
java——补充基础知识(2)
注解:
注释会被编译器直接忽略,注解则可以被编译器打包进入class文件,因此,注解是一种用作标注的“元数据”。
3种:
被编译器识别的注解,如:@Override,这类注解不会被编译进入.class文件,它们在编译后就被编译器扔掉了。
由工具处理.class文件使用的注解,比如有些工具会在加载class的时候,对class做动态修改,实现一些特殊的功能。这类注解会被编译进入.class文件,但加载结束后并不会存在于内存中。这类注解只被一些底层库使用,一般我们不必自己处理。
在程序运行期能够读取的注解,它们在加载后一直存在于JVM中,这也是最常用的注解。这是Java代码读取该注解实现的功能,JVM并不会识别该注解
注解可以配置参数,没有指定配置的参数使用默认值;
配置参数可以包括:
- 所有基本类型;
- String;
- 枚举类型;
- 基本类型、String以及枚举的数组。
例:
public @interface Report { int type() default 0; String level() default "info"; String value() default ""; }
注解的参数类似无参数方法,可以用default设定一个默认值(强烈推荐)。最常用的参数应当命名为value。
元注解:用来注解注解的注解
@Target可以定义Annotation能够被应用于源码的哪些位置
- 类或接口:
ElementType.TYPE; - 字段:
ElementType.FIELD; - 方法:
ElementType.METHOD; - 构造方法:
ElementType.CONSTRUCTOR; - 方法参数:
ElementType.PARAMETER。
@Target也可由数组组成,定义多个位置
@Retention:定义了Annotation的生命周期:
- 仅编译期:
RetentionPolicy.SOURCE; - 仅class文件:
RetentionPolicy.CLASS; - 运行期:
RetentionPolicy.RUNTIME。
@Repeatable
使用@Repeatable这个元注解可以定义Annotation是否可重复。用 得不多
@Inherited
使用@Inherited定义子类是否可继承父类定义的Annotation。如果用了其子类是自动默认定义了该注解
@Inherited仅针对@Target(ElementType.TYPE)类型的annotation有效,并且仅针对class的继承,对interface的继承无效;
注解定义后也是一种class,所有的注解都继承自java.lang.annotation.Annotation,因此,读取注解,需要使用反射API。
判断某个注解是否存在于Class、Field、Method:
Class.isAnnotationPresent(Class)Field.isAnnotationPresent(Class)Method.isAnnotationPresent(Class)Constructor.isAnnotationPresent(Class)
例:
// 判断@Report是否存在于Person类: Person.class.isAnnotationPresent(Report.class);
使用反射API读取Annotation:
Class.getAnnotation(Class)Field.getAnnotation(Class)Method.getAnnotation(Class)Constructor.getAnnotation(Class)
例:
// 获取Person定义的@Report注解: Report report = Person.class.getAnnotation(Report.class); int type = report.type(); String level = report.level();
读取方法、字段和构造方法的Annotation和Class类似。但要读取方法参数的Annotation就比较麻烦一点,因为方法参数本身可以看成一个数组,而每个参数又可以定义多个注解,所以,一次获取方法参数的所有注解就必须用一个二维数组来表示。例如,对于以下方法定义的注解:
public void hello(@NotNull @Range(max=5) String name, @NotNull String prefix) { }
要读取方法参数的注解,我们先用反射获取Method实例,然后读取方法参数的所有注解:
// 获取Method实例: Method m = ... // 获取所有参数的Annotation: Annotation[][] annos = m.getParameterAnnotations(); // 第一个参数(索引为0)的所有Annotation: Annotation[] annosOfName = annos[0]; for (Annotation anno : annosOfName) { if (anno instanceof Range) { // @Range注解 Range r = (Range) anno; } if (anno instanceof NotNull) { // @NotNull注解 NotNull n = (NotNull) anno; }
泛型:
ArrayList内部就是一个Object[]数组,配合存储一个当前分配的长度,就可以充当“可变数组”
如果用上述ArrayList存储String类型 需要强制转型;将Object强制转为String
为了解决新的问题,我们必须把ArrayList变成一种模板:ArrayList<T>,代码如下:
public class ArrayList<T> { private T[] array; private int size; public void add(T e) {...} public void remove(int index) {...} public T get(int index) {...} }
T可以是任何class。这样一来,我们就实现了:编写一次模版,可以创建任意类型的ArrayList
注意:
泛型也可用于接口,如Arrays.sort(Object[])可以对任意数组进行排序,但待排序的元素必须实现Comparable<T>这个泛型接口:
public interface Comparable<T> { /** * 返回-1: 当前实例比参数o小 * 返回0: 当前实例与参数o相等 * 返回1: 当前实例比参数o大 */ int compareTo(T o); }
