AC自动机
版权声明:本文为CSDN博主「bestsort」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/bestsort/article/details/82947639
出自bestsort.cn
文章非博主原创
要学AC自动机需要自备两个前置技能:KMP和trie树(其实个人感觉不会kmp也行,失配指针的概念并不难)
其中,KMP是用于一对一的字符串匹配,而trie虽然能用于多模式匹配,但是每次匹配失败都需要进行回溯,如果模式串很长的话会很浪费时间,所以AC自动机应运而生,如同Manacher一样,AC自动机利用某些操作阻止了模式串匹配阶段的回溯,将时间复杂度优化到了O(n) (n)为文本串长度
下面开始用图学习ac自动机吧(个人比较喜欢放图,能用一张图解决的绝不叨叨)
首先给定模式串"ash","shex","bcd","sha",然后我们根据模式串建立如下trie树:
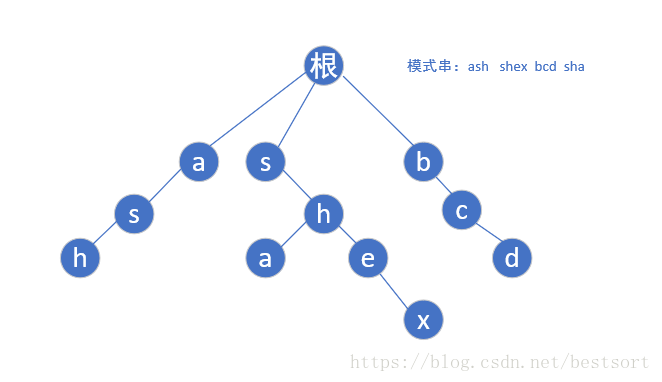
然后我们再了解下一步:
ac自动机,就是在tire树的基础上,增加一个fail指针,如果当前点匹配失败,则将指针转移到fail指针指向的地方,这样就不用回溯,而可以路匹配下去了.(当前模式串后缀和fail指针指向的模式串部分前缀相同,如abce和bcd,我们找到c发现下一个要找的不是e,就跳到bcd中的c处,看看此处的下一个字符(d)是不是应该找的那一个)
一般,fail指针的构建都是用bfs实现的
首先每个模式串的首字母肯定是指向根节点的(一个字母你瞎指什么指,指了也是头字母有什么用嘛)
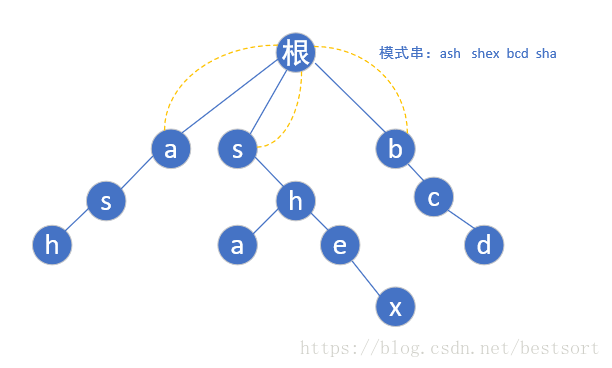
现在第一层bfs遍历完了,开始第二层
(根节点为第0层)第二层a的子节点为s,但是我们还是要从a-z遍历,如果不存在这个子节点我们就让他指向根节点(如下图红色的a)
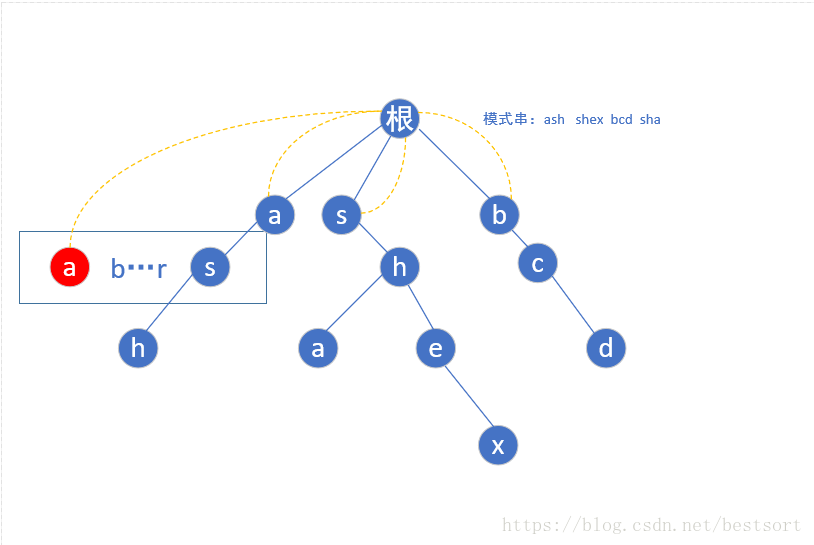
当我们遍历到s的时候,由于存在s这个节点,我们就让他的fail指针指向他父亲节点(a)的fail指针指向的那个节点(根)的具有相同字母的子节点(第一层的s),也就是这样
