深度学习手动实现线性回归
导包
import torch
import matplotlib.pyplot as plt
设置学习率
learning_rate = 0.01
1.准备数据:y = 3 * x + 0.8
x = torch.rand([500, 1])
y_true = 3 * x + 0.8
w = torch.rand([1, 1], requires_grad=True)
b = torch.tensor(0, requires_grad=True, dtype=torch.float32)
2.通过循环,反向传播,更新参数
for i in range(500):
### 通过模型计算y_predict
y_predict = torch.matmul(x, w) + b
### 计算loss
loss = (y_true - y_predict).pow(2).mean()
#### 调用x.grad获取梯度,但是x.grad会累加梯度,所以在调用之前要先置为0
if w.grad is not None:
w.grad.data.zero_()
if b.grad is not None:
b.grad.data.zero_()
loss.backward() # 反向传播
#### require_grad=True时,tensor.data仅仅是获取tensor中的数据
#### 梯度更行的方式:w = w - learning_rate * 梯度
w.data = w.data - learning_rate * w.grad
b.data = b.data - learning_rate * b.grad
3.创建图形
创建图形对象, figsize:指定画布的大小(宽度,高度)
plt.figure(figsize=(20, 8))
创建散点图
reshape(-1):numpy会根据剩下的维度计算出数组的另外一个shape属性值
plt.scatter(x.numpy().reshape(-1), y_true.numpy().reshape(-1))
y_predict = torch.matmul(x, w) + b
绘制线条
y_predict的require_grad=True不能够直接转换,需要使用tensor.detach().numpy()
plt.plot(x.numpy().reshape(-1), y_predict.detach().numpy().reshape(-1), c="r")
展示图形
plt.show()
4.展示
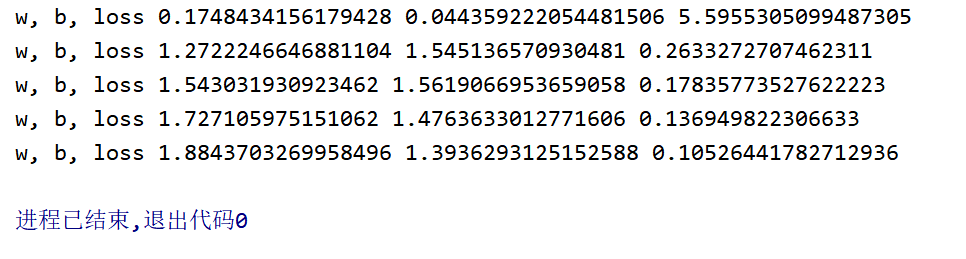
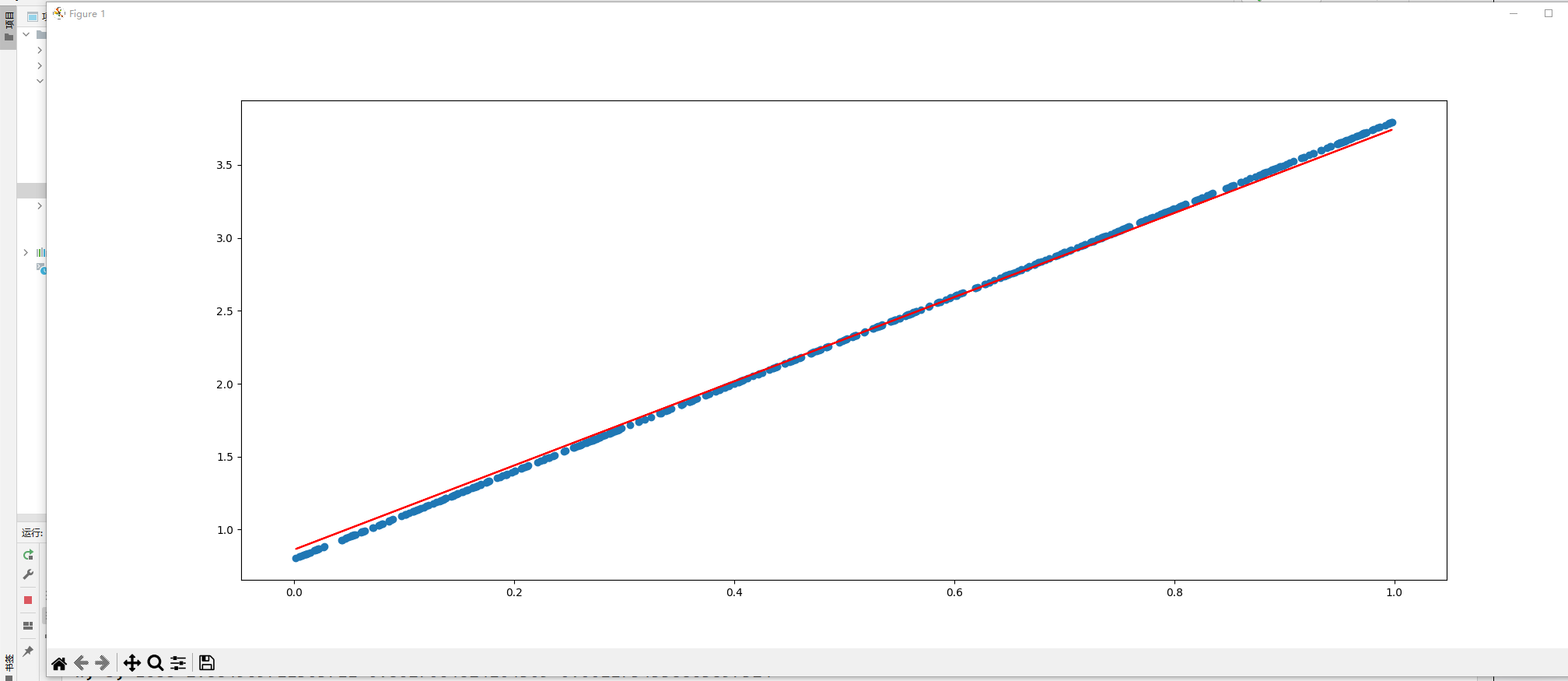
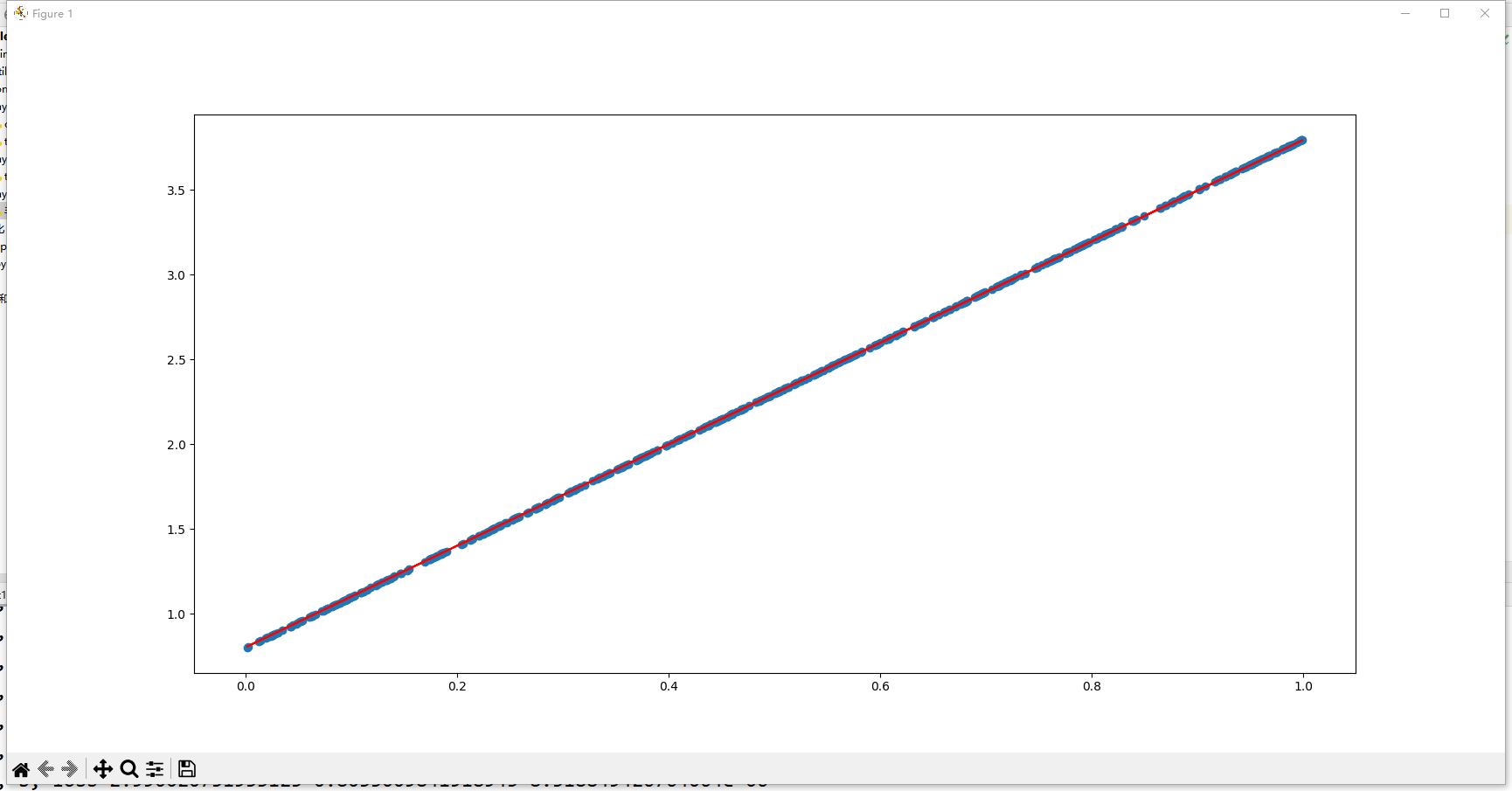
我们指定每100行显示w,b,loss的数据,图中散点图表示目标值y_true,直线表示预测值y_predict
if i % 100 == 0:
print("w, b, loss", w.item(), b.item(), loss.item())