我们平时的String类可以直接使用这个排序方法,这是因为String本身已经实现了Comparable<String>接口,如果是自己定义的类,就要让这个类实现了Comparable<String>接口;
class Person implements Comparable<Person> { String name; int score; Person(String name, int score) { this.name = name; this.score = score; } public int compareTo(Person other) { return this.score-other.score; } public String toString() { return this.name + "," + this.score; } }
在compareTo方法中可以自定义排序规则;
泛型编写:对编写类注入多种泛型类型:例:
public class Pair<T, K> { private T first; private K last; public Pair(T first, K last) { this.first = first; this.last = last; } public T getFirst() { ... } public K getLast() { ... } }
使用的时候,需要指出两种类型:
Pair<String, Integer> p = new Pair<>("test", 123);
Java标准库的Map<K, V>就是使用两种泛型类型的例子。它对Key使用一种类型,对Value使用另一种类型。
Java的泛型是由编译器在编译时实行的,编译器内部其实把所有类型T视为Object处理,只不过在需要转型的时候,编译器会根据T的类型自动为我们实行安全地强制转型。因此Java的泛型是有局限性的:
局限一:<T>不能是基本类型,例如int,因为实际类型是Object,Object类型无法持有基本类型
局限二:无法取得带泛型的Class,因为T是Object,我们对Pair<String>和Pair<Integer>类型获取Class时,获取到的是同一个Class,也就是Pair类的Class。换句话说,所有泛型实例,无论T的类型是什么,getClass()返回同一个Class实例,因为编译后它们全部都是Pair<Object>。
局限三:不能实例化T类型的字段,如:
public class Pair<T> { private T first; private T last; public Pair() { // Compile error: first = new T(); last = new T(); } }
这里的first = new T()和last = new T()在编译时其实是first = new Object();last = new Object();这显然是不对的,需通过反射改正为:
public class Pair<T> { private T first; private T last; public Pair(Class<T> clazz) { first = clazz.newInstance(); last = clazz.newInstance(); } }
局限四:会造成不经意间的不恰当的覆写方法
如:
public class Pair<T> { public boolean equals(T t) { return this == t; } }
这里定义的equals(T t)方法实际上会被擦拭成equals(Object t),而这个方法是继承自Object的,编译器会阻止一个实际上会变成覆写的泛型方法定义。换个方法名就好
子类可以获取父类的泛型类型<T>。
我们无法获取Pair<T>的T类型,即给定一个变量Pair<Integer> p,无法从p中获取到Integer类型。
但是,在父类是泛型类型的情况下,编译器就必须把类型T(对IntPair来说,也就是Integer类型)保存到子类的class文件中,不然编译器就不知道IntPair只能存取Integer这种类型。这样,我们就可以获取父类的泛型类型了
上面就有提及Pair<Integer>和Pair<Number>两者完全没有继承关系,也不能向上转型;那如果指定传入的参数是ArrayList<Number>,那怎么才可以传入ArrayList<Integer>实例而不报错?
可以使用上界通配符 Pair<? extends Number>,即把泛型类型T的上界限定在Number了;
但是,<? extends Number>通配符的一个重要限制:方法参数签名setFirst(? extends Number)无法传递任何Number类型给setFirst(? extends Number)。
使用类似<? extends Number>通配符作为方法参数时表示:
-
方法内部可以调用获取
Number引用的方法,例如:Number n = obj.getFirst();; -
方法内部无法调用传入
Number引用的方法(null除外),例如:obj.setFirst(Number n);。
即一句话总结:使用extends通配符表示可以读,不能写。
使用类似<T extends Number>定义泛型类时表示:
- 泛型类型限定为
Number以及Number的子类。
与<? extends Number>相反的 是<? super Integer>,方法参数接受所有泛型类型为Integer或Integer父类的Pair类型。
使用<? super Integer>通配符表示:
-
允许调用
set(? super Integer)方法传入Integer的引用; -
不允许调用
get()方法获得Integer的引用。
唯一例外是可以获取Object的引用:Object o = p.getFirst()。
换句话说,使用<? super Integer>通配符作为方法参数,表示方法内部代码对于参数只能写,不能读。
无限定通配符
<?>通配符既没有extends,也没有super,因此:
- 不允许调用
set(T)方法并传入引用(null除外); - 不允许调用
T get()方法并获取T引用(只能获取Object引用)。
换句话说,既不能读,也不能写
<?>通配符有一个独特的特点,就是:Pair<?>是所有Pair<T>的超类,因此可以向上转型:
Pair<Integer> p = new Pair<>(123, 456); Pair<?> p2 = p; // 安全地向上转型
我们可以声明带泛型的数组,但不能用new操作符创建带泛型的数组:
Pair<String>[] ps = null; // ok
Pair<String>[] ps = new Pair<String>[2]; // compile error!
