
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 1、阅读《构建之法》并再提出五个问题2、完成词频统计个人作业 |
| 其他参考文献 | 《构建之法》 |
阅读《构建之法并提出五个问题》
问题一:我认为要实现一个项目不只是需要能创新就够了,这其中和资金、人才以及机遇也有很大的关系。一个好的点子能否实现,和点子由谁想出、点子由谁实现和点子产生的时代背景密不可分。文中区分了“创新者”和“先行者”,实际上“创新者”并可能不是第一个想出那些好点子的人,既然如此,这还能叫做创新吗?
原文:......大家听了很多创新者的故事,有些人想,他们真了不起,第一个想出了这些美妙的想法,要是我早生几十年,也第一个实现那些想法就好了。其实,大部分成功的创新者都不是先行者,例如搜索引擎,Google是很晚才进入这个领域的。又如Apple的音乐播放器iPod,发布于2001年10月23日,在它之前市面上已经有很多同类产品了......
问题二:在中国知识产权一直不受人重视,这一段的上文中的魔方创新也是如此,果冻没能保护好关于魔方的专利,使得技术被他人魔方学走(虽然这篇短文想告诉我们的应该不是这个道理),在中国这样一个大环境之下,我们应该怎么样合理地维护创新成果?结合上一个问题,人们是否可以为了自己的私欲,把没有把握实现的创新想法藏在心中不让他人知道?
原文:......这些对“小作坊”睁一只眼闭一只眼的经理,值得表扬。这些好的作坊,都有这些核心特性:从小事做起,重质量,讲信用,对产品负责,对工作自豪。作坊这么好,那中国的许多作坊为什么不能兴旺?大家经常提到的一个原因,就是“环境对知识产权的尊重和保护不够”,其实哪里都有盗版,哪里都有抄袭,哪里都有竞争。有能力的作坊,往往能找到合适的渠道和空间,实现自己的价值。那些想开作坊的人,你们对知识产权又是如何尊重和保护的呢?你心里“热爱技术”么?你是否发现了自家作坊的独特价值?你能放弃貌似免费的看热闹的机会,在网上斗嘴的爽快,倒卖绘图仪的短期收益,吹嘘自己要写一个平台的风光,先练好内功?作坊就在那里,你是装作路过没看见,还是走进去?......
问题三:每个团队中大伙儿的负担都是不同的,有的人可能为了团队会舍弃很多,有的人可能在工作中付出了相对于别人来说不重要但是最他自己十分重要的东西,每个人的负担与付出可以说因为个体的原因,没有一个很好的度量方法,既然如此,在分配资源和收益的时候应该根据这些负担去考虑分配吗?如果负担不同但是任务相同呢?还是说应该在组建团队之初就商量好所有人都平均分配?这样又是否会打击到队友的积极性?具体应该怎么实现会比价合理。
原文:......猪: 提供猪肉,做熏肉。鸡: 提供鸡蛋,做煎蛋。鹦鹉:提供咨询,每天阅读大量博客,给其他团队成员提供建议,例如业界最新趋势、最新术语、SaaS、N-层架构、创业明星当年的轶事,等等。这次创业对三个动物的负担是一样的么?它们又该各占多少股份?一旦创业失败,猪、鸡和鹦鹉各自会失去什么?在一个团队中,不同的成员来自五湖四海,为了一个共同的目标,走到一起来了(至少表面上是这样)。
问题四:团队在谈及分配利益的时候每个人都不希望自己拿不到属于自己的那一份,但是每个人所做的工作方向不同,内容不同,效率不同,擅长的领域也更不相同,每个人对他人的付出或许都会有不同的评价,有没有一套相对来说比较客观的评判标准,能具体不抽象地反应出团队里每个队员做出的贡献呢?
原文:......有人建议按照角色来定位,例如有猪、鸡和鹦鹉等,问题是大多数鹦鹉都说自己是鸡,剩下的都认为自己是猪,而且分量很重!有人建议根据工作时间来衡量,这规定一宣布,大家都开始比谁走得晚,另外,我周末一直在想工作上的事,这算工作时间么?
比资历?
软件行业的竞争有“赢者通吃”的规律,一个快要被市场淘汰的产品不能说:我们是最先进入这一市场的,理应继续占有足够份额!软件团队成员也不能说:我来得早,所以我的报酬就应该多!
大锅饭?
