
Mysql底层解析及优化
Mysql的一个数据结构是B+树
所以所有的索引及数据都是存在叶子节点中的,默认的节点大小是16kb,所以它的每个节点可以放很多的索引,每个节点可以连接很多子节点,这种指数的增长就是mysql能进行千万级别检索的原因;
只看结论可能不理解,下面我给一个B+树结构图再加一个mysql实例讲解帮助理解:
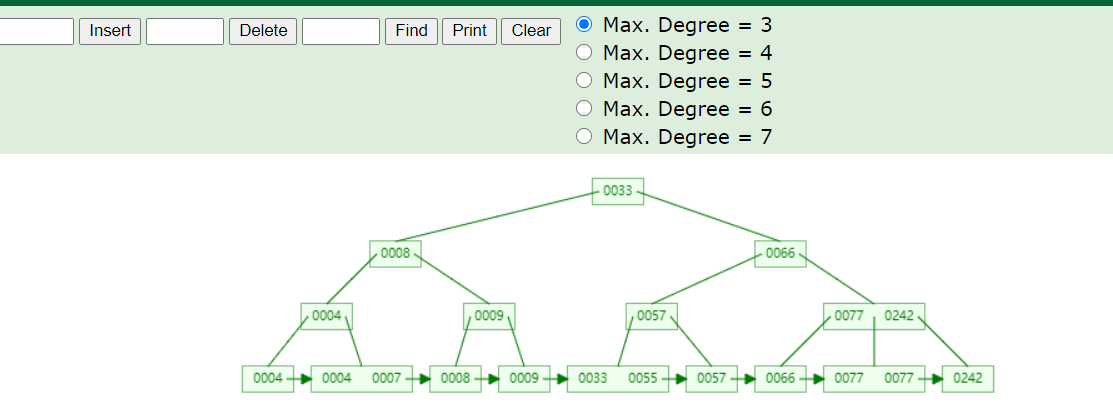
如图,就是一个max.degree为3的B+树,上面所说的节点大小16kb其实就会决定这个max.degree的值,叶子节点除了索引还有包括对应的数据,而上面的非叶子节点就只含有索引;我 这里加的索引并不好哈,有重复性的;
比如我们找一个索引为0055的,它会把0033这个节点加载到内存里,发现0055大于0033,找到0066,把0066加载到内存,比较发现比0066小,把0057加载到内存,比0057小,把叶子节点[0033\0055]加载到内存,找到0055索引并找到对应的value值,也就是对应数据值;
我们再做一个假设,我们每一个索引大小为10b,对应的数据为1kb,也就是数据库的每行数据大小为1kb,这样高度为3能存多少数据:
每个非叶子节点除了存索引,还有一个指向地址的指针,指针大小固定为6b,这样每个非叶子节点能存的索引就是16000b/(10+6)=1000个(max.degree为1000);也就是根节点能存1000个索引,而高度为2的节点也有1000,每个同样能存1000个索引,这样就是100W个索引了,到了第3行,就是叶子节点了(因为我们假设B+数的高度为3),叶子节点需要包括数据,所以每个节点只能存16kb/1kb=16个数据,最后得出高度为3的mysql b+树结构就可以存100W×16=1600W个数据了
理解了mysql的索引查找,再分析下存储引擎
我分别设置了两个数据库表对应比较常用的存储引擎:innodb和myisam,产生的数据文件如下:
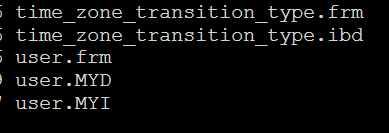
这个time表用的存储引擎是innodb,user表是myisam
后缀为frm的存储的就是表结构数据;
MYI是索引数据;MYD是表数据;Ibd是索引数据加表数据;
所以innodb和myisam的根本区别就是myisam在索引文件MYI里的叶子节点里存的是索引+磁盘引用地址,我们再根据这个地址去MYD文件找到对应的数据(稀疏索引);
而innodb里的ibd叶子节点存的是索引+表数据,这样我们在拿到索引时就能直接拿到数据(聚集索引)
很明显,我们更加提倡用innodb的存储结构,这样效率会更高;需要注意的是,这里的聚集索引指的是主键索引,如果是普通索引的话,查出来的叶子节点里是普通索引+主键索引,再通过主键索引去拿到数据,这是不符合聚集索引的定义的
mysql能不能不设定主键直接根据数据就建表?
可以,但是极不建议,因为如果不设置好主键索引,mysql为了保持这种B+树结构,会去查找你一个不重复字段来做你的索引,如果没有,会帮你自动创建一个隐藏的主键索引,这明显会消耗大量的资源,影响mysyl的效率,所以建表时切记要指定好主键索引
我们设定的主键为什么说建议用的整型+自增?
整型:是为了方便比较,通过上面的B+树介绍,我们在查找索引时是通过比较大小定位的,如果不是整型如uuid这种,每次在比较大小前都需要进行一次转换后再判断,是会影响到运算时间的,且整型所占的字节小,也就是索引值小,在同等查找次数下是可以存更多的索引的,因为mysql的B+树结构默认的节点大小是16kb;
自增:是为了更好地进行区间查询,这里要联合B+树和B树的区别,B+数其实就是在B数的基础上,对每个叶子节点之间增加了关联性,上图的B+树结构可以看到相邻的叶子节点是有箭头互相指向的,再思考索引的另一个索引方法: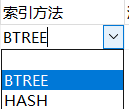 ,这里的HASH方法是指把我们字段里的数据在建立的时候就把其对应的索引地址指针计算出来,也就是当我们查找某个字段等价的值时,可以瞬间拿到索引地址,而实际开发业务中基本没有人会用HASH的索引方法,就是因为它没法适用于范围查找,没次范围查找都要遍历整个表;
,这里的HASH方法是指把我们字段里的数据在建立的时候就把其对应的索引地址指针计算出来,也就是当我们查找某个字段等价的值时,可以瞬间拿到索引地址,而实际开发业务中基本没有人会用HASH的索引方法,就是因为它没法适用于范围查找,没次范围查找都要遍历整个表;
除此之外,如果我们主键自增,那么在添加数据的时候能最大程度地减少节点分裂的情况,因为是自增主键,索引只会一直往后排,知道节点容量超出16KB再分裂,如果不是自增主键,你可能在插入数据的时候会为了保持b+树右大于左的特性,频繁地破坏改变B+树结构,这会使得我们插入查询效率都大大降低;
对于联合索引,比如A,B,C这3个字段做联合索引,那么在比较大小的时候会先按A、B、C字段依次比较,所以我们的查询条件要按最左缀原则去查询才会走索引,比如where A=xx and B=xx这种会走索引查询,如果是where C=xx这样的其实走的不是索引查询;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号