必须通过强制转型实现带泛型的数组:
@SuppressWarnings("unchecked")
Pair<String>[] ps = (Pair<String>[]) new Pair[2];
部分反射API是泛型,例如:Class<T>,Constructor<T>;
可以声明带泛型的数组,但不能直接创建带泛型的数组,必须强制转型;
可以通过Array.newInstance(Class<T>, int)创建T[]数组,需要强制转型;
集合
java集合使用统一的Iterator遍历
实现List接口并非只能通过数组(即ArrayList的实现方式)来实现,另一种LinkedList通过“链表”也实现了List接口。在LinkedList中,它的内部每个元素都指向下一个元素,对比ArrayList和LinkedList类:
| ArrayList | LinkedList | |
|---|---|---|
| 获取指定元素 | 速度很快 | 需要从头开始查找元素 |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加/删除 | 需要移动元素 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
通常情况下,我们总是优先使用ArrayList。
使用Iterator遍历List代码如下:
for (Iterator<String> it = list.iterator(); it.hasNext(); ) { String s = it.next()};
使用for each循环本身也是使用了Iterator遍历
覆写equals:
- 先确定实例“相等”的逻辑,即哪些字段相等,就认为实例相等;
- 用
instanceof判断传入的待比较的Object是不是当前类型,如果是,继续比较,否则,返回false; - 对引用类型用
Objects.equals()比较,对基本类型直接用==比较。
使用Objects.equals()比较两个引用类型是否相等的目的是省去了判断null的麻烦。两个引用类型都是null时它们也是相等的。
例:有一个People类:
public class Person { public String name; public int age; }
覆写equals:
public boolean equals(Object o) { if (o instanceof Person) { Person p = (Person) o; return this.name.equals(p.name) && this.age == p.age; } return false; }
Map<K, V>想查询某个key是否存在,可以调用boolean containsKey(K key)方法
重复放入key-value并不会有任何问题,但是一个key只能关联一个value。如果放入的key已经存在,put()方法会返回被删除的旧的value
在一个Map中,虽然key不能重复,但value是可以重复的
对Map来说,要遍历key可以使用for each循环遍历Map实例的keySet()方法返回的Set集合,它包含不重复的key的集合:再通过for (String key : map.keySet())进行遍历;
也可以遍历整个key-value,通过entrySet()返回集合,原理一样
由于key是不重复的,所以如果key是一个对象,那也要保证该对象正确地覆写equals方法,要不然会出现内容相同但不是同个实例对象的key所取得的value是不同的;
key取value是通过hashCode()取得正确的索引(int)后,再对应到正确的value的
编写hashCode()遵循的原则是:
equals()用到的用于比较的每一个字段,都必须在hashCode()中用于计算;equals()中没有使用到的字段,绝不可放在hashCode()中计算。例:
public class Person { String firstName; String lastName; int age; @Override int hashCode() { int h = 0; h = 31 * h + firstName.hashCode(); h = 31 * h + lastName.hashCode(); h = 31 * h + age; return h; } }
这是通过空间换时间的方式;
默认的HashMap大小是16个,如果数组不够用就会自动扩容一倍,
由于扩容会导致重新分布已有的key-value,所以,频繁扩容对HashMap的性能影响很大。如果我们确定要使用一个容量为10000个key-value的HashMap,更好的方式是创建HashMap时就指定容量:
Map<String, Integer> map = new HashMap<>(10000);
虽然指定容量是10000,但HashMap内部的数组长度总是2n,因此,实际数组长度被初始化为比10000大的16384(2的14次方)。
如果不同key通过HashMap计算出来的key很不辛得相同,那也不会覆盖原有的value,因为储存的value是以List方式储存的,因此如果算出来的索引相同得越多,这个List就越长,Map的效率就越低;
如果作为key的对象是enum类型,那么,还可以使用Java集合库提供的一种EnumMap,它在内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。
还有一种Map,它在内部会对Key进行排序,这种Map就是SortedMap。注意到SortedMap是接口,它的实现类是TreeMap。使用TreeMap时,放入的Key必须实现Comparable接口。但并未覆写equals()和hashCode(),因为TreeMap不使用equals()和hashCode()。
TreeMap在比较两个Key是否相等时,依赖Key的compareTo()方法或者Comparator.compare()方法
Java集合库提供了一个Properties来表示一组“配置”
String f = "setting.properties"; Properties props = new Properties(); props.load(new java.io.FileInputStream(f)); String filepath = props.getProperty("last_open_file"); String interval = props.getProperty("auto_save_interval", "120");
可见,用Properties读取配置文件,一共有三步:
- 创建
Properties实例; - 调用
load()读取文件; - 调用
getProperty()获取配置。
也可以从classpath读取.properties文件,因为load(InputStream)方法接收一个InputStream实例,表示一个字节流,它不一定是文件流,也可以是从jar包中读取的资源流:
Properties props = new Properties(); props.load(getClass().getResourceAsStream("/common/setting.properties"));
如果有多个.properties文件,可以反复调用load()读取,后读取的key-value会覆盖已读取的key-value;
如果通过setProperty()修改了Properties实例,可以把配置写入文件,以便下次启动时获得最新配置。写入配置文件使用store()方法:
Properties props = new Properties(); props.setProperty("url", "http://www.liaoxuefeng.com"); props.setProperty("language", "Java"); props.store(new FileOutputStream("C:\\conf\\setting.properties"), "这是写入的properties注释");
Set用于存储不重复的元素集合:
- 放入
