
第一次个人编程作业
https://github.com/linzhihuang2000/031902510
一、PSP表格
(2.1)在开始实现程序之前,在附录提供PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。
(2.2)在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块的开发上实际花费的时间。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 60 | 90 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 480 | 450 |
| · Design Spec | · 生成设计文档 | 60 | 90 |
| · Design Review | · 设计复审 | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| · Design | · 具体设计 | 60 | 40 |
| · Coding | · 具体编码 | 1000 | 1020 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 60 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 90 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 10 |
| · 合计 | 1830 | 1915 |
二、计算机模块接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
3.1.1类和函数(三个类,15个函数)
- SensitivewordFilter类:
- SensitivewordFilter函数,调用SensitiveWordInit类用DFA算法,把敏感词库写入一个Map
- CheckSensitiveWord2函数:主要实现文本查询敏感词的函数
- Checkstring函数:检测该纯英文+特殊字符的字符串是不是被转换为拼音的敏感词
- initialization函数:因为是一行一行读入文本,所以每次都要初始化
- ishan函数:判断是否为汉字
- pinyin函数:把敏感词库的汉字,转换为拼音,并用一个Map实现拼音对应汉字
- hanzitopinyin函数:把该汉字,转换为拼音
- splitci()函数:调用splitcihui类的函数,实现汉字左右结构拆分,并用一个Map实现左右结构的两个汉字对应组成的汉字(弓虽对应强)
- sum()函数:答案汇总
- readfile()函数:读入敏感词库
- readtext()函数:读入文本
- outflie函数:输出文件
- SensitiveWordInit类:
- initKeyWord函数:调用addSensitiveWordToHashMap函数
- addSensitiveWordToHashMap函数:用DFA算法,把敏感词库写入一个Map
- splitcihui类
- splitci()函数:把左右结构的汉字记录起来,存入一个Map中
3.1.2算法关键之处:
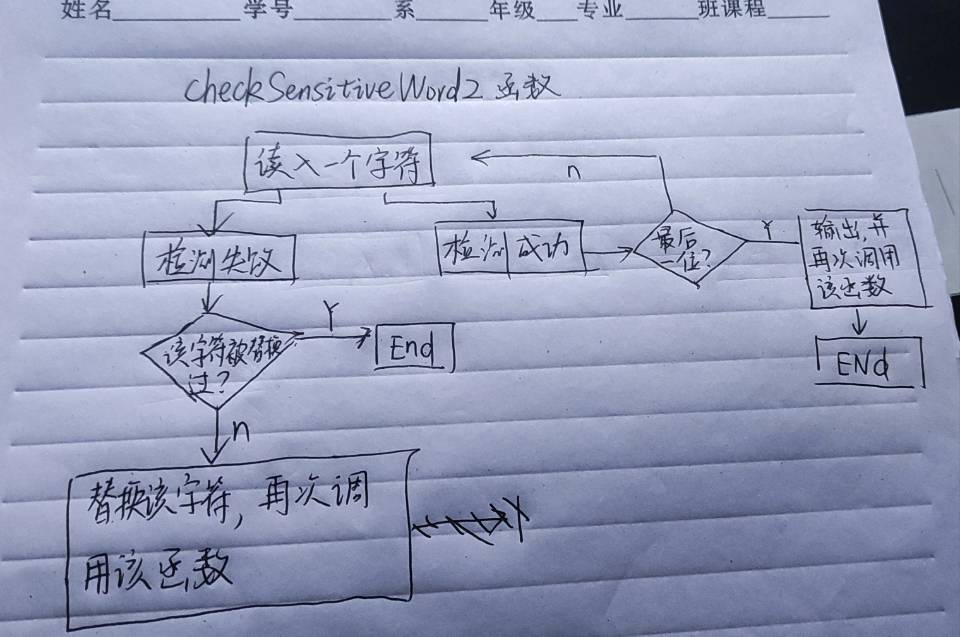
- CheckSensitiveWord2函数和Checkstring函数。 基本思想CheckSensitiveWord2函数(递归)检测到一个字符是敏感词(这里用敏感词fun举例,假设文本是fuN),检测到fu,发现下个N不是n,则把N改为n,再次调用CheckSensitiveWord2函数
-
CheckSensitiveWord2函数:文本一个字符一个字符的读,若读到特殊字符:直接读下一个字符;若是字母:则把它存在一个字符串中,为Checkstring函数作准备; 开始检测,如果成功,继续检测,若失败,找失败原因(字母大小写?还是谐音问题?还是左右结构问题),符合失败原因,就把当前的字替换一下(例如N替换为n),继续调用该函数看看能不能成功检测到敏感词最后一个字。 若检测到敏感词最后一个字,则再次调用该函数,但是检测的文本要去掉刚刚检测过的文本