所有人都评“优”,大家平分钱,好么?优秀的人会离开,最后会剩下平庸的人在过平均主义——也许整个团队都被淘汰了。同一团队的成员报酬能差别多大?我们看看职业篮球的一个例子:1997—1998赛季,迈克尔·乔丹挣了8000万美元,而他的队友乔·克莱恩(JoeKleine)当年挣了27万美元。两者相差将近300倍!如果两人挣钱平均分,谁会离开?球队因此变强还是变弱?
比效率?
我们也知道软件开发人员的效率有很大的差别,一流程序员的效率是普通程序员的10倍;有些效率的差别还有正负之分。一个心不在焉的程序员可以一天写2000行代码,然后测试人员和其他开发人员要花很多时间来修复其中的缺陷,这些同事原本要做的任务就被耽误了。同时,一个非常用心的程序员发现可以重用以前的稳定模块,他花很多时间重构和测试,最后只修改了500行代码,缺陷特别少,这样无形中节约了其他同事的大量时间。曾有研究[注释5]衡量不同水平的程序员(从接受编程培训的学生,到有7年经验的工程师)的效率和质量,他们在解决复杂问题时,最低效的程序员所花的时间是最高效的程序员的20倍。不仅如此,低效的程序员所写的程序在质量上也有明显的差距。如果你的团队失去了最高效的程序员,那么即使你能马上找到20个菜鸟(最初级的程序员),也无法产生同样质量的软件,更不用说20个菜鸟程序员在交流时所产生的众多问题和生产力的损失。
背靠背评比?
根据所有其他人的评价来决定某个人的绩效?这样会发生小团体抱团,以及劣币驱逐良币的现象。做游戏的工程师一定听说过维尔福公司(Valve[注释6],开发有半条命、反恐精英等游戏),这家公司的员工手册[注释7]很有意思,大家不妨看看。根据手册的描述,维尔福的员工可以自由支配100%的工作时间,做什么项目、在哪儿工作等,员工可以自己做主。但是在绩效评估上,他们用了队友评估这一机制,得出下列四个值:1. 技术等级/技术能力2. 劳动生产力/结果3. 对团队的贡献(做一些工具让大家的工作更容易,帮助招人)4. 对产品的贡献(除本职工作外,对产品有帮助的活动,比如找Bug、预测用户的反馈、产品推广等)
比不犯错误?
软件项目的进展不是一帆风顺的,总会有问题发生,出了问题,就一定会记在相关人员的账上,以便总结提高。但是一定会作为绩效评估的依据?那倒不一定。如果成员的行为只影响己,或者是探索式的行动,则不是坏事。例如有些成员自行探索最新的技术,但是最后决定不采用此技术。如果团队成员的行为影响整个团队,例如构建中断(Build Break)导致每日构建(DailyBuild)失败,则要注意。在一个里程碑中,可以统计谁导致这种错误最多。对此可以采取本书前面提到的“构建大师”方法处理。如何区别对待?......
问题五:在一个团队中,我认为萝卜和白菜都是必不可少的角色,萝卜能够保证代码的产出效率,白菜则是能够保证程序整体的稳定性和质量,这两类人面对不同的项目中具体应该占的比例应该是什么样的?或者说什么样的项目更需要萝卜多一些,什么样的项目更需要白菜多一些?
原文:......阿超:我有一个故事,假设团队里来了两位年轻人,嗯,就叫“萝卜”和“白菜”。萝卜做事很快,是“萝卜快了不洗泥”类型;白菜是“慢工出细活”类型。分配了任务后,萝卜很快就说做好了!白菜还在吭哧吭哧地跟项目经理和测试人员讨论。领导很高兴,让萝卜去做更多的事。开发阶段结束了,萝卜比白菜多做了不少功能。稳定阶段开始了。大家发现萝卜负责的功能出了很多问题,白菜的模块倒是比较稳定。然而萝卜在团队中的曝光率很高,很多问题都在等着他解决,从统计数据上看,他也修复了不少小强。白菜搞定了自己负责的模块,开始帮助其他人,由于不熟悉其他人的模块,白菜修复的缺陷不多。由于萝卜的设计有缺陷,导致模块非常复杂,萝卜也成了唯一了解其模块的开发人员。项目最后阶段,几乎都是萝卜工作得最晚,把最后几个缺陷给修复了。领导们说:有问题,找萝卜!项目结束了,开始了绩效考核,领导A认为白菜绩效不错,模块按时完成,没有大多问题,然后还能帮助其他成员;领导B认为萝卜是超级明星:第一个完成模块,修复的缺陷最多,而且掌握了最复杂的模块,离开他不行,工作得也很晚,有突出贡献。至于白菜,领导B没感觉他做了啥,仅仅是按要求完成任务
了。萝卜白菜,各有所爱。那萝卜和白菜谁该得到奖励,谁该得到批评呢?假如领导B的评价方式占了上风,萝卜得到奖励,白菜离开了团队,你觉得下一个版本会出现什么情况......