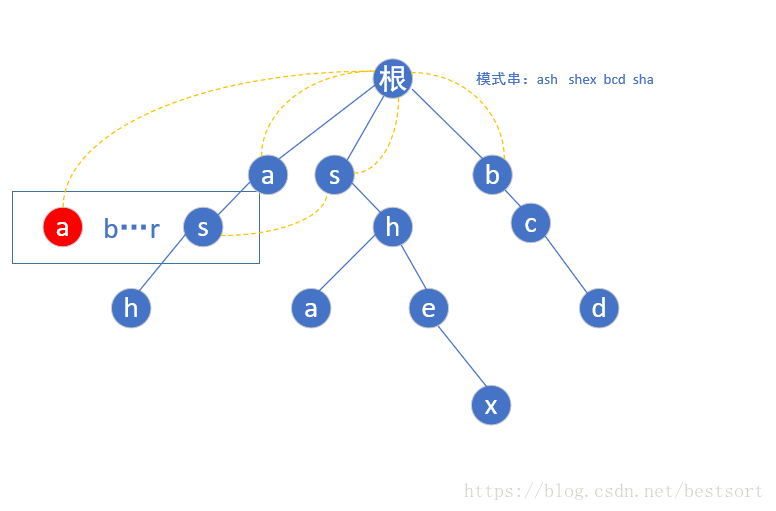
按照相同规律构建第二层后,到了第三层的h点,还是按照上面的规则,我们找到h的父亲节点(s)fail指针指向的那个位置(第一层的s)然后指向它所指向的相同字母根->s->h的这个链的h节点,如下图
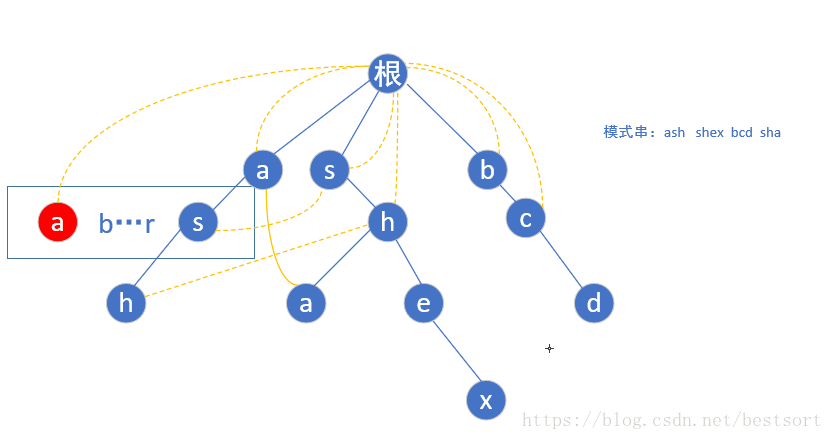
完全构造好后的树

然后匹配就很简单了,这里以ashe为例
我们先用ash匹配,到h了发现:诶这里ash是一个完整的模式串,好的ans++,然后找下一个e,可是ash后面没字母了啊,我们就跳到hfail指针指向的那个h继续找,还是没有?再跳,结果当前的h指向的是根节点,又从根节点找,然而还是没有找到e,程序END
过程如下图
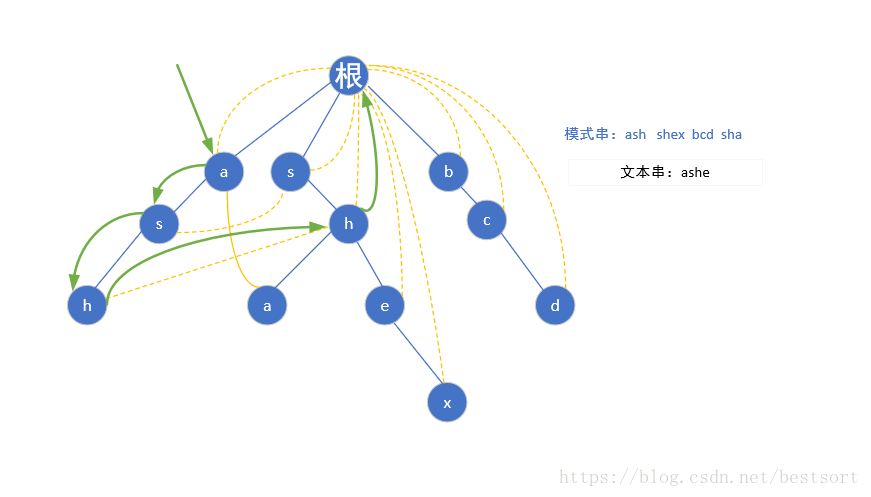
喜闻乐见模板系列
#include <queue>
#include <cstdlib>
#include <cmath>
#include <cstdio>
#include <string>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long ll;
const int maxn = 2*1e6+9;
int trie[maxn][26]; //字典树
int cntword[maxn]; //记录该单词出现次数
int fail[maxn]; //失败时的回溯指针
int cnt = 0;
void insertWords(string s){
int root = 0;
for(int i=0;i<s.size();i++){
int next = s[i] - 'a';
if(!trie[root][next])
trie[root][next] = ++cnt;
root = trie[root][next];
}
cntword[root]++; //当前节点单词数+1
}
void getFail(){
queue <int>q;
for(int i=0;i<26;i++){ //将第二层所有出现了的字母扔进队列
if(trie[0][i]){
fail[trie[0][i]] = 0;