![]()
-
Checkstring函数:读一段只有纯英文+特殊字符的字符串,把它转换为汉字,去检测敏感词,看看能否检测成功。
-
3.1.3独到之处
- 我自认为没有独到之处。如果硬要说独到之处,就是用递归的思想,把各种情况实现吧,比如说,文本有F,它可以是用f,法,发.....等等词汇去检测
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
3.2.1性能改进
- 刚开始我只是用一个for循环,当检测不成功的时候(替换一个字符),则i--(把文本下标前移),但是做到一半的时候,我发现这只适用,一个字符只能替换的字只有一种的情况。要是要解决谐音敏感词时,就不能用了,毕竟谐音对应好几个(例如:你,尼,拟,泥,妮)。
- 解决方法:于是乎,我想出了用递归的思想,当检测不成功时,判断当前的字,是否是被替换的,如果不是,并且他可以替换,就带着替换的字和当前参数,再次调用这个寻找敏感词的函数。
3.2.2性能分析图
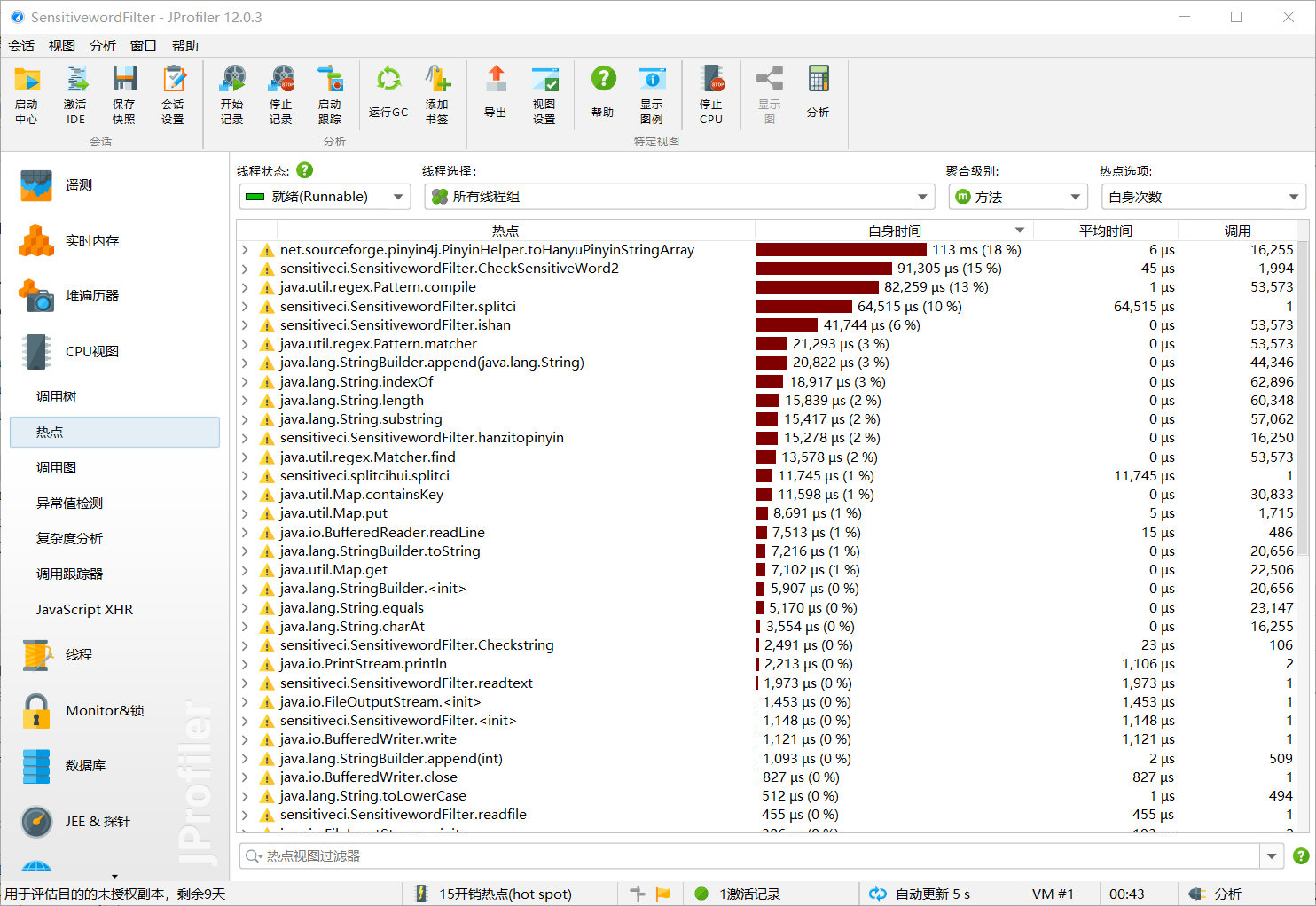
- 可以看出,除了导入拼音包,查找文本中的敏感词的函数花费的时间最多。代码如下
public static int CheckSensitiveWord2(String txt,int j,int n,Map nowMap, String sensitiveci, String nowstring, boolean flag,String ti){
//从左到右的参数是,文本,文本已经读到的下标,文本是第几行,当前敏感词库,
// 当前已经读到的敏感词库中的词,当前读到的敏感词,是否被替换false表示没有替换
//当前替换的词
String word="";
int start=-1;//一串纯英文加特殊符号在txt的下标
int end=0;
for(int i = j; i < txt.length() ; i++) {
if (!flag)
word = txt.substring(i, i + 1);
else
word=ti;//true表示当前检测的,是被替换的
if (regEx.indexOf(word) != -1) {//特殊字符直接跳过
if (!nowstring.equals(""))
nowstring += word;//nowstring不为空,说明当前已找到敏感词的部分内容
continue;
}
if(!flag)
{
if(moderncase.indexOf(word)!=-1)//是不是字母
{
if(string.equals("")) {
start = i;
tempstringMap=nowMap;
tempstringnowstring=nowstring;
tempstringsensitiveci=sensitiveci; //把当前参数存起来,为找 变成拼音 的敏感词
}
string+=word;
}
//当检测到汉字或是最后一个字符,string(一串纯英文)去检测拼音敏感词
if((ishan(word)||i==txt.length()-1)&&!string.equals("")&&start!=-1)
{
if(i==txt.length()-1&&moderncase.indexOf(word)!=-1)
end=i;
else
end=i-1;
if(Checkstring(txt,start,end,n)==1)//检测拼音敏感词
{
//返回值为1,说明这串英语字符,是拼音敏感词
nowMap=tempstringMap;
nowstring=tempstringnowstring+txt.substring(start,end+1);
sensitiveci=tempstringsensitiveci;
}
string="";
}
}
Map tempMap = nowMap;