HashSet的元素与作为HashMap的key要求相同; - 放入
TreeSet的元素与作为TreeMap的Key要求相同;
利用Set可以去除重复元素;
遍历SortedSet按照元素的排序顺序遍历,也可以自定义排序算法。
队列(Queue)是一种经常使用的集合。Queue实际上是实现了一个先进先出(FIFO:First In First Out)的有序表。它和List的区别在于,List可以在任意位置添加和删除元素,而Queue只有两个操作:
- 把元素添加到队列末尾;
- 从队列头部取出元素。
在Java的标准库中,队列接口Queue定义了以下几个方法:
int size():获取队列长度;boolean add(E)/boolean offer(E):添加元素到队尾;E remove()/E poll():获取队首元素并从队列中删除;E element()/E peek():获取队首元素但并不从队列中删除。
前者方法失败时会抛出异常,而后者方法会返回false;
不要把null添加到队列中,否则poll()方法返回null时,很难确定是取到了null元素还是队列为空。
我们还可以发现,LinkedList即实现了List接口,又实现了Queue接口,但是,在使用的时候,如果我们把它当作List,就获取List的引用,如果我们把它当作Queue,就获取Queue的引用:
// 这是一个List: List<String> list = new LinkedList<>(); // 这是一个Queue: Queue<String> queue = new LinkedList<>();
PriorityQueue实现了一个优先队列:从队首获取元素时,总是获取优先级最高的元素。
PriorityQueue默认按元素比较的顺序排序(必须实现Comparable接口),也可以通过Comparator自定义排序算法(元素就不必实现Comparable接口)。
Java集合提供了接口Deque来实现一个双端队列,它的功能是:
- 既可以添加到队尾,也可以添加到队首;
- 既可以从队首获取,又可以从队尾获取。
Deque接口实际上扩展自Queue,Queue提供的add()/offer()方法在Deque中也可以使用,但最好还是调用xxxFirst()/xxxLast()以便与Queue的方法区分开:
- 将元素添加到队尾或队首:
addLast()/offerLast()/addFirst()/offerFirst(); - 从队首/队尾获取元素并删除:
removeFirst()/pollFirst()/removeLast()/pollLast(); - 从队首/队尾获取元素但不删除:
getFirst()/peekFirst()/getLast()/peekLast();
Stack只有入栈和出栈的操作:
- 把元素压栈:
push(E); - 把栈顶的元素“弹出”:
pop(E); - 取栈顶元素但不弹出:
peek(E)。
在Java中,我们用Deque可以实现Stack的功能:
- 把元素压栈:
push(E)/addFirst(E); - 把栈顶的元素“弹出”:
pop(E)/removeFirst(); - 取栈顶元素但不弹出:
peek(E)/peekFirst()。
Stack在计算机中使用非常广泛,JVM在处理Java方法调用的时候就会通过栈这种数据结构维护方法调用的层次,方法调用栈有容量限制,嵌套调用过多会造成栈溢出,即引发StackOverflowError;
对于整数进行进制的转换也可以利用栈,10转16进制,如:33÷16=2...1;2÷16=0...2;这里的余数1、2会按顺序存在栈中,当商是0的时候结束运算,取出2、1,即后存的2先取,这里用到的就是栈;
迭代器:
for (Iterator<String> it = list.iterator(); it.hasNext(); ) { String s = it.next(); System.out.println(s); }
如果我们自己编写了一个集合类,想要使用for each循环,只需满足以下条件:
- 集合类实现
Iterable接口,该接口要求返回一个Iterator对象; - 用
Iterator对象迭代集合内部数据。
Collecttions类:
Collections提供了一系列方法来创建空集合:
- 创建空List:
List<T> emptyList() - 创建空Map:
Map<K, V> emptyMap() - 创建空Set:
Set<T> emptySet()
要注意到返回的空集合是不可变集合,无法向其中添加或删除元素。
List<String> list2 = Collections.emptyList();
Collections提供了一系列方法来创建一个单元素集合:
- 创建一个元素的List:
List<T> singletonList(T o) - 创建一个元素的Map:
Map<K, V> singletonMap(K key, V value) - 创建一个元素的Set:
Set<T> singleton(T o)
要注意到返回的单元素集合也是不可变集合,无法向其中添加或删除元素。
List<String> list1 = List.of("apple");
List<String> list2 = Collections.singletonList("apple");
Collections可以对List进行排序。因为排序会直接修改List元素的位置,因此必须传入可变List:
Collections.sort(list);
可以随机打乱List内部元素的顺序:
Collections.shuffle(list);
把可变集合封装成不可变集合:
- 封装成不可变List:
List<T> unmodifiableList(List<? extends T> list) - 封装成不可变Set:
Set<T> unmodifiableSet(Set<? extends T> set) - 封装成不可变Map:
Map<K, V> unmodifiableMap(Map<? extends K, ? extends V> m)
这种封装实际上是通过创建一个代理对象,拦截掉所有修改方法实现的。
List<String> immutable = Collections.unmodifiableList(mutable);
然而,继续对原始的可变List进行增删是可以的,并且,会直接影响到封装后的“不可变”List:
mutable.add("orange");//原始的mutable数组
Collections还提供了一组方法,可以把线程不安全的集合变为线程安全的集合:
- 变为线程安全的List:
List<T> synchronizedList(List<T> list) - 变为线程安全的Set:
Set<T> synchronizedSet(Set<T> s) - 变为线程安全的Map:
Map<K,V> synchronizedMap(Map<K,V> m)
因为从Java 5开始,引入了更高效的并发集合类,所以上述这几个同步方法已经没有什么用了。
File对象有一个静态变量用于表示当前平台的系统分隔符:
System.out.println(File.separator); // 根据当前平台打印"\"或"/"
File对象有3种形式表示的路径,一种是getPath(),返回构造方法传入的路径,一种是getAbsolutePath(),返回绝对路径,一种是getCanonicalPath,它和绝对路径类似,但是返回的是规范路径。
规范路径就是把.和..转换成标准的绝对路径后的路径,如:
绝对路径可以表示成C:\Windows\System32\..\notepad.exe,规范路径就是C:\Windows\notepad.exe。
用File对象获取到一个文件时,还可以进一步判断文件的权限和大小:
boolean canRead():是否可读;boolean canWrite():是否可写;boolean canExecute():是否可执行;long length():文件字节大小。
对目录而言,是否可执行表示能否列出它包含的文件和子目录。
构造一个File对象,即使传入的文件或目录不存在,代码也不会出错,因为构造一个File对象,并不会导致任何磁盘操作。只有当我们调用File对象的某些方法的时候,才真正进行磁盘操作。
