PCIe网卡驱动实现分析(四)--- i350网卡驱动硬件原理和软件实现
i350网卡驱动硬件原理和软件实现
1、硬件原理
2、驱动软件
2.1 初始化
2.1.1 收发包队列数据结构创建
2.1.2 中断初始化
2.2 数据发送流程
2.3 数据接收流程
一、硬件原理
如下图所示,I350网卡是一个pcie设备,通过pcie接口连接到cpu小系统;i350中有4个LAN口,每个LAN口是一个pcie function,每个LAN外接可选择Serdes或者PHY;每个LAN内部有4个发包队列和4个收包队列,i350内部有DMA控制器,软件驱动可在内存分别创建4个发包队列和4个收包队列,通过设置寄存器,可将内存的队列和i350内部的队列建立一一对应关系,两者之间的数据搬移由DMA完成,并且通过设置寄存器,每个队列可绑定一个msix中断,DMA完成数据搬移后,通过对应中断通知cpu该队列的数据搬移完成;
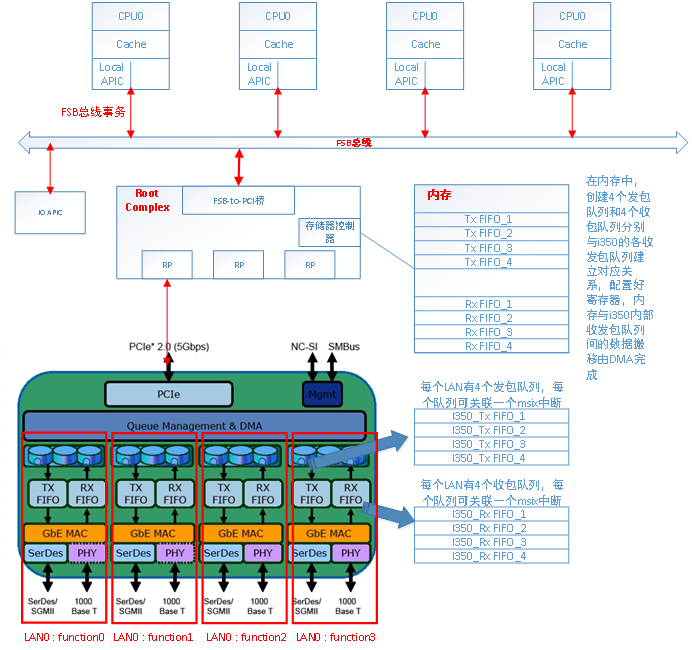
二、驱动软件
pcie设备驱动基于linux的设备驱动总线架构,内核在PCIe设备枚举过程中,已经创建i350设备对应的pci_dev,用pci_register_driver(&igb_driver)函数将i350的驱动注册到内核,igb_driver结构体里面填入i350的供应商ID和设备ID,就会和i350的设备结构体pci_dev匹配,从而调用i350驱动的probe函数开始初始化。
2.1 初始化
初始化流程中,主要做了如下工作:
使能pcie内存访问、设置DMA地址掩码、映射获取BAR0空间的基地址;
初始化MAC、PHY等参数;
创建收发包队列;
中断初始化;
2.1.1 收发包队列数据结构创建
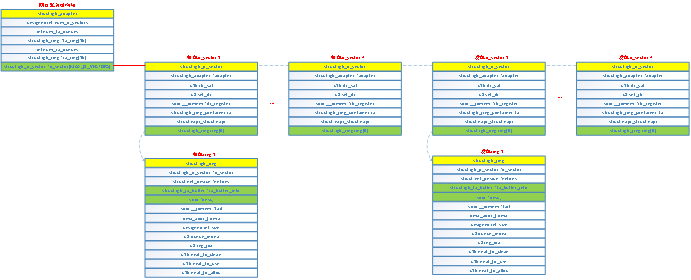
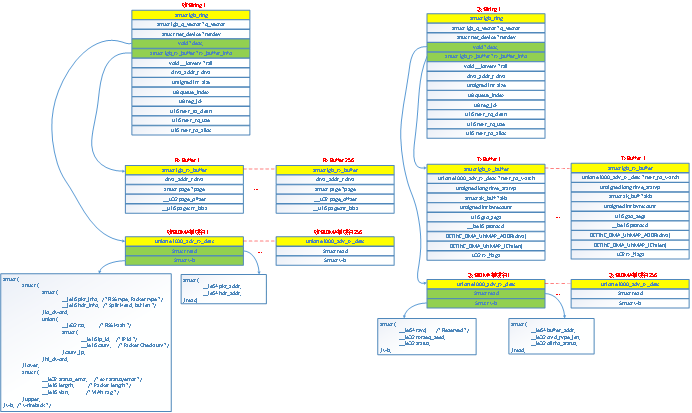
I350内部有4个收包队列和4个发包队列,队列需要管理的内容包括数据包buffer、DMA以及中断;如上图所示,驱动程序维护4个收包队列数据结构igb_q_vector和4个发包队列数据结构igb_q_vector,每个igb_q_vector和i350内部的队列一一对应,igb_q_vector的结构成员包含了数据包buffer、DMA描述符以及中断等信息;
发包队列数据结构igb_q_vector:
发包队列中维护了256个发包buffer(struct igb_tx_buffer),这256个发包buffer以循环队列的数据结构进行管理,并且每个发包buffer对应一个DMA描述符(union e1000_adv_tx_desc),DMA描述符中保存了发包buffer中数据的DMA总线地址和数据长度;256个DMA描述符也组织成循环队列的结构,并且放在一片连续的物理内存中(使用dma_alloc_coherent接口申请的物理地址连续的内存),将DMA描述符的首地址写到i350的TDBAL和TDBAH寄存器,将256个DMA描述符内存的总长度写到TDLEN寄存器,i350内部有两个指示可用描述符的寄存器TDH和TDT,通过修改这2个寄存器,就可以通知i350有哪些描述符可用,那么i350就会将内存中可用的描述符加载到i350内部。
/* * 创建发包队列igb_q_vector,其中队列成员ring里面保存了发包buffer和DMA描述符 * 分配256个发包buffer * 分配256个物理地址连续的DMA描述符 * 将管理队列的变量清0 * 将DMA描述符内存的信息写到对应寄存器告知i350 */ /* 创建发包队列igb_q_vector,其中队列成员ring里面保存了发包buffer和DMA描述符 */ struct igb_q_vector *q_vector; struct igb_ring *ring; size = sizeof(struct igb_q_vector) + (sizeof(struct igb_ring) * ring_count); q_vector = kzalloc(size, GFP_KERNEL); /* 分配256个发包buffer */ size = sizeof(struct igb_tx_buffer) * tx_ring->count; tx_ring->tx_buffer_info = vmalloc(size); /* 分配256个物理地址连续no cache的DMA描述符 */ tx_ring->size = tx_ring->count * sizeof(union e1000_adv_tx_desc); tx_ring->size = ALIGN(tx_ring->size, 4096); tx_ring->desc = dma_alloc_coherent(dev, tx_ring->size, &tx_ring->dma, GFP_KERNEL); /* 将管理队列的变量清0 */ tx_ring->next_to_use = 0; tx_ring->next_to_clean = 0; /* 将DMA描述符内存的信息写到对应寄存器告知i350 */ wr32(E1000_TDLEN(reg_idx), ring->count * sizeof(union e1000_adv_tx_desc)); wr32(E1000_TDBAL(reg_idx), tdba & 0x00000000ffffffffULL); wr32(E1000_TDBAH(reg_idx), tdba >> 32); ring->tail = adapter->io_addr + E1000_TDT(reg_idx); wr32(E1000_TDH(reg_idx), 0); writel(0, ring->tail);
