hadoop学习-入门
一、克隆虚拟机
1.使用vim /etc/sudoers进去修改用户权限
2.设置虚拟机ip:vim /etc/sysconfig/network-scripts/ifcfg-ens33
3.设置虚拟机名称:vim /etc/hostname
4.压缩jdk文件:tar -zxvf jdk-8u341-linux-x64.tar.gz -C /opt/module/
5.卸载虚拟机自带的JDK:rpm -qa|grep -i java|xargs -n1 rpm -e --nodeps
6.装完JDK和Hadoop后要用source /etc/profile命令进行初始化配置文件
二、编写集群分发脚本xsync
1.scp安全拷贝:scp -r 要拷贝的文件路径或名称 目的地用户@主机:目的地路径/名称例如:scp -r jdk1.8.0_341/ lzp@hadoop104:/opt/module/
2.rsync同步命令:rsync -av 要拷贝的文件路径或名称 目的地用户@主机:目的地路径/名称
3.xsync脚本:
#!/bin/bash
#1.判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2.遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ================= $host =================
#3.遍历所有目录,挨个发送
for file in $@
do
#4.判断文件是否存在
if [ -e $file ]
then
#5.获取父目录
pdir=$(cd -P $(dirname $file);pwd)
#6.获取当前文件名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
donewe
4.在根目录下创建一个bin文件,然后将xsync脚本放进去,然后使用xsync 文件名即可进行集群分发
5.ssh免密登录:
(1)进入.ssh目录
(2)ssh-keygen -t rsa获取公钥和密钥
(3)ssh-copy-id 服务器名设置到指定服务器密码登录
6.集群配置文件:
(1)进入etc/hadoop/中
(2)vim core-site.xml加入
<configuration>
<!--指定NameNode地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!--指定hadoop数据的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.2.4/data</value>
</property>
</configuration>
(3)vim mapred-site.xml加入
<configuration>
<!--指定MapReduce程序运行在Yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(4)vim hdfs-site.xml加入
<configuration>
<!--nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!--2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
(5)vim yarn-site.xml加入
<configuration>
<!--指定MR走shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!--环境变量的继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
(6)进入etc/中,使用xsync hadoop/命令进行集群分发
(7)进入etc/hadoop/中vim workers,里面配置为
hadoop102
hadoop103
hadoop104
(8)利用xsync进行集群分发
7.启动集群:
(1)进入/opt/module/hadoop-3.2.4/,hdfs namenode -format初始化
(2)在Hadoop102中使用sbin/start-dfs.sh进行启动HDFS
(3)在Hadoop103中使用sbin/start-yarn.sh进行启动YARN
(4)hdfs --daemon start datanode启动datanode
(5)yarn --daemon start nodemanager启动nodemanager
三、使用集群
1.可在hadoop102:9870的Utilities中的Browse the file system中查看
2.在hadoop103:8088里面查看yarn
3.在集群中创建文件hadoop fs -mkdir 文件名
4.上传文件到集群上hadoop fs -put 本地文件 集群路径
5.配置历史服务器,在mapred-site.xml中加入:
<!--历史服务器端地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!--历史服务器web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
6.启动历史服务器:bin/mapred --daemon start historyserver
7.往yarn-site.xml中加入:
<property>
<name>yarn.application.classpath</name>
<value>/opt/module/hadoop-3.2.4/etc/hadoop:/opt/module/hadoop-3.2.4/share/hadoop/common/lib/*:/opt/module/hadoop-3.2.4/share/hadoop/common/*:/opt/module/hadoop-3.2.4/share/hadoop/hdfs:/opt/module/hadoop-3.2.4/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.2.4/share/hadoop/hdfs/*:/opt/module/hadoop-3.2.4/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.2.4/share/hadoop/mapreduce/*:/opt/module/hadoop-3.2.4/share/hadoop/yarn:/opt/module/hadoop-3.2.4/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.2.4/share/hadoop/yarn/*</value>
</property>
8.往yarn-site.xml加入:
<!--开启日志聚集功能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--设置日志聚集服务器地址-->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!--设置日志保留时间7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
四、脚本
1.开启集群的hdfs和yarn,在bin目录下vim myhadoop.sh编写:
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit;
fi
case $1 in
"start")
echo "================启动hadoop集群====================="
echo "------------启动hdfs---------------------"
ssh hadoop102 "/opt/module/hadoop-3.2.4/sbin/start-dfs.sh"
echo "------------启动yarn--------------------"
ssh hadoop103 "/opt/module/hadoop-3.2.4/sbin/start-yarn.sh"
echo "------------启动historyserver-----------"
ssh hadoop102 "/opt/module/hadoop-3.2.4/bin/mapred --daemon start historyserver"
;;
"stop")
echo "================关闭hadoop集群====================="
echo "------------关闭historyserver---------------------"
ssh hadoop102 "/opt/module/hadoop-3.2.4/bin/mapred --daemon stop historyserver"
echo "------------关闭yarn--------------------"
ssh hadoop103 "/opt/module/hadoop-3.2.4/sbin/stop-yarn.sh"
echo "---------------关闭hdfs--------------"
ssh hadoop102 "/opt/module/hadoop-3.2.4/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
2.编写脚本查看所有服务器jps,vim jpsall中编写:
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =================$host==================
ssh $host jps
done
五、常见面试题
1、常用端口号:
hadoop3.x
HDFS NameNode 内部通常端口:8020/9000/9820
HDFS NameNode 对用户的查询端口:9870
Yarn查看任务运行情况:8088
历史服务器:19888
hadoop2.x
HDFS NameNode 内部通常端口:8020/9000
HDFS NameNode 对用户的查询端口:50070
Yarn查看任务运行情况:8088
历史服务器:19888
2.常见的配置文件
3.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml workers
2.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml slaves
六、时间服务器:
1.打开时间服务器:systemctl start ntpd,systemctl is-enable ntpd
2.vim /etc/ntp.conf打开配置文件,然后将下面这行代码注释取消,更改一下ip:

将下面这几条注释掉
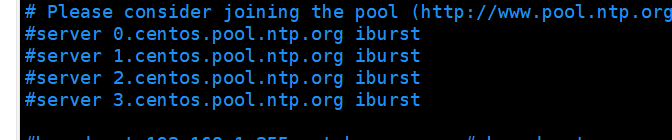
添加下面几条命令:




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构