当File对象表示一个文件时,可以通过createNewFile()创建一个新文件,用delete()删除该文件;
File对象提供了createTempFile()来创建一个临时文件,以及deleteOnExit()在JVM退出时自动删除该文件:
File f = File.createTempFile("tmp-", ".txt"); // 提供临时文件的前缀和后缀
f.deleteOnExit(); // JVM退出时自动删除
和文件操作类似,File对象如果表示一个目录,可以通过以下方法创建和删除目录:
boolean mkdir():创建当前File对象表示的目录;boolean mkdirs():创建当前File对象表示的目录,并在必要时将不存在的父目录也创建出来;boolean delete():删除当前File对象表示的目录,当前目录必须为空才能删除成功。
当File对象表示一个目录时,可以使用list()和listFiles()列出目录下的文件和子目录名;
InputStream并不是一个接口,而是一个抽象类,它是所有输入流的超类。这个抽象类定义的一个最重要的方法就是int read(),签名如下:
public abstract int read() throws IOException;
这个方法会读取输入流的下一个字节,并返回字节表示的int值(0~255)。如果已读到末尾,返回-1表示不能继续读取了。
如果读取过程中发生了IO错误,InputStream就没法正确地关闭,资源也就没法及时释放,因此,我们需要用try ... finally来保证InputStream在无论是否发生IO错误的时候都能够正确地关闭;
InputStream提供了两个重载方法来支持读取多个字节(缓冲):
int read(byte[] b):读取若干字节并填充到byte[]数组,返回读取的字节数int read(byte[] b, int off, int len):指定byte[]数组的偏移量和最大填充数
read()方法的返回值不再是字节的int值,而是返回实际读取了多少个字节。如果返回-1,表示没有更多的数据了。
和InputStream类似,OutputStream也是抽象类,它是所有输出流的超类。这个抽象类定义的一个最重要的方法就是void write(int b),签名如下:
public abstract void write(int b) throws IOException;
这个方法会写入一个字节到输出流。要注意的是,虽然传入的是int参数,但只会写入一个字节,即只写入int最低8位表示字节的部分(相当于b & 0xff)。
OutputStream还提供了一个flush()方法,它的目的是将缓冲区的内容真正输出到目的地。
ava的IO标准库提供的InputStream根据来源可以包括:
FileInputStream:从文件读取数据,是最终数据源;ServletInputStream:从HTTP请求读取数据,是最终数据源;Socket.getInputStream():从TCP连接读取数据,是最终数据源;- ....
为了给基础的InputStream附加各种功能,如果用继承的方式扩展方法所用到的子类就会越来越多,导致子类数量失控,因此JDK把InputStream分为两大类:
一类是直接提供数据的基础InputStream,例如:
- FileInputStream
- ByteArrayInputStream
- ServletInputStream
- ...
一类是提供额外附加功能的InputStream,例如:
- BufferedInputStream
- DigestInputStream
- CipherInputStream
- ...
可以基础的InputStream实例放入提供额外服务的InputStram对象中再实例化,如:
InputStream file = new FileInputStream("test.gz");
InputStream buffered = new BufferedInputStream(file);
上述这种通过一个“基础”组件再叠加各种“附加”功能组件的模式,称之为Filter模式(或者装饰器模式:Decorator)
接口的基础关系如下:
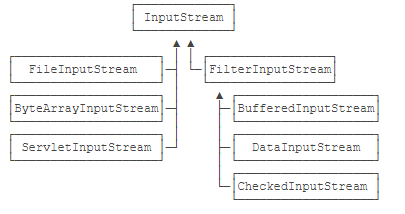
因此我们如果要编写自己的服务类时需要继承FilterInputStream接口;
OutputStream也有着类似的关系接口图;
把资源存储在classpath中可以避免文件路径依赖;
Class对象的getResourceAsStream()可以从classpath中读取指定资源;
根据classpath读取资源时,需要检查返回的InputStream是否为null。
Reader是Java的IO库提供的另一个输入流接口。和InputStream的区别是,InputStream是一个字节流,即以byte为单位读取,而Reader是一个字符流,即以char为单位读取;
要避免乱码问题,我们需要在创建FileReader时指定编码:
Reader reader = new FileReader("src/readme.txt", StandardCharsets.UTF_8);
Reader本质上是一个基于InputStream的byte到char的转换器,如果我们查看FileReader的源码,它在内部实际上持有一个FileInputStream。
也可以通过:
try (Reader reader = new InputStreamReader(new FileInputStream("src/readme.txt"), "UTF-8")) { // TODO: }
创造Reader类,其中InputStreamReader类其实就是把字节输入流转换为字符输入流的一个转换器;FileReader其实就是封装了这个过程而已;
Writer跟Reader在设计上理念基本是一致的,总结:
Writer定义了所有字符输出流的超类:
-
FileWriter实现了文件字符流输出; -
使用
try (resource)保证Writer正确关闭。 Writer是基于OutputStream构造的,可以通过OutputStreamWriter将OutputStream转换为Writer,转换时需要指定编码
PrintStream和PrintWriter
PrintStream是一种FilterOutputStream,它在OutputStream的接口上,额外提供了一些写入各种数据类型的方法:
- 写入
int:print(int) - 写入
boolean:print(boolean) - 写入
String:print(String) - 写入
Object:print(Object)
System.out是系统默认提供的PrintStream;
PrintStream是一种能接收各种数据类型的输出,打印数据时比较方便:
System.out是标准输出;System.err是标准错误输出。
PrintWriter是基于Writer的输出。
自定义日期格式:
public class Main { public static void main(String[] args) { // 获取当前时间: Date date = new Date(); var sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); System.out.println(sdf.format(date)); } }
JUnit测试
例:
@Test void testFact() { assertEquals(1, Factorial.fact(1));}
assertEquals(expected, actual)是最常用的测试方法,它在Assertion类中定义。Assertion还定义了其他断言方法,例如:
assertTrue(): 期待结果为trueassertFalse(): 期待结果为falseassertNotNull(): 期待结果为非nullassertArrayEquals(): 期待结果为数组并与期望数组每个元素的值均相等- ...