收包队列数据结构igb_q_vector:
和发包队列一样,收包队列中也中维护了256个收包buffer(struct igb_rx_buffer),这256个收包buffer以循环队列的数据结构进行管理,并且每个收包buffer对应一个DMA描述符(union e1000_adv_rx_desc),DMA描述符中保存了收包buffer中数据的DMA总线地址和数据长度;256个DMA描述符也组织成循环队列的结构,并且放在一片连续的物理内存中(使用dma_alloc_coherent接口申请的物理地址连续的内存),将DMA描述符的首地址写到i350的RDBAL和RDBAH寄存器,将256个DMA描述符内存的总长度写到RDLEN寄存器,i350内部有两个指示可用描述符的寄存器RDH和RDT,通过修改这2个寄存器,就可以通知i350有哪些描述符可用,那么i350就会将内存中可用的描述符加载到i350内部。
并且,对于每个收包buffer,需要预先分配数据包内存,并且把数据包内存填充到DMA描述符,然后通过RDT寄存器通知i350将收包描述符加载到i350内部,这样数据包到达i350内部收包队列后,i350就可以使用DMA描述符将数据包拷贝到内存对应队列的收包buffer中。
/* * 创建收包队列igb_q_vector,其中队列成员ring里面保存了收包buffer和DMA描述符 * 分配256个收包buffer * 分配256个物理地址连续no cache的DMA描述符 * 将管理队列的变量清0 * 将DMA描述符内存的信息写到对应寄存器告知i350 * 给每个收包buffer的数据包缓存分配page,并且填充DMA描述符 * 更新循环队列管理变量,将next_to_use的值写入RDT寄存器,告知i350加载新的收包DMA描述符 */ /* 创建收包队列igb_q_vector,其中队列成员ring里面保存了收包buffer和DMA描述符 */ struct igb_q_vector *q_vector; struct igb_ring *ring; size = sizeof(struct igb_q_vector) + (sizeof(struct igb_ring) * ring_count); q_vector = kzalloc(size, GFP_KERNEL); /* 分配256个收包buffer */ size = sizeof(struct igb_rx_buffer) * rx_ring->count; rx_ring->rx_buffer_info = vmalloc(size); /* 分配256个物理地址连续no cache的DMA描述符 */ rx_ring->size = rx_ring->count * sizeof(union e1000_adv_rx_desc); rx_ring->size = ALIGN(rx_ring->size, 4096); rx_ring->desc = dma_alloc_coherent(dev, rx_ring->size, &rx_ring->dma, GFP_KERNEL); /* 将管理队列的变量清0 */ rx_ring->next_to_alloc = 0; rx_ring->next_to_clean = 0; rx_ring->next_to_use = 0; /* 将DMA描述符内存的信息写到对应寄存器告知i350 */ wr32(E1000_RDBAL(reg_idx), rdba & 0x00000000ffffffffULL); wr32(E1000_RDBAH(reg_idx), rdba >> 32); wr32(E1000_RDLEN(reg_idx), ring->count * sizeof(union e1000_adv_rx_desc)); ring->tail = adapter->io_addr + E1000_RDT(reg_idx); wr32(E1000_RDH(reg_idx), 0); writel(0, ring->tail); /* 给每个收包buffer的数据包缓存分配page,并且填充DMA描述符 */ igb_alloc_mapped_page(struct igb_ring *rx_ring, struct igb_rx_buffer *bi) struct page *page = bi->page; dma_addr_t dma; page = dev_alloc_pages(igb_rx_pg_order(rx_ring)); dma = dma_map_page_attrs(rx_ring->dev, page, 0, igb_rx_pg_size(rx_ring), DMA_FROM_DEVICE, IGB_RX_DMA_ATTR); bi->dma = dma; bi->page = page; dma_sync_single_range_for_device(rx_ring->dev, bi->dma, bi->page_offset, bufsz, DMA_FROM_DEVICE); rx_desc->read.pkt_addr = cpu_to_le64(bi->dma + bi->page_offset); /* 更新循环队列管理变量,将next_to_use的值写入RDT寄存器,告知i350加载新的收包DMA描述符 */ i += rx_ring->count; rx_ring->next_to_use = i; rx_ring->next_to_alloc = i; wmb(); writel(i, rx_ring->tail);
2.1.2 中断初始化