当数据量为500时:
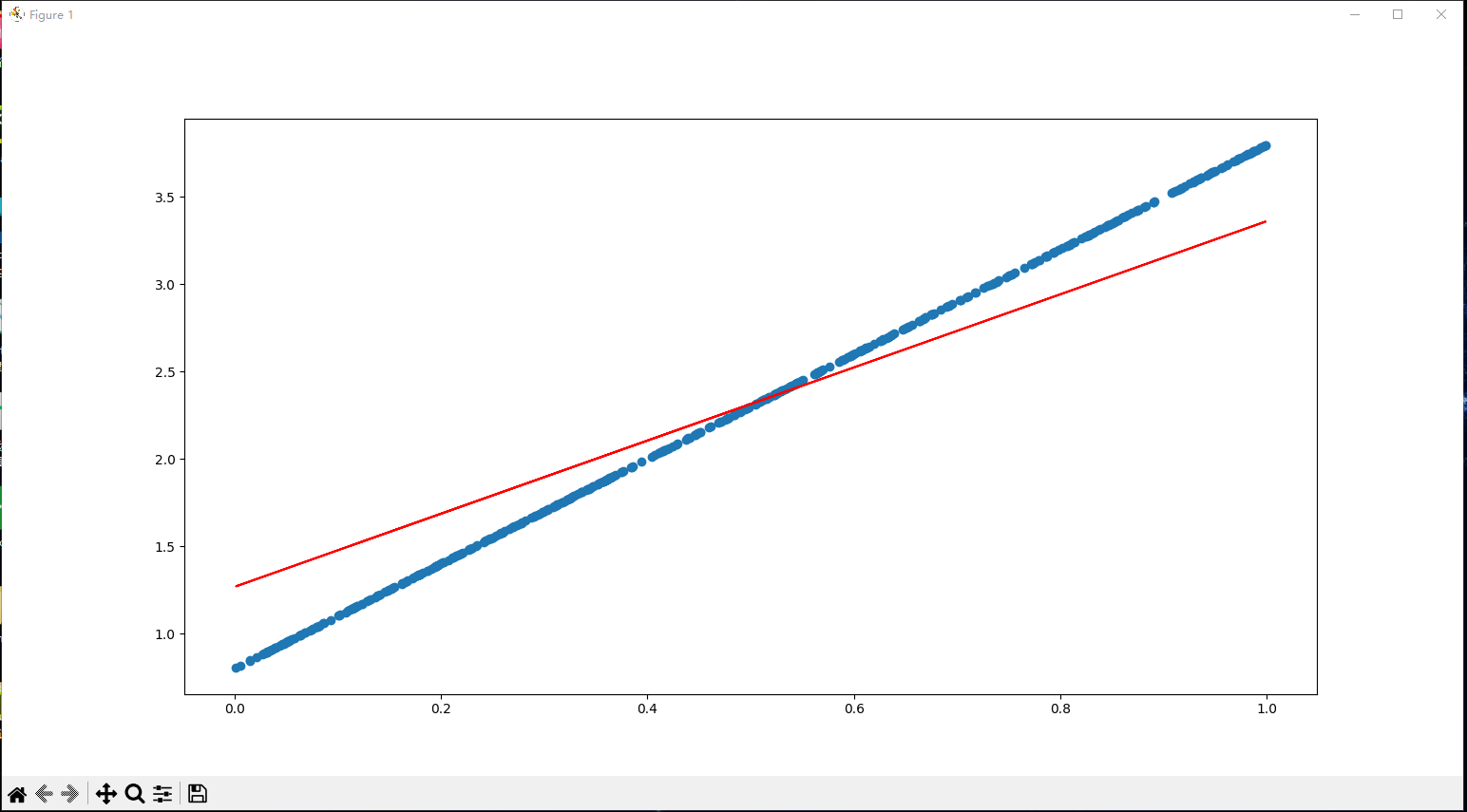
当数据量为2000时:

当数据量为4000时:

5.总结
可见,当数据量越大时,w, b就越接近目标值,损失函数loss就越低
6.代码
import torch
import matplotlib.pyplot as plt
learning_rate = 0.01
# 1.准备数据
# y = 3 * x + 0.8
x = torch.rand([500, 1])
y_true = 3 * x + 0.8
w = torch.rand([1, 1], requires_grad=True)
b = torch.tensor(0, requires_grad=True, dtype=torch.float32)
# 2.通过循环,反向传播,更新参数
for i in range(500):
# 3.通过模型计算y_predict
y_predict = torch.matmul(x, w) + b
# 4.计算loss
loss = (y_true - y_predict).pow(2).mean()
# 调用x.grad获取梯度,但是x.grad会累加梯度,所以在调用之前要先置为0
if w.grad is not None:
w.grad.data.zero_()
if b.grad is not None:
b.grad.data.zero_()
loss.backward() # 反向传播
# require_grad=True时,tensor.data仅仅是获取tensor中的数据
# 梯度更行的方式:w = w - learning_rate * 梯度
w.data = w.data - learning_rate * w.grad
b.data = b.data - learning_rate * b.grad
if i % 100 == 0:
print("w, b, loss", w.item(), b.item(), loss.item())
# 创建图形对象, figsize:指定画布的大小(宽度,高度)
plt.figure(figsize=(20, 8))
# 创建散点图
# reshape(-1):numpy会根据剩下的维度计算出数组的另外一个shape属性值
plt.scatter(x.numpy().reshape(-1), y_true.numpy().reshape(-1))
y_predict = torch.matmul(x, w) + b
# 绘制线条
# y_predict的require_grad=True不能够直接转换,需要使用tensor.detach().numpy()
plt.plot(x.numpy().reshape(-1), y_predict.detach().numpy().reshape(-1), c="r")
# 展示图形
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号