ES 使用记录
一、环境搭建
参考以下两个链接介绍:
ES集群安装:https://www.jianshu.com/p/57c3061bb6cb
ES集群 + kibana安装:https://blog.csdn.net/cxfeugene/article/details/82710504
二、搭建Demo
有以下几种方式:
(1)使用Java API即使用TransportClient操作Es(目前官方已不推荐使用)
(2)官方给出了基于HTTP的客户端REST Client(推荐使用),官方给出来的REST Client有Java Low Level REST Client和Java Hight Level REST Client(API官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/6.2/java-rest-high-supported-apis.html)两个,前者兼容所有版本的ES,后者是基于前者开发出来的,只暴露了部分API,待完善
(3)使用 spring-data-elasticsearch,具体可参考博文:https://blog.csdn.net/jacksonary/article/details/82729556
我采用最后一种,即使用springboot2.2.0 + spring-data-elasticsearch3.2.0组合;搭建springboot2.2.0项目,然后引入spring-data-es即可:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
注意事项:
(1)不要特意去指定版本,如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>2.0.2.RELEASE</version>
</dependency>
由于版本兼容性不明白,会导致各种兼容问题(缺包,冲突等),所以指定了spring-boot版本之后,其他的使用其默认的(最新版本)即可,如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
(2)spring和elasticsearch有两种链接方式,一种是用TCP协议,默认端口是9300,还有一种用http协议
三、项目实战
1、熟悉了ES之后,大家都知道,使用ES第一步则是创建一个index(跟ES官网说的那样,index就好比一个数据库,但在ES7.x之后,index已经不像一个数据库了,而更像数据库中的一张表,因为淡化了type的概念);spring项目中如何创建ES的index呢?
有如下两种方式:
(1)使用json格式定义mapping以及setting
具体内容:
mapping.json

{
"xxx": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text"
}...
setting.json
{
"index": {
"number_of_shards": "2",
"number_of_replicas": "0"
}
}
然后再定义实体类:
@Setter
@Getter
//ES的三个注解
//指定index索引名称为项目名 指定type类型名称为实体名
@Document(indexName = "xxx", type = "xxx")
//相当于ES中的mapping 注意对比文件中的json和原生json 最外层的key是没有的
@Mapping(mappingPath = "/mapping.json")
//相当于ES中的settings 注意对比文件中的json和原生json 最外层的key是没有的
@Setting(settingPath = "/setting.json")
public class Builder {
//id
@Id
private Long id;
...
}
(2)不使用json文件,直接在实体类定义
@Data
@Document(indexName = "xxx",type = "xxx",replicas = 0, shards = 1) // 这里缺省type会默认为实体类名
public class xxx{
@Id
private String aid;
@Field(type = FieldType.Text,fielddata = true)
private String name;
...
}
在这里需要清楚这几个mapping(@Field 内的参数)参数:
- fielddata:text类型不支持doc_values属性,因此无法对text类型进行聚合、排序、脚本取值等操作,可以使用fielddata属性设置,设置其为true即可
- index:es默认将每个字段进行倒排索引的构建,这样会耗费空间,所以在不需要索引的字段务必设置index=false
- format:用于对日期格式的数据进行格式化
- ignore_above:不会对超过指定长度的字符串构建索引以及store,通常来讲,是对keyword类型使用,而不能对text字段使用
- fields:一个 string 类型字段可以被映射成 text 字段作为 full-text 进行搜索,同时也可以作为 keyword 字段用于排序和聚合
{
"mappings": {
"my_type": {
"properties": {
"city": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}
}
}
- norms:norms用于计算相关性得分,但会消耗较多的磁盘空间。如果不需要对某个字段进行评分,最好不要开启norms
2、当一切就绪之后,先插入数据
(1)首先定义dao层,如下:
public interface XxxRepository extends ElasticsearchRepository<xxx, String> {
xxx findByAid(String aid);
List<xxx> findByAidIn(List<String> aids);
}
继承ElasticsearchRepository类,里面有基本的CURD方法,基本够用。
当然上面这种方法有局限性,因为其只有一些比较基本常用的操作,如果需要比较复杂的操作,怎么办?那就是获取原生的 ElasticsearchTemplate,因为上面那种方式其实也是使用的这个东西,只是帮你封装好了一些方法,当我们发现上面那种方式
不够用时就使用第二种:
@Autowired