I350驱动使用PCIE的MSIX中断,共注册了9个MSIX中断,其中1个用于link状态变化的通知,另外8个是收发包队列绑定的中断,当某个队列用DMA完成数据搬移后,就会上报对应的MSIX中断;并且每个收发包队列还注册一个NAPI软中断处理函数,这个软中断函数用于完成具体收发包中断的任务,MSIX中断是硬中断,在MSIX中断回调函数中仅负责调度对应队列的NAPI处理函数。
中断初始化涉及的内容主要包括:
调用pci_enable_msix_range函数配置MSI-X capability structure,创建9个MSIX中断; 合理设置中断相关的寄存器,EIMS(Interrupt Mask Set/Read)寄存器:每个bit对应一个MSIX中断,置1时,enable对应中断,EIMC(Interrupt Mask Clear)寄存器:每个bit对应一个MSIX中断,置1时,disable对应中断,EIAM(Interrupt Ack Auto Clear Mask)寄存器:每个bit对应一个MSIX中断,置1,中断产生时会自动将EIMS对应bit清0以屏蔽该中断,EICR(Interrupt Cause Read)寄存器:每个bit对应一个MSIX中断,中断产生时,对应bit置1,EIAC(Interrupt Auto Clear)寄存器:每个bit对应一个MSIX中断,置1时,不使用EICR寄存器,也就是中断产生时无法通过读取EICR寄存器获取是哪个中断产生,IMS(Interrupt Mask Set)寄存器:置1时,enable对应中断,这些中断不在EIMS寄存器中,比如bit2(link status change中断)、bit28(NIC DMA out of sync)、bit30(Device Reset Asserted),IMC(Interrupt Mask Clear)寄存器:置1时,disable对应中断,相对IMS寄存器,IAM(Interrupt Acknowledge Auto Mask)寄存器:置1,中断产生时会自动IAM寄存器的值拷贝到IMC以屏蔽中断,功能与EIAM寄存器类似;
对于收发包队列中断,由于每个中断都用irq_reqiest注册了一个回调函数,不需要EICR寄存器,因此,初始化时,将EIMS、EIAM、EIAC相应中断bit都置1,这样中断产生时,会自动将EIMS相应bit清0屏蔽中断,然后在完成处理任务后,将EIMS置1重新enable中断,这样省去一次PCIE读TLP的开销;对于eims_other中断,由于该中断绑定了3个事件,中断回调时,需要通过ICR寄存器判断是哪个事件产生中断,因此,初始化时,将IMC和IAM清0,IMS对应bit置1,这样,中断产生时,通过读ICR寄存器判断是哪个事件产生中断;
通过设置E1000_IVAR_MISC寄存器,将eims_other绑定到msix vector,那么事件发生后,就会触发对应msix中断;
通过设置E1000_IVAR0寄存器,将各收发包队列绑定到对应的msix vector,那么收发包队列进行数据包搬移后,就会触发对应的msix中断;
给每个收发包队列注册一个NAPI软中断回调函数;
/* * 配置MSI-X capability structure,创建9个MSIX中断 * 每个队列注册一个NAPI回调函数 * 合理设置EIAM、EIMC、EIAC、IAM、IMC以disable中断 * 使用request_irq函数注册9个MSIX中断的回调函数 * 将msix_other、收发包队列和msix vector绑定起来 * 使能NAPI软中断、读清pending中断E1000_ICR * 合理设置EIAM、EIMC、EIAC、IAM、IMC以enable中断 */ /* 配置MSI-X capability structure,创建9个MSIX中断 */ for (i = 0; i < numvecs; i++) adapter->msix_entries[i].entry = i; pci_enable_msix_range(adapter->pdev, adapter->msix_entries, numvecs, numvecs); /* 每个队列注册一个NAPI回调函数 */ netif_napi_add(adapter->netdev, &q_vector->napi, igb_poll, 64); /* 使用irq_request函数注册回调函数前,先清理屏蔽已经产生的中断 */ igb_irq_disable /* * 将EIAM(Interrupt Ack Auto Clear Mask)寄存器bit[0:8]清0,该寄存器置1,中断上报后,会将EIMS对应的bit清0 * 将EIMC(Interrupt Mask Clear)寄存器bit[0:8]写1,失能9个MSIX中断 --- 对应enable中断的寄存器是EIMS * 将EIAC(Interrupt Auto Clear)寄存器bit[0:8]清0 --- 该寄存器置1,EICR无法读清,通过读ICR,可以清除EICR对应bit * 将IAM(Interrupt Acknowledge Auto Mask)寄存器写0,如果该寄存器置1,那么中断产生时,会自动将IAM寄存器的值拷贝到IMC以屏蔽中断 * 将IMC(Interrupt Mask Clear)寄存器写1,屏蔽所有类型的中断,相对IMS寄存器 */ u32 regval = rd32(E1000_EIAM); wr32(E1000_EIAM, regval & ~adapter->eims_enable_mask); wr32(E1000_EIMC, adapter->eims_enable_mask); regval = rd32(E1000_EIAC); wr32(E1000_EIAC, regval & ~adapter->eims_enable_mask); wr32(E1000_IAM, 0); wr32(E1000_IMC, ~0); /* 等待所有pending的中断上报完成 */ synchronize_irq(adapter->msix_entries[i].vector) /* vector就是虚拟中断号irq */ struct irq_desc *desc = irq_to_desc(irq); __synchronize_hardirq(desc); wait_event(desc->wait_for_threads, !atomic_read(&desc->threads_active)); /* 注册eims_other中断 */ request_irq(adapter->msix_entries[vector].vector, igb_msix_other, 0, netdev->name, adapter); /* 每个收发包队列注册对应的中断 */ for (i = 0; i < adapter->num_q_vectors; i++) request_irq(adapter->msix_entries[vector].vector, igb_msix_ring, 0, q_vector->name, q_vector); /* MSIX硬件级相关配置 */ /* Turn on MSI-X capability first */ wr32(E1000_GPIE, E1000_GPIE_MSIX_MODE | E1000_GPIE_PBA | E1000_GPIE_EIAME | --- EIAME模式,设置EIAM相应bit为1,中断上报时,自动清除EIMS,这样中断上报后就处于屏蔽状态 E1000_GPIE_NSICR); /* 将msix_other绑定到msix vector */ adapter->eims_other = BIT(vector); tmp = (vector++ | E1000_IVAR_VALID) << 8; wr32(E1000_IVAR_MISC, tmp); /* 将MSIX中断和收发包队列绑定起来 */ if (rx_queue > IGB_N0_QUEUE) igb_write_ivar(hw, msix_vector, rx_queue >> 1, (rx_queue & 0x1) << 4); if (tx_queue > IGB_N0_QUEUE) igb_write_ivar(hw, msix_vector, tx_queue >> 1, ((tx_queue & 0x1) << 4) + 8); /* 使能NAPI软中断 */ napi_enable(&(adapter->q_vector[i]->napi)); /* Clear any pending interrupts. */ rd32(E1000_ICR); /* --- 中断产生后会将该寄存器对应bit置1,该寄存器是读清属性,这些中断不在EICR寄存器中 */ /* 使能中断 */ igb_irq_enable(adapter); /* * 将EIAC(Interrupt Auto Clear)寄存器的bit[0:8]置1,该寄存器置1后,EICR寄存器(中断产生,该寄存器对应bit被置1)不可读 * 将EIAM(Interrupt Ack Auto Clear Mask)寄存器的bit[0:8]置1,和EIMS配合使用,清除已经产生的中断 * 将EIMS(Interrupt Mask Set/Read)寄存器的bit[0:8]置1,enable中断 * 将IMS(Interrupt Mask Set)寄存器的bit2(link status change中断)、bit28(NIC DMA out of sync)、bit30(Device Reset Asserted) */ u32 regval = rd32(E1000_EIAC); wr32(E1000_EIAC, regval | adapter->eims_enable_mask); regval = rd32(E1000_EIAM); wr32(E1000_EIAM, regval | adapter->eims_enable_mask); wr32(E1000_EIMS, adapter->eims_enable_mask); u32 ims = E1000_IMS_LSC | E1000_IMS_DOUTSYNC | E1000_IMS_DRSTA; wr32(E1000_IMS, ims);
2.2 数据发送流程
数据包发送流程包括2个部分:
第一个部分,上层调用发包接口,选择一个发包队列,将数据包放到发包队列的发包buffer中,然后填充该发包buffer对应的DMA描述符,更新TDT寄存器告知i350有新的发包描述符,i350加载新增的发包描述符,内部DMA控制器使用发包描述符的信息将数据包从内存队列搬移到i350内部的发包队列;数据包搬移完成后,将描述符处理结果回写到内存对应的发包DMA描述符,然后,产生msix中断通知cpu;
第二个部分,cpu收到msix中断后,做2个处理,一个是重新设置下一次中断上报的时间间隔;另一个是调用NAPI处理机制,在NAPI软中断中对发包队列进行清理;