nowMap = (Map) nowMap.get(word);//获取指定key
if (nowMap != null) {//存在,则判断是否为最后一个
if (!flag)
nowstring += word;
sensitiveci += word;
flag = false;
if ("1".equals(nowMap.get("isEnd"))) {//如果为最后一个匹配规则,结束循环,返回匹配标识数
total++;
an += "Line" + n + ":" + " <" + sensitiveci + "> " + nowstring + "\n";
//初始化
nowMap = sensitiveWordMap;
sensitiveci="";
nowstring="";
string="";
flag=false;
ti="";
//找完找下一个
CheckSensitiveWord2(txt,i+1,n,nowMap,sensitiveci,nowstring,flag,ti);
return 1;
}
}
//该字符是英文,但是检测不成功
else if(moderncase.indexOf(word)!=-1&&!flag)
{
int pan=2;
String tempstring=nowstring;
if(uppercase.indexOf(word)!=-1)//是小写
{
flag = true;
nowstring += word;
word = word.toLowerCase();//改为大写再次检测
ti=word;
nowMap = tempMap;
pan=CheckSensitiveWord2(txt,i,n,nowMap,sensitiveci,nowstring,flag,ti);
}
else//大写的话,改为小写去检测
{
flag = true;
nowstring += word;
word = word.toUpperCase();
ti=word;
nowMap = tempMap;
pan=CheckSensitiveWord2(txt,i,n,nowMap,sensitiveci,nowstring,flag,ti);
}
if(pan==1) {//pan为1,说明被替换的字母正是我们要找的
string = "";
return 1;
}
//否则,就初始化
sensitiveci = "";
nowstring = "";
nowMap = sensitiveWordMap;
flag = false;
}
//字符是汉字,但是检测不成功,可能是谐音,或者左右结构拆开的原因(强=弓虽)
else if(ishan(word) && !flag)
{
int pan=2;//用来判断的
String word2;
if (i != txt.length() - 1)//左右结构拆开
{
word2 = txt.substring(i + 1, i + 2);
if (ishan(word2)) {
String word3 = word;
word3 += word2;
if (split.containsKey(word3)) {//如果改字是被拆开的,那把他组合起来再去检测
flag = true;
nowstring += word3;
word = split.get(word3);
nowMap = tempMap;
pan=CheckSensitiveWord2(txt,i+1,n,nowMap,sensitiveci,nowstring,flag,word);
}
if(pan==1)//pan为1,说明组合起来的字去检测是成功的
return 1;
}
}
//谐音问题
String wordpinyin=hanzitopinyin(word);//把该字转换为拼音
if(pinyintohanzi.containsKey(wordpinyin))//如果该拼音的确是敏感词
{
String temp=pinyintohanzi.get(wordpinyin);//一串是谐音的敏感词字符串,例如(fa),该字符串就是发法罚....