附加题:


在早期许多学者都认为下图的键盘比上图的键盘更好,因为元音字母都在中间一行能提高打字的速度。然后由于但是制作方式和材质的原因,如果把常用的元音字母都放在同一行,会使得键盘的磨损加快,因此厂商还是选择按上图的方式制造键盘。久而久之,即使现在能够从制作方式和材质上减少常用字符放在同一行带来的磨损,人们也已经习惯了上图的键盘模式。
程序作业
作业描述
在大数据环境下,搜索引擎,电商系统,服务平台,社交软件等,都会根据用户的输入来判断最近搜索最多的词语,从而分析当前热点,优化自己的服务。首先当然是统计出哪些词语被搜索的频率最高啦,请设计一个程序,能够满足一些词频统计的需求。
项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 15 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | 600 | 959 |
| • Analysis | • 需求分析 (包括学习新技术) | 30 | 67 |
| • Design Spec | • 生成设计文档 | 30 | 15 |
| • Design Review | • 设计复审 | 10 | 5 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| • Design | • 具体设计 | 60 | 40 |
| • Coding | • 具体编码 | 420 | 732 |
| • Code Review | • 代码复审 | 30 | 40 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 20 | 40 |
| Reporting | 报告 | 60 | 98 |
| • Test Repor | • 测试报告 | 20 | 78 |
| • Size Measurement | • 计算工作量 | 15 | 10 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 25 | 10 |
| 合计 | 680 | 1072 |
解题思路
先把任务主要分成了读写文件、统计行数、统计字符数量、统计单词数量和统计频率这个几个部分。最开始想的是一行一行地读取文件同时记录行的数量,然后再把接收的每一行拼接成一个大的字符串去统计字符数量那些的。然后在实际做的过程中发现做出来的效果和题目的要求不相符合,如果要这样做恐怕会比较麻烦,于是把读入的全部加入到字符串中再去判断。在统计词频的过程中原本想的是用两个数组分别记录下单词和词频,写的过程中感觉很麻烦,后来在找资料的过程中发现之前学过的map可以很好地实现想法就直接用上了。
代码规范
实现过程
1.文件读写
读取文件代码:先判断文件是否存在如果不存在就返回文件不存在异常,如果存在就打开输入流用BufferedReader来读取文件内容,读取失败会返回读取失败异常,用StringBuilder接收后转成String返回。
InputStreamReader read = new InputStreamReader(new FileInputStream(file),
"UTF-8");
BufferedReader bufferedReader = new BufferedReader(read);
int x;
while((x=bufferedReader.read()) != -1) {
Text.append((char)x);
}
read.close();
写文件的代码:这段是把统计结果合并成一个String后用输出流进行输出写入目标文本filePath(如果目标文本不存在会自动创建),如果输出失败会提示异常。
FileOutputStream p;
try {
p = new FileOutputStream(filePath);
p.write(str.getBytes());
p.close();
}
2.统计行数
因为不会记录空白行,所以直接按\s把从intput读来的字符串进行分割放入String数组并统计这个数组长度,遍历String数组如果有空的就让刚刚统计的长度-1。
String[] LINE = str.split("\\s"); //把可能换行的地方分割出来
int lines = LINE.length;
for(int i = 0;i < LINE.length; i++ ) { //减去空白行
if(LINE[i].isEmpty()) lines-- ;
}
3.统计字符数量
这个直接把接收的字符串转成char数组,遍历数组统计能用ASCII码表示的字符数量。
public static int countChars(String str) { //统计字符数量
int sum = 0;
char[] cs = str.toCharArray();
for(int i = 0;i < cs.length; i++ ) {
if(cs[i] >= 0 && cs[i] < 128) sum++ ;
}
return sum;
}
4.统计单词数量
这里也是用到了split来分割,因为单词内部不可能有除了字母和数字以外的字符,所以把读取的字符串按除了字母数字以外的符号分割放入String数组,再对这个数组里面的每个元素进行判断是否符合单词的要求,如果符合就让计数器+1,最后返回计数器结果。
......