/* * 数据包发送流程 * 第一部分 * 发包接口ndo_start_xmit,调用发包接口前使用netif_tx_lock_bh(netdev)关软中断、加锁确保发包流程在所有cpu串行 * 指定发包队列,内存中创建了4个发包队列,为了负载均衡,每次发包时可以选择当前的cpu作为发包队列 * 发包前需要计算发包buffer的数量,如果数量不够,则不进行发包 * 填充发包描述符,发送一个数据包,至少要填充4个描述符:contex描述符、skb head描述符、数据信息描述符、RS和EOP描述符 * 将next_to_use更新为下一次发包使用的位置,并且将next_to_use写入TDT寄存器,通知i350加载上述填充的描述符 */ 1、发包接口ndo_start_xmit 上层调用发包接口前使用netif_tx_lock_bh(netdev)接口关闭当前cpu的软中断,以及占用netdev的自旋锁,这样保证了发包流程在所有cpu的串行 netif_tx_lock_bh(netdev); netdev->netdev_ops->ndo_start_xmit(skb, netdev); netif_tx_unlock_bh(netdev); 2、指定发包队列 内存中创建了4个发包队列,为了负载均衡,每次发包时可以选择当前的cpu作为发包队列 ndo_start_xmit /* 该函数指定发包队列 */ igb_tx_queue_mapping(adapter, skb) unsigned int r_idx = skb->queue_mapping; return adapter->tx_ring[r_idx]; igb_xmit_frame_ring(skb, igb_tx_queue_mapping(adapter, skb)) 3、发包前需要计算发包buffer的数量,如果数量不够,则不进行发包 /* need: 1 descriptor per page * PAGE_SIZE/IGB_MAX_DATA_PER_TXD, * + 1 desc for skb_headlen/IGB_MAX_DATA_PER_TXD, * + 2 desc gap to keep tail from touching head, * + 1 desc for context descriptor, * otherwise try next time */ 每发一个包,都要使用多个发包描述符,分别填充skb head、context以及数据片,并且为了和循环队列head保持距离,发包后至少剩余2个描述符, 因此,发包前按照上述需要计算是否有足够的描述符,如果描述符不够,则不进行发包 /* skb head使用的描述符数量 */ u16 count = TXD_USE_COUNT(skb_headlen(skb)); /* 数据部分使用的描述符数量 */ for (f = 0; f < skb_shinfo(skb)->nr_frags; f++) count += TXD_USE_COUNT(skb_shinfo(skb)->frags[f].size); /* 加上contex和剩余的2个描述符,总的描述符少于count + 3,则不进行发包 */ if (igb_maybe_stop_tx(tx_ring, count + 3)) return NETDEV_TX_BUSY; 4、填充发包描述符,包括contex描述符、skb head描述符、数据信息描述符、RS和EOP描述符 第一个发包描述符用于填充数据包的contex信息,包括分片信息、vlan、cksum等 igb_tx_ctxtdesc(tx_ring, vlan_macip_lens, type_tucmd, 0) struct e1000_adv_tx_context_desc *context_desc; u16 i = tx_ring->next_to_use; context_desc = IGB_TX_CTXTDESC(tx_ring, i); /* 更新描述符队列next_to_use */ i++; tx_ring->next_to_use = (i < tx_ring->count) ? i : 0; /* set bits to identify this as an advanced context descriptor */ type_tucmd |= E1000_TXD_CMD_DEXT | E1000_ADVTXD_DTYP_CTXT; context_desc->vlan_macip_lens = cpu_to_le32(vlan_macip_lens); context_desc->seqnum_seed = 0; context_desc->type_tucmd_mlhl = cpu_to_le32(type_tucmd); context_desc->mss_l4len_idx = cpu_to_le32(mss_l4len_idx); 第二个发包描述符用于填充skb head信息 union e1000_adv_tx_desc *tx_desc; dma_addr_t dma; /* 取出context的下一个描述符 */ u16 i = tx_ring->next_to_use; tx_desc = IGB_TX_DESC(tx_ring, i); size = skb_headlen(skb); /* 将skb head的数据从cache同步到内存,并获取dma总线地址 */ dma = dma_map_single(tx_ring->dev, skb->data, size, DMA_TO_DEVICE); /* 将skb head的dma总线地址记录在第一个发包buffer中 */ dma_unmap_len_set(tx_buffer, len, size); dma_unmap_addr_set(tx_buffer, dma, dma); /* 将skb head的dma总线地址信息填充到发包描述符 */ tx_desc->read.buffer_addr = cpu_to_le64(dma); tx_desc->read.cmd_type_len = cpu_to_le32(cmd_type ^ size); /* 递增描述符和发包buffer */ i++; tx_desc++; 第三个发包描述符用于填充数据信息,如果有多个分片,就填充多个描述符 tx_buffer = &tx_ring->tx_buffer_info[i]; tx_desc->read.olinfo_status = 0; size = skb_frag_size(frag); dma = skb_frag_dma_map(tx_ring->dev, frag, 0, size, DMA_TO_DEVICE); /* dma总线地址信息记录到发包buffer */ dma_unmap_len_set(tx_buffer, len, size); dma_unmap_addr_set(tx_buffer, dma, dma); /* dma总线地址信息记录到发包描述符 */ tx_desc->read.buffer_addr = cpu_to_le64(dma); tx_desc->read.cmd_type_len = cpu_to_le32(cmd_type ^ size); /* 递增描述符和发包buffer */ i++; tx_desc++; 最后,再使用一个发包描述符用于填充RS和EOP /* write last descriptor with RS and EOP bits */ cmd_type |= size | IGB_TXD_DCMD; tx_desc->read.cmd_type_len = cpu_to_le32(cmd_type); /* 使用内存屏障语句,确保上述代码都操作完内存 */ wmb(); 5、将next_to_use更新为下一次发包使用的位置,并且将next_to_use写入TDT寄存器,通知i350加载上述填充的描述符 /* 第一个发包buffer的next_to_watch要保存RS/EOP的描述符 */ first->next_to_watch = tx_desc; /* 更新next_to_use、写TDT寄存器 */ i++; tx_ring->next_to_use = i; if (netif_xmit_stopped(txring_txq(tx_ring)) || !skb->xmit_more) writel(i, tx_ring->tail); mmiowb();
/* * 数据包发送流程 * 第二部分 * msix硬中断处理 * NAPI软中断机制清理发包队列: * 每次最多清理64个数据包, * 如果清理满64个,说明队列还有数据包待清理,那么退出本次清理,不开启msix硬件中断,等下次软中断回调再继续清理; * 如果清理不满64个,说明队列已经清空,那么设置NAPI处理完成标志,并且重新使能msix硬件中断; */ 1、msix硬中断处理 /* 根据前一个中断,重新设置下一次中断的上报间隔 */ /* Write the ITR value calculated from the previous interrupt. */ igb_write_itr(q_vector); writel(itr_val, q_vector->itr_register); /* 调度NAPI软中断来清理发包队列 */ napi_schedule(&q_vector->napi); 2、NAPI软中断机制清理发包队列 NAPI处理机制是: 每次最多清理64个数据包, 如果清理满64个,说明队列还有数据包待清理,那么退出本次清理,不开启msix硬件中断,等下次软中断回调再继续清理; 如果清理不满64个,说明队列已经清空,那么设置NAPI处理完成标志,并且重新使能msix硬件中断; clean_complete = igb_clean_tx_irq(q_vector, budget); /* 从next_to_clean开始清理 */ unsigned int i = tx_ring->next_to_clean; tx_buffer = &tx_ring->tx_buffer_info[i]; tx_desc = IGB_TX_DESC(tx_ring, i); i -= tx_ring->count; 由上述可知,每次发包都至少填充4个描述符,并且第一个发包buffer的next_to_watch指向最后一个RS/EOP描述符; 因此,这里数据包清理时,通过next_to_watch判断此数据包是否能清理; /* 判断是否有RS/EOP描述符 */ if (!eop_desc) break; /* prevent any other reads prior to eop_desc */ read_barrier_depends(); /* i350处理完描述符后,会将处理结果回写到该描述符内存处,这个通过RS/EOP描述符的状态位判断是否处理完成,处理完成才进行清理 */ /* if DD is not set pending work has not been completed */ if (!