protected ElasticsearchTemplate elasticsearchTemplate;
只需注入即可,以下是使用该方法实现upSet(有记录时就更新该记录,无记录时就插入)方法:
/**
* @author liuzj
*/
@Component
public class EsTemplateRepository<T> {
@Autowired
protected ElasticsearchTemplate elasticsearchTemplate;
/**
* 更新/插入
*
* @param list 对象集合
* @return 更新/插入数量
* @throws Exception 异常
*/
public int upSert(List<T> list) throws Exception {
if (CollectionUtils.isEmpty(list)) {
return 0;
}
// 验证对象是否有唯一标识
T entity = list.get(0);
Field id = null;
for (Field field : entity.getClass().getDeclaredFields()) {
Id businessID = field.getAnnotation(Id.class);
if (businessID != null) {
id = field;
break;
}
}
if (id == null) {
throw new Exception("Can't find @Id on " + entity.getClass().getName());
}
Document document = ReflectUtil.getDocument(entity.getClass());
List<UpdateQuery> updateQueries = new ArrayList<>();
for (T obj : list) {
UpdateQuery updateQuery = new UpdateQuery();
updateQuery.setIndexName(document.indexName());
updateQuery.setType(document.type());
updateQuery.setId(ReflectUtil.getFieldValue(id, obj).toString());
// 插入
IndexRequest indexRequest = new IndexRequest(updateQuery.getIndexName(), updateQuery.getType(), updateQuery.getId())
.source(ReflectUtil.Obj2Map(obj, true));
// 更新
UpdateRequest updateRequest = new UpdateRequest(updateQuery.getIndexName(), updateQuery.getType(), updateQuery.getId())
.doc(ReflectUtil.Obj2Map(obj, false))
.upsert(indexRequest);
updateQuery.setUpdateRequest(updateRequest);
updateQuery.setClazz(obj.getClass());
updateQueries.add(updateQuery);
}
if (!CollectionUtils.isEmpty(updateQueries)) {
elasticsearchTemplate.bulkUpdate(updateQueries);
}
return list.size();
}
/**
* 单个更新/插入
*
* @param obj 数据
* @return int
* @throws Exception 异常
*/
public int upSert(T obj) throws Exception {
List<T> objs = Lists.newArrayList();
objs.add(obj);
return upSert(objs);
}
}
当然,如果上面那种方式还是无法满足你的需求,那么你还可以使用更原始的方式,ElasticsearchTemplate 类提供了getClient()方法,直接获取ES client,满足你使用原生Api
3、数据插入基本搞定,现在了解一下数据查询
使用查询难免遇到它:QueryBuilders,顾名思义,它是一个查询的构造者,它能构造出各种查询,具体可以看其源码

现在看一下一些常见查询
(1)fuzzyQuery
功能:模糊匹配
原理:fuzzy搜索技术。搜索的时候,可能输入的搜索文本会出现误拼写的情况,自动将拼写错误的搜索文本,进行纠正,纠正以后去尝试匹配索引中的数据,纠正在一定的范围内如果差别大无法搜索出来
总体代码逻辑:
// 构造一个多条件查询
BoolQueryBuilder boolBuilder = QueryBuilders.boolQuery();
// 构造子条件查询
FuzzyQueryBuilder fuzzyQuery = QueryBuilders.fuzzyQuery("name","xxx");
boolBuilder.filter(matchQuery);
xxxRepository.search(boolBuilder);
类似于es代码:
GET /my_index/my_type/_search
{
"query": {
"fuzzy": {
"text": {
"value": "surprize",
"fuzziness": 2
}
}
}
}
// fuzziness 即为最多纠正两个字母然后去匹配,默认为 auto(2)
(2)matchQuery
功能:模糊匹配
// 构造一个多条件查询
BoolQueryBuilder boolBuilder = QueryBuilders.boolQuery();
// 构造子条件查询
FuzzyQueryBuilder fuzzyQuery = QueryBuilders.matchQuery("name","xxx");
boolBuilder.filter(matchQuery);
xxxRepository.search(boolBuilder);
类似于es代码:
GET my_index/my_type/_search
{
"query": {
"match": {
"xxx": "Quick Foxes!"
