild = -1;
for (i = n;i <= 2 * n - 2;i++)//构造哈夫曼树的n-个分支结点
{
min1 = min2 = 32767;//lnode和rnode为最小权重的两个结点位置
lnode = rnode = -1;
for(k=0;k<=i-1;k++)//再ht[0...i-1]中找权值最小的两个结点
if (ht[k].parent==-1)//只在尚未构造二叉树的结点中查找
{
if (ht[k].weight < min1)
{
min2 = min1; rnode = lnode;
min1 = ht[k].weight;
lnode = k;
}
else if (ht[k].weight < min2)
{
min2 = ht[k].weight;
rnode = k;
}
}
ht[i].weight = ht[lnode].weight + ht[rnode].weight;
ht[i].lchild = lnode;
ht[i].rchild = rnode;//ht[i]作为双亲结点
ht[lnode].parent = i;
ht[rnode].parent = i;
}
}
- 哈夫曼编码
void CreateHCode(HTNode ht[], HCode hcd[], int n)
{
int i, j, k;
HCode hc;
for (i = 0;i < n;i++)
{
hc.start = n;
k = i;
j = ht[i].parent;
while (j != -1)//循环至根结点
{
if (ht[j].lchild == k)
hc.cd[hc.start--] == '1';//当前结点时的双亲结点的左孩子
else
hc.cd[hc.start--] == '0';//当前结点时的双亲结点的右孩子
k = j; j = ht[j].parent;
}
hc.start++;//start指向哈夫曼编码最开始字符
hcd[i] = hc;
}
}
1.4 并查集
当给出两个元素的一个无序对(a,b)时,需要快速“合并”a和b分别所在的集合,这期间需要反复“查找”某元素所在的集合,“并”,“查”,“集”由此而来。
在这种数据类型当中,n个不同的元素被分为若干组,每组是一个集合,这种集合叫做分离集合,称之为并查集。
- 并查集的结构体
typedef struct
{
int data;//结点对应人的编号
int rank;//结点对应秩
int parent;//结点对应双亲下标
}UFSTree;//并查集树的结点类型
void MakeSet(UFSTree t[], int n)//初始化并查集树
{
int i;
for (i = 0;i < n;i++)
{
t[i].data = i;//数据为该人的编号
t[i].rank = 0;//秩初始化为0
t[i].parent = i;//双亲初始化为自己
}
}
- 并查集的查找
int FindSet(UFSTree t[], int x)//在并查集中查找集合编号
{
if (x != t[x].parent)//双亲不是自己
return (FindSet(t, t[x].parent));//递归在双亲中找x
else
return x;//双亲是自己,返回x
}
- 并查集的合并
void UnionSet(UFSTree t[], int x, int y)//两个元素各自所属的集合的合并
{//将x和y所在的子树合并
x = FindSet(t, x);
y = FindSet(t, y);//查找x和y所在的分离集合树的编号
if (t[x].rank > t[y].rank)//y结点的秩小于x结点的秩
t[y].parent = x;//将y连接到x结点上,x作为y的双亲结点
else
{
t[x].parent = y;//将x连接到y结点上,y作为x的双亲结点
if (t[x].parent == t[y].parent)//x和y的秩相同
t[y].rank++;//y的秩加一
}
}
1.5谈谈你对树的认识及学习体会