在测试的时候,我们经常遇到一个对象需要初始化,如果有多个@Test的话每个都要实例化就很麻烦,JUnit测试可以通过@BeforeEach来初始化,通过@AfterEach来清理资源;
被标记为@BeforeEach和@AfterEach的方法,它们会在运行每个@Test方法前后自动运行。
还有一些资源初始化和清理可能更加繁琐,而且会耗费较长的时间,例如初始化数据库。JUnit还提供了@BeforeAll和@AfterAll,它们在运行所有@Test前后运行:
因为@BeforeAll和@AfterAll在所有@Test方法运行前后仅运行一次,因此,它们只能初始化静态变量,如:
public class DatabaseTest { static Database db; @BeforeAll public static void initDatabase() { db = createDb(...); } @AfterAll public static void dropDatabase() { ... } }
注意到每次运行一个@Test方法前,JUnit首先创建一个XxxTest实例,因此,每个@Test方法内部的成员变量都是独立的,不能也无法把成员变量的状态从一个@Test方法带到另一个@Test方法。
异常测试:
源码如果想指定抛出某些异常:
if (n < 0) { throw new IllegalArgumentException(); }
在测试时可这样编写:
@Test void testNegative() { assertThrows(IllegalArgumentException.class, () -> { Factorial.fact(-1); }); }
上述奇怪的->语法就是函数式接口的实现代码;当我们执行Factorial.fact(-1)时,必定抛出IllegalArgumentException。assertThrows()在捕获到指定异常时表示通过测试,未捕获到异常,或者捕获到的异常类型不对,均表示测试失败。
条件测试:在运行测试的时候,有些时候,我们需要排出某些@Test方法,不要让它运行,这时,我们就可以给它标记一个@Disabled,
万能的@EnableIf可以执行任意Java语句并根据返回的boolean决定是否执行测试;下面的代码演示了一个只能在星期日执行的测试:
@Test @EnabledIf("java.time.LocalDate.now().getDayOfWeek()==java.time.DayOfWeek.SUNDAY") void testOnlyOnSunday() { // TODO: this test is only run on Sunday }
参数化测试:
JUnit提供了一个@ParameterizedTest注解,用来进行参数化测试,即通过一组参数进行重复的测试:
如果传入只有一种参数可用@ValueSource:
@ParameterizedTest @ValueSource(ints = { 0, 1, 5, 100 }) void testAbs(int x) { assertEquals(x, Math.abs(x)); }
如果根据传入会导致不同的不同的传出,即Test需要接受两个参数,可以使用@CsvSource,它的每一个字符串表示一行,一行包含的若干参数:
@ParameterizedTest @CsvSource({ "abc, Abc", "APPLE, Apple", "gooD, Good" }) void testCapitalize(String input, String result) { assertEquals(result, StringUtils.capitalize(input)); }
这里的input就是传入的参数,result就是通过capitalize方法运行后返回的值,判断是否一致;
如果有成百上千的测试输入,那么,直接写@CsvSource就很不方便。这个时候,我们可以把测试数据提到一个独立的CSV文件中,然后标注上@CsvFileSource:
@ParameterizedTest @CsvFileSource(resources = { "/test-capitalize.csv" }) void testCapitalizeUsingCsvFile(String input, String result) { assertEquals(result, StringUtils.capitalize(input)); }
正则表达式在Java代码中也是一个字符串,因此如果正则表达式有特殊字符,那就需要用\转义
如果正则表达式有特殊字符,那就需要用\转义。例如,正则表达式a\&c,其中\&是用来匹配特殊字符&的,它能精确匹配字符串"a&c",如:
String re2 = "a\\&c"; // 对应的正则是a\&c System.out.println("a&c".matches(re2));
最后的输出是true,因为字符串re2对应的正则是a\&c,而再拿这个正则来匹配对应的就是a&c;
单个字符的匹配规则如下:
| 正则表达式 | 规则 | 可以匹配 |
|---|---|---|
A |
指定字符 | A |
\u548c |
指定Unicode字符 | 和 |
. |
任意字符 | a,b,&,0 |
\d |
数字0~9 | 0~9 |
\w |
大小写字母,数字和下划线 | a~z,A~Z,0~9,_ |
\s |
空格、Tab键 | 空格,Tab |
\D |
非数字 | a,A,&,_,…… |
\W |
非\w | &,@,中,…… |
\S |
非\s | a,A,&,_,…… |
多个字符的匹配规则如下:
| 正则表达式 | 规则 | 可以匹配 |
|---|---|---|
A* |
任意个数字符 | 空,A,AA,AAA,…… |
A+ |
至少1个字符 | A,AA,AAA,…… |
A? |
0个或1个字符 | 空,A |
A{3} |
指定个数字符 | AAA |
A{2,3} |
指定范围个数字符 | AA,AAA |
A{2,} |
至少n个字符 | AA,AAA,AAAA,…… |
A{0,3} |
最多n个字符 | 空,A,AA,AAA |
分组匹配(提取表达式里的某一部分):
java里预留了一个regex库,方便于我们在java里操作正则表达式,比较常用的就是 Pattern 和 Matcher ,pattern是一个编译好的正则表达式,而Mather是一个正则表达式适配器,Mather的功能很强大,所以我们一般用pattern 来获取一个Matcher对象,然后用Matcher来操作正则表达式,就可以直接从Matcher.group(index)返回子串.例:
Pattern p = Pattern.compile("(\\d{3,4})\\-(\\d{7,8})"); Matcher m = p.matcher("010-12345678"); if (m.matches()) { String g1 = m.group(1)};//010
使用Matcher时,必须首先调用matches()判断是否匹配成功,匹配成功后,才能调用group()提取子串。
注意:当group传入0参数时,匹配到的就是整个正则表达式;
正则表达式默认使用贪婪匹配:任何一个规则,它总是尽可能多地向后匹配,
非贪婪匹配,尽可能少的匹配,给定一个匹配规则,加上?后就变成了非贪婪匹配,例:
(\d??)(9*),给定字符串“9999”,贪婪匹配的话会分组为“9999”和“”,非贪婪匹配的话是“”和“9999”;
搜索字符串:
String s = "the quick brown fox jumps over the lazy dog."; Pattern p = Pattern.compile("\\wo\\w"); Matcher m = p.matcher(s); while (m.find()) { String sub = s.substring(m.start(), m.end())};
反复调用find()方法,在整个串中搜索能匹配上\\wo\\w规则的子串;
替换字符串:可以直接调用String.replaceAll()
String s = "The quick\t\t brown fox jumps over the lazy dog."; String r = s.replaceAll("\\s+", " "); System.out.println(r); // "The quick brown fox jumps over the lazy dog."