q.push(trie[0][i]);
}
}
//fail[now] ->当前节点now的失败指针指向的地方
////tire[now][i] -> 下一个字母为i+'a'的节点的下标为tire[now][i]
while(!q.empty()){
int now = q.front();
q.pop();
for(int i=0;i<26;i++){ //查询26个字母
if(trie[now][i]){
//如果有这个子节点为字母i+'a',则
//让这个节点的失败指针指向(((他父亲节点)的失败指针所指向的那个节点)的下一个节点)
//有点绕,为了方便理解特意加了括号
fail[trie[now][i]] = trie[fail[now]][i];
q.push(trie[now][i]);
}
else//否则就让当前节点的这个子节点
//指向当前节点fail指针的这个子节点
trie[now][i] = trie[fail[now]][i];
}
}
}
int query(string s){
int now = 0,ans = 0;
for(int i=0;i<s.size();i++){ //遍历文本串
now = trie[now][s[i]-'a']; //从s[i]点开始寻找
for(int j=now;j && cntword[j]!=-1;j=fail[j]){
//一直向下寻找,直到匹配失败(失败指针指向根或者当前节点已找过).
ans += cntword[j];
cntword[j] = -1; //将遍历国后的节点标记,防止重复计算
}
}
return ans;
}
int main() {
int n;
string s;
cin >> n;
for(int i=0;i<n;i++){
cin >> s ;
insertWords(s);
}
fail[0] = 0;
getFail();
cin >> s ;
cout << query(s) << endl;
return 0;
}
作者: liuzitong
出处:http://www.cnblogs.com/lztzs/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