}
}
}
(3)termQuery
功能:精确匹配
java代码方式同上
es代码:
GET bigdata-archive/_search
{
"query": {
"term" : {
"cid" : {
"value" : "5137376667422s31000000"
}
}
}
}
(4)rangeQuery
功能:范围查询
java代码方式同上
es代码:
GET bigdata-archive/_search
{
"query": {
"range" : {
"personFileCreateTime" : {
"from" : 1572331788000,
"to" : 1572331789000,
"include_lower" : true,
"include_upper" : true
}
}
}
}
(5)existsQuery
功能:是否存在查询,即是否为null
java代码方式同上
es代码:
GET bigdata-archive/_search
{
"query": {
"exists" : {
"field" : "cid",
"boost" : 1.0
}
}
}
(6)聚合查询
功能:查询统计
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 查询
queryBuilder.must(QueryBuilders.rangeQuery("age")
.gte(startAge)
.lte(endAge));
// 聚合
AggregationBuilder maxAggregator = AggregationBuilders.max("bathDate").field("time");
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("group_by_age").field("age")
.subAggregation(maxAggregator);
SearchQuery build = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.addAggregation(termsAggregationBuilder)
.build();
AggregatedPage<XXX> testEntities = elasticsearchTemplate.queryForPage(build, XXX.class);
// 取出聚合结果
Aggregations entitiesAggregations = testEntities.getAggregations();
Terms terms = entitiesAggregations.get("group_by_age");
(7)分页查询,一般的业务分页都会采用from to 但是这个在ES里面是越往后查询消耗越大,因为数据分片,每次查询一页数据都要从每个分片去除一页,页数越多就相当耗内存了,于是如果要往后翻很多页,也就是所谓深分页,官方建议使用ScrollSearch,采用游标方式记录上一次你查到哪里了,然后再基于上一次查询的地方往下查 ↓
Client client = elasticsearchTemplate.getClient(); SearchResponse scrollResp = client.prepareSearch("index 名") .addSort("排序字段名", SortOrder.DESC) .setScroll(new TimeValue(60000)) .addDocValueField("需要取出的字段") .setSize(personPropertiest.getArchiveImageCountAndRecentSnapTimeUpdateBatch()).get(); do { SearchHit[] hits = scrollResp.getHits().getHits(); if (hits != null && hits.length > 0) { // 业务逻辑 } scrollResp = client.prepareSearchScroll(scrollResp.getScrollId()).setScroll(new TimeValue(60000)).execute().actionGet(); } while(scrollResp.getHits().getHits().length != 0);
(8)桶过滤分页
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery(); // 查询 queryBuilder.must(QueryBuilders.termQuery("xx",xxx)); SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); queryBuilder.must(QueryBuilders.rangeQuery("time") .gte(dateFormat.parse(startTime).getTime()) .lte(dateFormat.parse(endTime).getTime())); // 聚合 MinAggregationBuilder minAggregationBuilder = AggregationBuilders.min("startTime").field("time"); MaxAggregationBuilder maxAggregationBuilder = AggregationBuilders.max("endTime").field("time"); Map<String,String> bucketMap = Maps.newHashMap(); bucketMap.put("count","_count"); TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("group_by_source_id").field("sourceId").order(BucketOrder.key(false)).size(Integer.MAX_VALUE) .subAggregation(minAggregationBuilder) .subAggregation(maxAggregationBuilder); // 桶过滤 if (activityRoutineType == 0) { termsAggregationBuilder.subAggregation(PipelineAggregatorBuilders.bucketSelector("terms_count",bucketMap,new Script("params.count >= 3"))); }else { termsAggregationBuilder.subAggregation(PipelineAggregatorBuilders.bucketSelector("terms_count",bucketMap,new Script("params.count < 3"))); } // 桶分页 List<FieldSortBuilder> sorts = Lists.newArrayList(); sorts.add(SortBuilders.fieldSort("_count").order(SortOrder.DESC)); termsAggregationBuilder.subAggregation(PipelineAggregatorBuilders.bucketSort("count_sort",sorts).from((page - 1) * perpage).size(perpage)); SearchQuery build = new NativeSearchQueryBuilder() .withQuery(queryBuilder) .addAggregation(termsAggregationBuilder) .build(); // 执行查询 AggregatedPage<XXX> testEntities = elasticsearchTemplate.queryForPage(build, XXX.class); // 取出聚合结果 Aggregations entitiesAggregations = testEntities.getAggregations(); Terms terms = entitiesAggregations.get("group_by_source_id"); if (terms == null) { return new Page<>(); } Page<XXX> result = new Page<>(); for (Terms.Bucket bucket : terms.getBuckets()) { // TODO } return result;
以上代码相当于ES脚本:
GET bigdata_event/_search
{
"query": {
"bool": {
"must": [{
"term": {
"xx": {
"value": "4622090581533787699",
"boost": 1.0
}
}
},
{
"range": {
"time": {
"from": 1548395063000,
"to": 1577256244000,
"include_lower": true,
"include_upper": true,
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"aggs": {
"group_by_source_id": {
"terms": {
"field": "sourceId",
"size": 2147483647,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": {
"_key": "desc"
}
},
"aggregations": {
"startTime": {
"min": {
"field": "time"
}
},
"endTime": {
"max": {
"field": "time"
}
},
"terms_count": {
"bucket_selector": {
"buckets_path": {
"count": "_count"
},
"script": {
"source": "params.count >= 2",
"lang": "painless"
},
"gap_policy": "skip"
}
},
"count_sort": {
"bucket_sort": {
"sort": [{
"_count": {
"order": "desc"
}
}],
"from": 0,
"size": 20,
"gap_policy": "SKIP"
}
}
}
}
}
}
参考于官方API:https://www.elastic.co/guide/en/elasticsearch/client/java-api/6.5/java-search-scrolling.html
(9)ES 游标查询
Client client = elasticsearchTemplate.getClient(); SearchResponse scrollResp = client.prepareSearch("index_name") .addSort("xxx", SortOrder.DESC) .setScroll(new TimeValue(60000)) .addDocValueField("xxx") // 需要查询出来的字段 .setSize(10000).get();// 每次查询出来的数据量 do { SearchHit[] hits = scrollResp.getHits().getHits(); if (hits != null && hits.length > 0) { List<XXX> xxx = esEventService.findSnapTimeAndImageCount(hits[hits.length - 1].field("aid").getValue().toString(),hits[0].field("xxx").getValue().toString()); if (!CollectionUtils.isEmpty(xxx)) { // TODO } } scrollResp = client.prepareSearchScroll(scrollResp.getScrollId()).setScroll(new TimeValue(60000)).execute().actionGet(); } while(scrollResp.getHits().getHits().length != 0);
4、使用过程遇到的坑
(1)插入问题
当有重复数据插入时,ES的插入是采用覆盖的方式,如何让他不覆盖某些字段呢?
当然你可以让不需要覆盖的字段不赋任何值,而且还不能为null,因为null其实也是分配了空间的,
其转为json仍然按有:xxx=null,所以此时仍然会覆盖,而且会被置为null,所以你想使用此方法必须
创建另一个对象,不需要覆盖的字段就不能还有此字段,比如使用Map,但是ElasticsearchRepository
的save方法并不支持你传map,因为ElasticsearchRepository是用泛型限制了,而且即使你指定Map泛型
但是也没法指定index等信息,所以在这样的窘境下,采用了ElasticsearchTemplate的update方法,而且
其支持upSert
(2)搭建集群时报错:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决方案:
切换到root用户
执行命令:
sysctl -w vm.max_map_count=262144
查看结果:
sysctl -a|grep vm.max_map_count
显示:
vm.max_map_count = 262144
上述方法修改之后,如果重启虚拟机将失效,所以:
解决办法:
在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
即可永久修改
(3)报错2:"discovery.zen.minimum_master_nodes" is too low
解决方案:
(4)报错3:org.elasticsearch.index.mapper.MapperParsingException: No type specified for field [feature_info]
解决方案:
@Data
@Document(indexName = "bigdata-event",type = "event",replicas = 0, shards = 1)
public class Event {
@Field(index = false,type = FieldType.Text)
private String feature_info;
...