前面都在学习线性结构,而树是第一次接触的非线性结构,在数的学习中,学到了树的三种遍历方式,及树、二叉树的构造、一些基本运算,也掌握了哈夫曼树和哈夫曼编码、并查集的知识
2.PTA实验作业
2.1输出二叉树每层节点
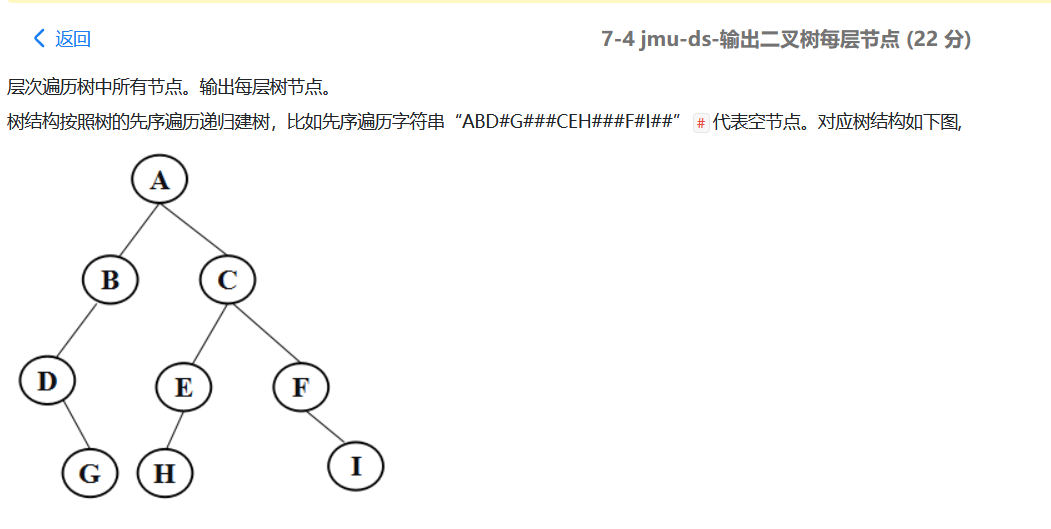
2.1.1 解题思路及伪代码
{
定义变量层数level和flag判断是否为第一层结点
BTree node存放遍历中途结点的孩子结点, lastNode判断是否找到这一层的最后一个结点
node = lastNode = bt;
用队列来存放结点
若二叉树不为空,则出队
若二叉树为空 NULL
while (!qtree.empty())//队列不空
{
若找到这一层的最后一个结点
则层层递增
取队尾元素
}
取队首元素并使左右孩子入队
}
}
2.1.2 总结解题所用的知识点
- 运用了queue.函数和先序遍历
2.2 目录树

2.2.1 解题思路及伪代码
void DealStr(string str, BTree bt)
{
while(str.size()>0)
{
查找字符串中是否有’\’,并记录下位置pos
if(没有)
说明是文件,则进入InsertFile的函数
else
说明是目录,则进入Insertcatalog的函数里
bt=bt->catalog;
同时bt要跳到下一个目录的第一个子目录去,因为刚刚Insertcatalog的函数是插到bt->catalog里面去
while(bt!NULL&&bt->name!=name)
bt=bt->Brother;//找到刚刚插入的目录,然后下一步开始建立它的子目录
str.erase(0, pos + 1);把刚插进去的目录从字符串中去掉
}
}
2.2.2 总结解题所用的知识点
- 运用孩子兄弟存储结构建树
- 注意根目录与子目录的插入位置关系
3.阅读代码
3.1 题目及解题代码
剑指 Offer 26. 树的子结构

class Solution:
def isSubStructure(self, A: TreeNode, B: TreeNode) -> bool:
def recur(A, B):
if not B: return True
if not A or A.val != B.val: return False
return recur(A.left, B.left) and recur(A.right, B.right)
return bool(A and B) and (recur(A, B) or self.isSubStructure(A.left, B) or self.isSubStructure(A.right, B))
3.2 该题的设计思路及伪代码
先序遍历树A中的每个节点nA;(对应函数 isSubStructure(A, B))
判断树A中以nA为根节点的子树是否包含树B。(对应函数 recur(A, B))
recur(A, B) 函数:
{
终止条件:
当节点B为空:说明树B已匹配完成(越过叶子节点),因此返回true ;
当节点A为空:说明已经越过树A叶子节点,即匹配失败,返回false ;
当节点A和B的值不同:说明匹配失败,返回false ;
返回值:
判断 AAA 和 BBB 的左子节点是否相等,即 recur(A.left, B.left) ;
判断 AAA 和 BBB 的右子节点是否相等,即 recur(A.right, B.right) ;
}
isSubStructure(A, B) 函数:
{
特例处理:当树A为空或树B为空时,直接返回false ;
返回值: 若树B是树A的子结构,则必满足以下三种情况之一,因此用或 || 连接;
以 节点A为根节点的子树包含树B,对应 recur(A, B);
树B是树A左子树的子结构,对应isSubStructure(A.left, B);
树B是树A右子树的子结构,对应isSubStructure(A.right, B);
}
3.3 分析该题目解题优势及难点
- 递归比较难写
- 小心空树的情况,不然容易崩溃
- 使用bool类型,更加方便简洁,不需要设置什么flag之类的东西,直接返回输出即可