(eop_desc->wb.status & cpu_to_le32(E1000_TXD_STAT_DD))) break; 清理第一个buffer,也就是skb head的描述符 /* clear next_to_watch to prevent false hangs */ tx_buffer->next_to_watch = NULL; /* free the skb */ napi_consume_skb(tx_buffer->skb, napi_budget); /* DMA unmap */ /* unmap skb header data */ dma_unmap_single(tx_ring->dev, dma_unmap_addr(tx_buffer, dma), dma_unmap_len(tx_buffer, len), DMA_TO_DEVICE); dma_unmap_len_set(tx_buffer, len, 0); 清理剩余的buffer,直到eop_desc while (tx_desc != eop_desc) tx_buffer++; tx_desc++; i++; /* 由上述可以,有一些buffer没有填充数据,直接跳过这些buffer */ if (dma_unmap_len(tx_buffer, len)) dma_unmap_page(tx_ring->dev, dma_unmap_addr(tx_buffer, dma), dma_unmap_len(tx_buffer, len), DMA_TO_DEVICE); dma_unmap_len_set(tx_buffer, len, 0); /* 继续清理下一个数据包,最多处理64个budget */ /* move us one more past the eop_desc for start of next pkt */ tx_buffer++; tx_desc++; i++; /* issue prefetch for next Tx descriptor */ prefetch(tx_desc); /* update budget accounting */ budget--; 最后,更新next_to_clean到下一个数据包的位置 i += tx_ring->count; tx_ring->next_to_clean = i; NAPI回调函数退出前,判断clean_complete是否是64个,如果是,则不开启硬件中断,继续polling,否则开启硬中断,退出NAPI软中断 /* 处理64个,直接返回,不开启硬件中断 */ /* If all work not completed, return budget and keep polling */ if (!clean_complete) return budget; /* 没有处理64个,则退出polling模式,开启硬件中断 */ /* If not enough Rx work done, exit the polling mode */ napi_complete_done(napi, work_done); igb_ring_irq_enable(q_vector);
2.3 数据包接收流程
数据包接收流程可以分为2个阶段,第一个阶段是外部数据包到达i350后,i350内部通过hash机制,将数据包放到一个内部收包队列,这个阶段由i350完成;第二个阶段是i350使用收包描述符将数据包搬移到内存收包队列中,然后上报对应的msix中断通知cpu,驱动代码在msix中断中调度NAPI软中断,在NAPI软中断回调中清理收包buffer,并将数据包送给上层协议栈。
/* * 数据包接收流程 * 外部数据包到达i350后,i350内部通过hash机制将数据包放到内部的一个收包队列 * 数据包接收msix硬件中断处理,设置下一次中断上报间隔,调度NAPI软中断 * NAPI软中断清理收包buffer,并将数据包上送协议栈 * NAPI机制处理数据包:处理64个,直接返回继续下一轮polling,不开启硬件中断;没有处理64个,则退出polling模式,开启硬件中断 */ 1、外部数据包到达i350后,i350内部通过hash机制将数据包放到内部的一个收包队列 这个hash机制在初始化时可以通过寄存器设置 /* configure the multiple receive queue control registers */ igb_setup_mrqc(struct igb_adapter *adapter) netdev_rss_key_fill(rss_key, sizeof(rss_key)); for (j = 0; j < 10; j++) wr32(E1000_RSSRK(j), rss_key[j]); igb_write_rss_indir_tbl(adapter); /* Generate RSS hash based on packet types, TCP/UDP * port numbers and/or IPv4/v6 src and dst addresses */ mrqc = E1000_MRQC_RSS_FIELD_IPV4 | E1000_MRQC_RSS_FIELD_IPV4_TCP | E1000_MRQC_RSS_FIELD_IPV6 | E1000_MRQC_RSS_FIELD_IPV6_TCP | E1000_MRQC_RSS_FIELD_IPV6_TCP_EX; wr32(E1000_MRQC, mrqc); 2、数据包接收msix硬件中断处理 igb_msix_ring(int irq, void *data) /* 设置下一次中断上报的时间间隔 */ /* Write the ITR value calculated from the previous interrupt. */ igb_write_itr(q_vector); /* 调度NAPI软中断 */ napi_schedule(&q_vector->napi); 3、NAPI软中断清理收包buffer,并将数据包上送协议栈 cleaned = igb_clean_rx_irq(q_vector, budget); /* 初始状态cleaned_count是0 */ u16 cleaned_count = igb_desc_unused(rx_ring); /* 一次回调,最多清理64个数据包 */ while (likely(total_packets < budget)) /* 从next_to_clean开始清理 */ union e1000_adv_rx_desc *rx_desc; struct igb_rx_buffer *rx_buffer; rx_desc = IGB_RX_DESC(rx_ring, rx_ring->next_to_clean); /* 收包描述符是i350回写的,需要转成cpu字节序 */ size = le16_to_cpu(rx_desc->wb.upper.length); /* 读描述符前,先使用内存屏障保证软件资源操作内存完成 */ dma_rmb(); /* 取出next_to_clean对应的收包buffer */ rx_buffer = igb_get_rx_buffer(rx_ring, size); /* 将接收的数据组装成一个skb */ skb = igb_construct_skb(rx_ring, rx_buffer, rx_desc, size); /* dma unmap,该操作会置cache无效,保证cpu取到最新数据 */ dma_unmap_page_attrs(rx_ring->dev, rx_buffer->dma, igb_rx_pg_size(rx_ring), DMA_FROM_DEVICE, IGB_RX_DMA_ATTR); rx_buffer->page = NULL; /* 上述完成则清理了一个数据包 */ cleaned_count++; /* 更新next_to_clean */ u32 ntc = rx_ring->next_to_clean + 1; ntc = (ntc < rx_ring->count) ? ntc : 0; rx_ring->next_to_clean = ntc; /* 如果这个收包buffer只是分片,那么进行下一次循环继续取分片放到skb里面,直到取出完整的数据包 */ /* fetch next buffer in frame if non-eop */ if (igb_is_non_eop(rx_ring, rx_desc)) continue; /* 将数据包skb上送协议栈 */ napi_gro_receive(&q_vector->napi, skb); /* 在数据包清理过程中,如果清理了16个,就调用如下函数,将描述符返回给i350 */ if (cleaned_count >= IGB_RX_BUFFER_WRITE) igb_alloc_rx_buffers(rx_ring, cleaned_count); /* 从next_to_use开始清理,清理cleaned_count个数据包 */ u16 i = rx_ring->next_to_use; rx_desc = IGB_RX_DESC(rx_ring, i); bi = &rx_ring->rx_buffer_info[i]; i -= rx_ring->count; do { /* 如果没有分配page,就分配page */ igb_alloc_mapped_page(rx_ring, bi) struct page *page = bi->page; dma_addr_t dma; page = dev_alloc_pages(igb_rx_pg_order(rx_ring)); dma = dma_map_page_attrs(rx_ring->dev, page, 0, igb_rx_pg_size(rx_ring), DMA_FROM_DEVICE, IGB_RX_DMA_ATTR); /* 如果分配了page,将缓存交给i350就行 */ dma_sync_single_range_for_device(rx_ring->dev, bi->dma, bi->page_offset, bufsz, DMA_FROM_DEVICE); /* 因为收包描述符被i350回写了,这里要重新将dma总线写到描述符 */ rx_desc->read.pkt_addr = cpu_to_le64(bi->dma + bi->page_offset); cleaned_count--; } while (cleaned_count); /* 最后,更新next_to_alloc,并写入RDT寄存器,让i350加载新的收包描述符 */ rx_ring->next_to_use = i; rx_ring->next_to_alloc = i; /* 使用内存屏障,保证数据写内存完成 */ wmb(); writel(i, rx_ring->tail); cleaned_count = 0; NAPI回调函数退出前,判断clean_complete是否是64个,如果是,则不开启硬件中断,继续polling,否则开启硬中断,退出NAPI软中断 /* 处理64个,直接返回,不开启硬件中断 */ /* If all work not completed, return budget and keep polling */ if (!clean_complete) return budget; /* 没有处理64个,则退出polling模式,开启硬件中断 */ /* If not enough Rx work done, exit the polling mode */ napi_complete_done(napi, work_done); igb_ring_irq_enable(q_vector);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号