注意如上代码,注意一:如果在字段上面加了@Field注解就务必加上type,否则就容易报如上的错;注意二:在class上的@Document注解上务必加上type否则就容易导致索引构建失败
(5)注意事项:discovery.zen.minimum_master_nodes参数设置是为了防止脑裂问题,一般设置为N/2 + 1 设置不当会报错
(6)报错4:Mapping definition for [dt] has unsupported parameters: [fielddata : true]
原因:fielddata = true 支持 text类型,不支持其他类型
(7)报错5:ElasticsearchException$1: Fielddata is disabled on text fields by default. Set fielddata=true on [aid] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.
原因:默认情况下text类型的数据,fielddata = false 的,所以在使用该text字段进行聚合的时候就会报这个错,错误中也给我们提出了两个解决方案:第一就是修改该字段的fielddata的值;第二就是将该字段的类型修改为keyword,但是es是不支持修改已存在的mapping的,所以需要重新创建一个index,然后将数据迁移至新的index
5、ES 集成 ik 插件
(1)下载ik插件zip包;注意下载ES版本相对应的ik包,否则报错,例如ES6.5.3就应该下载下面那个zip包
(2)将下载的zip包,解压至ES_HOME/plugins/ik下面,如果没有这个目录则手动创建

(3)重启ES
(4)检查是否成功
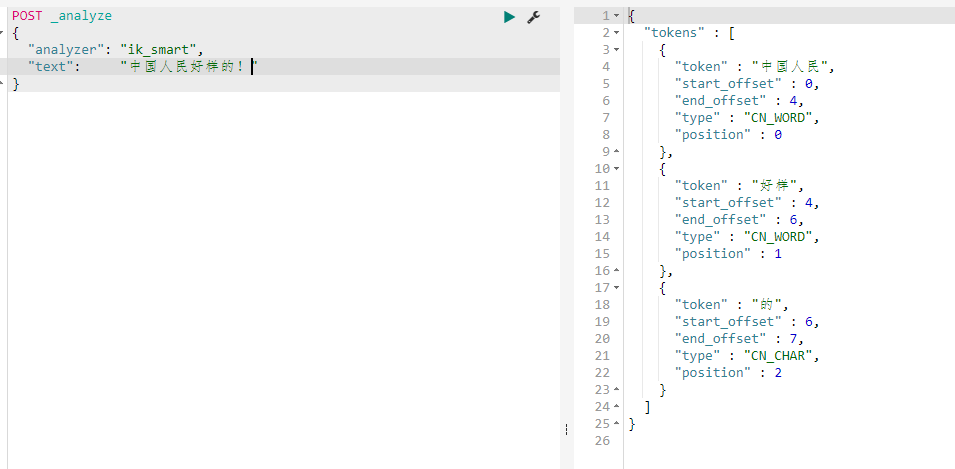
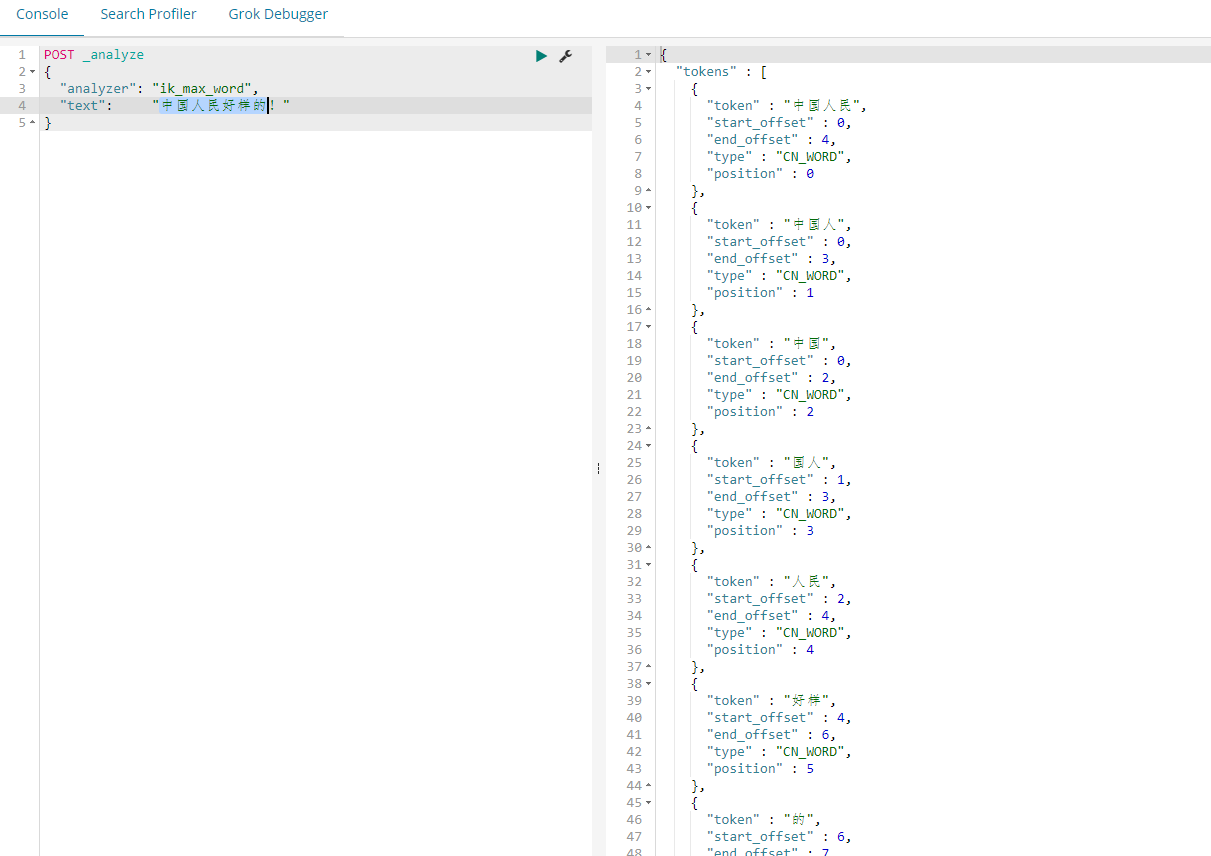
可以观察到分词效果
5、ES存储结构
(1)数据存储目录结构
data(path.data)
└── elasticsearch
?? ?└── nodes
????? └── 0
????????? ├── _state
????????? ├── indices
????????? │ ? └── global-0.st
????????? └── node.lock
ES默认是对所有字段进行索引的(也就是倒排索引)
ES基础参考:https://blog.csdn.net/define_us/article/details/81909374
ES脑裂问题详解:https://blog.csdn.net/kakaluoteyy/article/details/81068387
ES写入速度优化:https://www.easyice.cn/archives/207
6、Kibana连接ES集群(https://www.elastic.co/guide/en/kibana/6.4/production.html#load-balancing)
通常情况下ES是集群,即多个节点,但是kibana只支持连接一个节点。这样问题就来了,如果连接的那个节点挂掉了,则kibana也访问不了了,为了解决这个问题,ES官网提出了一个协调节点
此节点专门负责接收http请求即9200端口请求,它会选择地调用某个节点,也就是起到负载均衡的作用,具体操作参见官网:https://www.elastic.co/guide/en/kibana/6.4/production.html#load-balancing
7、ES分片相关
(1)如何查看index的分片数据分布情况,分布是否均匀
GET /_cat/shards/bigdata_archive?v
其中:bigdata_archive 为待查看的index名称;?v是显示scheme信息