反向引用:
String s = "the quick brown fox jumps over the lazy dog."; String r = s.replaceAll("\\s([a-z]{4})\\s", " <b>$1</b> "); System.out.println(r);//the quick brown fox jumps <b>over</b> the <b>lazy</b> dog.
可以使用$1、$2来反向引用匹配到的子串;
编码:
URL编码和Base64编码都是编码算法,它们不是加密算法;
URL编码的目的是把任意文本数据编码为%前缀表示的文本,便于浏览器和服务器处理;
Base64编码的目的是把任意二进制数据编码为文本,但编码后数据量会增加1/3。
哈希算法最重要的特点就是:
- 相同的输入一定得到相同的输出;
- 不同的输入大概率得到不同的输出。
两个相同的字符串永远会计算出相同的hashCode,否则基于hashCode定位的HashMap就无法正常工作
对输入值转为哈希值:
public class Main { public static void main(String[] args) throws Exception { // 创建一个MessageDigest实例: MessageDigest md = MessageDigest.getInstance("MD5"); // 反复调用update输入数据: md.update("HelloWorld".getBytes("UTF-8")); byte[] result = md.digest(); // 16 bytes: 68e109f0f40ca72a15e05cc22786f8e6 System.out.println(new BigInteger(1, result).toString(16)); } }
Java标准库提供了一系列常用的哈希算法;
BouncyCastle是一个开源的第三方算法提供商;
BouncyCastle提供了很多Java标准库没有提供的哈希算法和加密算法;
使用第三方算法前需要通过Security.addProvider()注册。
和多线程相比,多进程的缺点在于:
- 创建进程比创建线程开销大,尤其是在Windows系统上;
- 进程间通信比线程间通信要慢,因为线程间通信就是读写同一个变量,速度很快。
而多进程的优点在于:
多进程稳定性比多线程高,因为在多进程的情况下,一个进程崩溃不会影响其他进程,而在多线程的情况下,任何一个线程崩溃会直接导致整个进程崩溃。
Java语言内置了多线程支持。当Java程序启动的时候,实际上是启动了一个JVM进程,然后,JVM启动主线程来执行main()方法。在main()方法中,我们又可以启动其他线程。
启动线程且定义方法的两种方法:
方法一:从Thread派生一个自定义类,然后覆写run()方法:
public class Main { public static void main(String[] args) { Thread t = new MyThread(); t.start(); // 启动新线程 } } class MyThread extends Thread { @Override public void run() { System.out.println("start new thread!"); } }
方法二:创建Thread实例时,传入一个Runnable实例:
public class Main { public static void main(String[] args) { Thread t = new Thread(new MyRunnable()); t.start(); // 启动新线程 } } class MyRunnable implements Runnable { @Override public void run() { System.out.println("start new thread!"); } }
直接调用run()方法,相当于调用了一个普通的Java方法,当前线程并没有任何改变,也不会启动新线程。必须调用Thread实例的start()方法才能启动新线程。
start()方法内部调用了一个private native void start0()方法,native修饰符表示这个方法是由JVM虚拟机内部的C代码实现的,不是由Java代码实现的。
可以对线程设定优先级,设定优先级的方法是:
Thread.setPriority(int n) // 1~10, 默认值5
优先级高的线程被操作系统调度的优先级较高,操作系统对高优先级线程可能调度更频繁,但我们决不能通过设置优先级来确保高优先级的线程一定会先执行。
在Java程序中,一个线程对象只能调用一次start()方法启动新线程,并在新线程中执行run()方法。一旦run()方法执行完毕,线程就结束了。因此,Java线程的状态有以下几种:
- New:新创建的线程,尚未执行;
- Runnable:运行中的线程,正在执行
run()方法的Java代码; - Blocked:运行中的线程,因为某些操作被阻塞而挂起;
- Waiting:运行中的线程,因为某些操作在等待中;
- Timed Waiting:运行中的线程,因为执行
sleep()方法正在计时等待; - Terminated:线程已终止,因为
run()方法执行完毕。
当线程启动后,它可以在Runnable、Blocked、Waiting和Timed Waiting这几个状态之间切换,直到最后变成Terminated状态,线程终止。
线程终止的原因有:
- 线程正常终止:
run()方法执行到return语句返回; - 线程意外终止:
run()方法因为未捕获的异常导致线程终止; - 对某个线程的
Thread实例调用stop()方法强制终止(强烈不推荐使用)。
main线程在启动t线程后,可以通过t.join()等待t线程结束后再继续运行:
public class Main { public static void main(String[] args) throws InterruptedException { Thread t = new Thread(() -> { System.out.println("hello"); }); System.out.println("start"); t.start(); t.join(); System.out.println("end"); } }