flag = true;
nowstring += word;
nowMap = tempMap;
for (int z=0;z<temp.length();z++)//一个一个谐音去试
{
word=temp.substring(z,z+1);
pan=CheckSensitiveWord2(txt,i,n,nowMap,sensitiveci,nowstring,flag,word);
if(pan==1)
return 1;
}
}
sensitiveci = "";
nowstring = "";
nowMap = sensitiveWordMap;
flag = false;
}
//该字符不能被替换,或已经被替换过了
else {
if(flag)
return -1;//-1表示替换了,也不成功
sensitiveci = "";
nowstring = "";
nowMap = sensitiveWordMap;
flag = false;
}
}
return 2;//2表示程序正常结束
}
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
- 1.测试能否用DFA方法建立树
public static void main(String[] args) {
long beginTime = System.currentTimeMillis();
Set<String> set1 = new HashSet<String>();
splitci();
set1 = readfile("D:\\testwords.txt");//读入敏感词文件
SensitivewordFilter filter = new SensitivewordFilter(set1);//把敏感词用DFA写入Map
long endTime = System.currentTimeMillis();
System.out.println("总共消耗时间为:" + (endTime - beginTime)+"毫秒");
}
- testword.txt文件包含(笨蛋和笨逼)两个敏感词结果如下
![]()
- 测试覆盖率如下
![]()


- 2.测试检测文本中的敏感词汇,测试思路:判定为敏感词的要求(中文:插字符,谐音,拼音,拼音首字母,左右结构。英语:插字符,大小写)
public static void main(String[] args) {
long beginTime = System.currentTimeMillis();
Set<String> set1 = new HashSet<String>();
splitci();
set1 = readfile("D:\\testwords.txt");//读入敏感词文件
SensitivewordFilter filter = new SensitivewordFilter(set1);//把敏感词用DFA写入Map
readtext("D:\\testorg.txt");
sum();//把答案汇总;
outflie("D:\\testans.txt");//输出文件
long endTime = System.currentTimeMillis();
System.out.println("总共消耗时间为:" + (endTime - beginTime)+"毫秒");
}
-
敏感词(hello,山寨,爱过,强奸)和检测文本
![]()
-
结果如下
![]()
-
测试覆盖率如下
![]()



(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
IOError: 当输入文件不存在,输出找不到该文件
- 单元测试代码:
public static void readfile(String readf) {
try {
File f = new File(readf);//指定文件
FileInputStream fis = new FileInputStream(f);//创建输入流fis并以f为参数
InputStreamReader isr = new InputStreamReader(fis,"UTF-8");//创建字符输入流对象isr并以fis为参数
BufferedReader br = new BufferedReader(isr);//创建一个带缓冲的输入流对象br,并以isr为参数
} catch (Exception e) {
System.out.println("找不到该文件");
e.printStackTrace();
}
}
- 没有文件的情况:
![]()

三、心得
(4.1)在完成本次作业过程的心得体会。
- 通过本次学习,我发现了自己有很多的不足之处,从头到尾都在学习与借鉴,从最基本的java如何输入输出文件,到那些JProfile性能分析工具怎么安装使用。基本上无时无刻在学习,深深地感觉到了自己的不足。
- 也当然学会了很多知识,边写代码边找到bug,让我学会了很多解决方法。也了解了如何使用一些工具等等。
- 最最重要的是,当前还是无法完全解决拼音带来的问题,在很多情况下还是检测不出来。平心而论,已经尽力了,但能力有限,只能今后加倍提升自己。如果有解决的方法或者本人代码不足之处,欢迎留言告知。
- 再补充一点,看到大佬们提交的作业,也发现了应该用,各种情况的笛卡尔积去建树(DFA),但截止时间将至,只好有空的时候对大佬们提交的作业进行学习借鉴。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号