注意:一般一个分片小不要超過 50G,如果超过了则需要增加分片数
(2)主分片只能在创建index的时候确定,一旦index创建完成之后是无法改变的。如果需要修改,则只能重新创建一个新的index副本,然后将数据迁移至新的index(注意:迁移的时候最好把老的index锁住,确保数据一致性)
POST _reindex?slices=5&refresh
{
"source": {
"remote": {
"host": "http://172.16.0.39:9200"
},
"index": "bigdata_event",
"size": 5000,
"query": {
// 过滤条件
}
},
"dest": {
"index": "bigdata_event_copy"
}
}
其中:size为批量迁移大小;slices=5为scroll的并行度,因为_reindex底层是通过scroll查询数据的
问题:往往数据量太大,_reindex效率会很低,所以需要做以下几个调整
- 合理设置size大小,一般5-15 MB
- 合理设置slices,slices等于分片数效率最快
- 将index的refresh设置为-1即禁止刷盘,数据转移完成之后改回去
- 将index的副本设置为0,数据转移完成之后改回去
- 可以加过滤条件,分批次转移数据
拓展:
查看_reindex进度:GET _tasks?detailed=true&actions=*reindex
取消_reindex:POST _tasks/node-0:1/_cancel
(3)elasticsearch的shard分布
- 手动移动分片
例如移动node-1的分片0到node-4
curl -XPOST 'http://localhost:9200/_cluster/reroute' -d '{
"commands":[{
"move":{
"index":"indexName",
"shard":0,
"from_node":"node-1",
"to_node":"node-4"
}}]}'
注意:分片和副本无法移动到同一个节点
8. ES参数调优
前提:查找问题方法
(1)查找占用CPU高的线程:GET _nodes/hot_threads 或 GET _nodes/node-0/hot_threads
调参:
(2)merge的线程数限制(因为merge会影响搜索。如果机械盘一般建议设置为1)
PUT /my_index/_settings
{
"index.merge.scheduler.max_thread_count": 1
}
(3)merge速度限制(因为merge会影响搜索。)
节点级别配置:
indices.store.throttle.type:merge
indices.store.throttle.max_bytes_per_sec:5mb //默认20mb
如上设置之后,该节点上的segments merge不会超过5mb/s
索引级别设置:
index.store.throttle.type:node
index.store.throttle.max_bytes_per_sec:10mb
如上设置是基于 索引的,可以跨多个节点。
(4)refresh_interval:如果实时性要求不高,则可合理设置此参数
(5)indices.memory.index_buffer_size:批量写入速度要求高,则可以调整此参数
9、ES 每个节点适合分配多少分片:https://www.cnblogs.com/shijingxiang/articles/11465446.html
10、ES 升级至6.8.0
说明:6.8.0版本的ES支持免费SSL,在此之前是要收费的
详细参看连接(单机):https://blog.csdn.net/qq_37461349/article/details/103047795