//把可能是单词的字符串切割出来
int words = 0;
for(int i = 0;i < strArray.length; i++ ) {
if(strArray[i].length() < 4)continue;
else {
String temp=strArray[i].substring(0,4); //检测是否符合规则
if(temp.matches("[a-z]*")) {
words++;
}
}
}
5.统计单词出现频率
这段代码先是做了和上面一段一样的事,不过不是符合单词规则就让计数器加1而是把符合规则的记录下在一个String数组中,之后遍历数组,用Map来记录单词以及它出现的频率,key是单词的字符串,value是出现的频率,之后再遍历Map找value最大的,如果value的值相同就比较key值,遍历一次就得到一个结果,把结果加入到要输出的StringBuilder里,并在Map中把那个结果删除,这样遍历10次或者直到Map中没有元素,最后把Stringbuilder转成String返回。
public String countTimes(String str) { //统计单词出现次数
......
//前面先是是用了一个List来存储所有符合条件的单词(相同的单词也会被重复apend,然后把List里面的内容存入Map)
StringBuilder finalstr=new StringBuilder();
while(!map.isEmpty()) {
int i = 0,maxvalue = 0;
String maxstr = " ";
for(String s:key) {
......
//遍历map,比较出value值最大的key,如果value的值相同就比较key的ASCII码
}
finalstr.append(maxstr + ":" + maxvalue + "\n");
map.remove(maxstr);
if(i == 9)break; //如果finalstr中的单词数量已经有10个了就退出循环
}
性能测试
(测试文本中包含空白行、不符合单词规则的字符串、出现次数相同但是不完全相同的单词)
10000个字符串

100000个字符串
不是很会分析。。。
单元测试
测试文本与结果
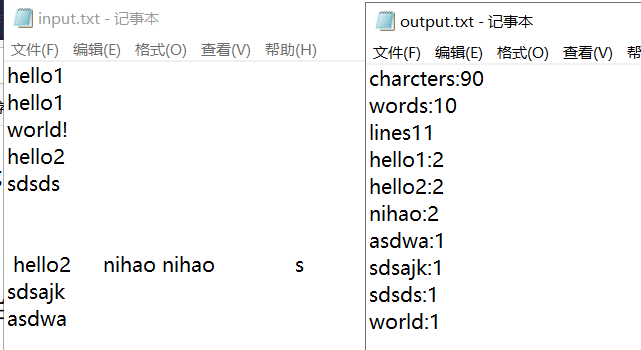
测试文本中包含空白行、不符合单词规则的字符串、出现次数相同但是不完全相同的单词
覆盖率截图
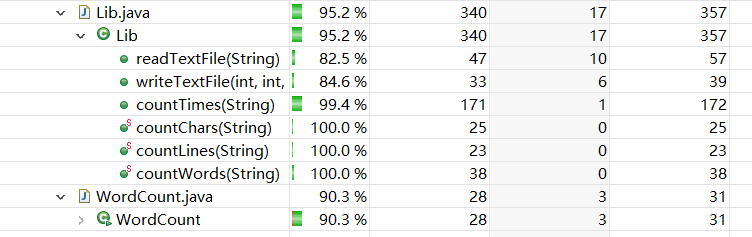
提高覆盖率的办法
简化逻辑,减少不必要的判断,消除重复代码。
异常处理
当要求读取的文件不存在时会报错
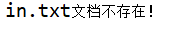
心路历程
这次作业学习由于寒假期间在电影院兼职所以拖得比较迟才开始,刚开始启动这个作业的时候在github上花了很多时间,因为是第一次使用这个网站又是全英文,即使是翻译完也不是很能理解每个模块的功能。在写代码的阶段刚开始想的比较简单,但是随着群里同学们提出的问题也发现了自己的代码和题目的要求其实有很多不相符的地方,进行了一些修改。在最后统计单词出现频率的地方收获比较大,Map<object,object>虽然是之前学过的知识但是这次编码的时候没有第一时间想起,通过这次实践让我对它加深了印象。感觉以后写程序不能光在脑子里想想,有时想的过于简单,有些关键的地方想起来或许容易,但是用代码表达起来就比较复杂。在写这篇博客的过程中也有很多第一次接触的东西,也都通过百度和问别的同学尽量学习了,收获还是很大的。