进程main会在线程t执行完再进行,也就是打印“end”必定在打印“hello”之后;
中断线程:
在其他线程中对目标线程调用interrupt()方法,目标线程需要反复检测自身状态是否是interrupted状态,如果是,就立刻结束运行。
如果处于join状态的线程被强制interrupt()中断了,会抛出InterruptedException异常;
另一个常用的中断线程的方法是设置标志位。我们通常会用一个running标志位来标识线程是否应该继续运行,在外部线程中,通过把HelloThread.running置为false,就可以让线程结束:
public class Main { public static void main(String[] args) throws InterruptedException { HelloThread t = new HelloThread(); t.start(); Thread.sleep(1); t.running = false; // 标志位置为false } } class HelloThread extends Thread { public volatile boolean running = true; public void run() { int n = 0; while (running) { n ++; System.out.println(n + " hello!"); } System.out.println("end!"); } }
线程间共享变量需要使用volatile关键字标记,确保每个线程都能读取到更新后的变量值。
虚拟机变量在内存分配类似下图:

当线程访问变量时,它会先获取一个副本,并保存在自己的工作内存中。如果线程修改了变量的值,虚拟机会在某个时刻把修改后的值回写到主内存,但这个时间是不确定的;
volatile关键字的目的是告诉虚拟机:
- 每次访问变量时,总是获取主内存的最新值;
- 每次修改变量后,立刻回写到主内存。
不过在x86的架构下,JVM回写主内存的速度非常快,但是,换成ARM的架构,就会有显著的延迟。
Java程序入口就是由JVM启动main线程,main线程又可以启动其他线程。当所有线程都运行结束时,JVM退出,进程结束。
如果存在一个定时触发的线程,无线循环,这时怎么才能让其结束,退出JVM呢?答案就是守护进程!!
在JVM中,所有非守护线程都执行完毕后,无论有没有守护线程,虚拟机都会自动退出。
因此,JVM退出时,不必关心守护线程是否已结束。
将线程标记为守护进程:
Thread t = new MyThread(); t.setDaemon(true); t.start()
守护线程不能持有任何需要关闭的资源,例如打开文件等,因为虚拟机退出时,守护线程没有任何机会来关闭文件,这会导致数据丢失。
如果多个线程同时读写共享变量,会出现数据不一致的问题,
而synchronized保证了代码块在任意时刻最多只有一个线程能执行:
class Counter { public static final Object lock = new Object(); public static int count = 0; } class AddThread extends Thread { public void run() { for (int i=0; i<10000; i++) { synchronized(Counter.lock) { Counter.count += 1; } } } }
用Counter.lock实例作为锁,两个线程在执行各自的synchronized(Counter.lock) { ... }代码块时,必须先获得锁,才能进入代码块进行。执行结束后,在synchronized语句块结束会自动释放锁。
使用synchronized:
- 找出修改共享变量的线程代码块;
- 选择一个共享实例作为锁;
- 使用
synchronized(lockObject) { ... }。
在使用synchronized的时候,不必担心抛出异常。因为无论是否有异常,都会在synchronized结束处正确释放锁;
锁的缺点是带来了性能下降。因为synchronized代码块无法并发执行。此外,加锁和解锁需要消耗一定的时间,所以,synchronized会降低程序的执行效率。
锁可以定义多个,但要注意有共享数据操作的线程要用同一个锁;
然而如果每个共享数据就要创建一个锁的话,这样很容易造成代码逻辑混乱;我们可以通过synchronized(this)来锁住本身的这个类,也可直接用synchronized来直接修饰方法,这两种锁的写法是等价的:
public void add(int n) { synchronized(this) { // 锁住this count += n; } // 解锁 } public synchronized void add(int n) { // 锁住this count += n; } // 解锁
如果是锁住一个静态方法,那么其实锁的是由JVM自动创建的这个Class实例,因为对于static方法,是没有this实例的;
可重复锁:
public class Counter { private int count = 0; public synchronized void add(int n) { if (n < 0) { dec(-n); } else { count += n; } } public synchronized void dec(int n) { count += n; } }
如上例子,add执行的时候会调用dec方法,这个时候add是已经拿到this锁了,而再调用的时候dec还会再得到this锁;
JVM允许同一个线程重复获取同一个锁,这种能被同一个线程反复获取的锁,就叫做可重入锁。
由于Java的线程锁是可重入锁,所以,获取锁的时候,不但要判断是否是第一次获取,还要记录这是第几次获取。每获取一次锁,记录+1,每退出synchronized块,记录-1,减到0的时候,才会真正释放锁。
死锁:线程1拿到锁A,在等锁B,线程2拿到锁B,在等锁A;这样这两个线程就会无休止地等下去,这就是死锁;死锁发生后,没有任何机制能解除死锁,只能强制结束JVM进程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号