详细参看连接(集群):https://blog.csdn.net/shen12138/article/details/107016991/
详细参看连接(docker): https://www.cnblogs.com/a393060727/p/12469410.html
(1)错误:with the same id but is a different node instance
原因:不同的ES节点使用了同一个data目录
(2)Caused by: java.security.UnrecoverableKeyException: failed to decrypt safe contents entry: javax.crypto.BadPaddingException: Given final block not properly padded. Such issues can arise if a bad key is used during decryp
原因:证书有问题,重新生成即可
(3)logstash连接认证ES:https://www.cnblogs.com/wueryuan/p/13523833.html
11、 ES健康状态查询
详细参看连接:https://www.elastic.co/guide/cn/elasticsearch/guide/2.x/_cluster_health.html
12、APM
APM是Elasticsearch的一个服务监控平台
1) APM 快速搭建dokcer版:https://www.elastic.co/guide/en/apm/get-started/7.9/quick-start-overview.html
2)下载APM agent jar并运行:https://search.maven.org/search?q=a:elastic-apm-agent
java -javaagent:elastic-apm-agent-1.20.0.jar \ --apm java探针所在的路径 -Delastic.apm.service_name=person-file-manage \ --服务的命名 -Delastic.apm.server_url=http://192.168.13.82:8200 \ --apm-server的地址 -Delastic.apm.application_packages=com.intellif.cloud \ --要扫描的包名 -jar person-file-manage/person-file-manage.jar 2>&1 & --应用程序jar包
12、学习参考链接
(1)ES基础参考:https://blog.csdn.net/define_us/article/details/81909374
(2)ES脑裂问题详解:https://blog.csdn.net/kakaluoteyy/article/details/81068387
(3)ES写入速度优化:https://www.easyice.cn/archives/207
(4)ES java查询参考:https://blog.csdn.net/weixin_43310252/article/details/83752485 ;
以及官方JAVA api:https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/index.html
(5)mapping 属性解析参考:https://www.jianshu.com/p/8cef58be90ff
(6)IK集成参看:https://blog.csdn.net/q15102780705/article/details/101872729

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步