LeetCode 13 - DFS & BFS
127. 单词接龙#
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
- 每一步只变化一个字母。
- 对于
1 <= i <= k时,每个si都在wordList中,beginWord 除外。 sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList ,返回 从 beginWord 到 endWord 的 最短转换序列 中的 单词数目 。如果不存在这样的转换序列,返回 0 。
方法一:BFS
要求的是 最短转换序列 的长度,看到 最短 首先想到 BFS,想到 BFS 自然就想到 图,但是本题没有直接给出图的模型,因此需要我们将它 抽象成图的模型 —— 我们可以把每个单词抽象成一个结点,如果两个单词只有一个字母不同,那么它们之间有一条边相连。这样就形成了一张图。
基于该图,以 beginWord 为图的起点,以 endWord 为终点进行 BFS,寻找它们之间的 最短路径 即可。
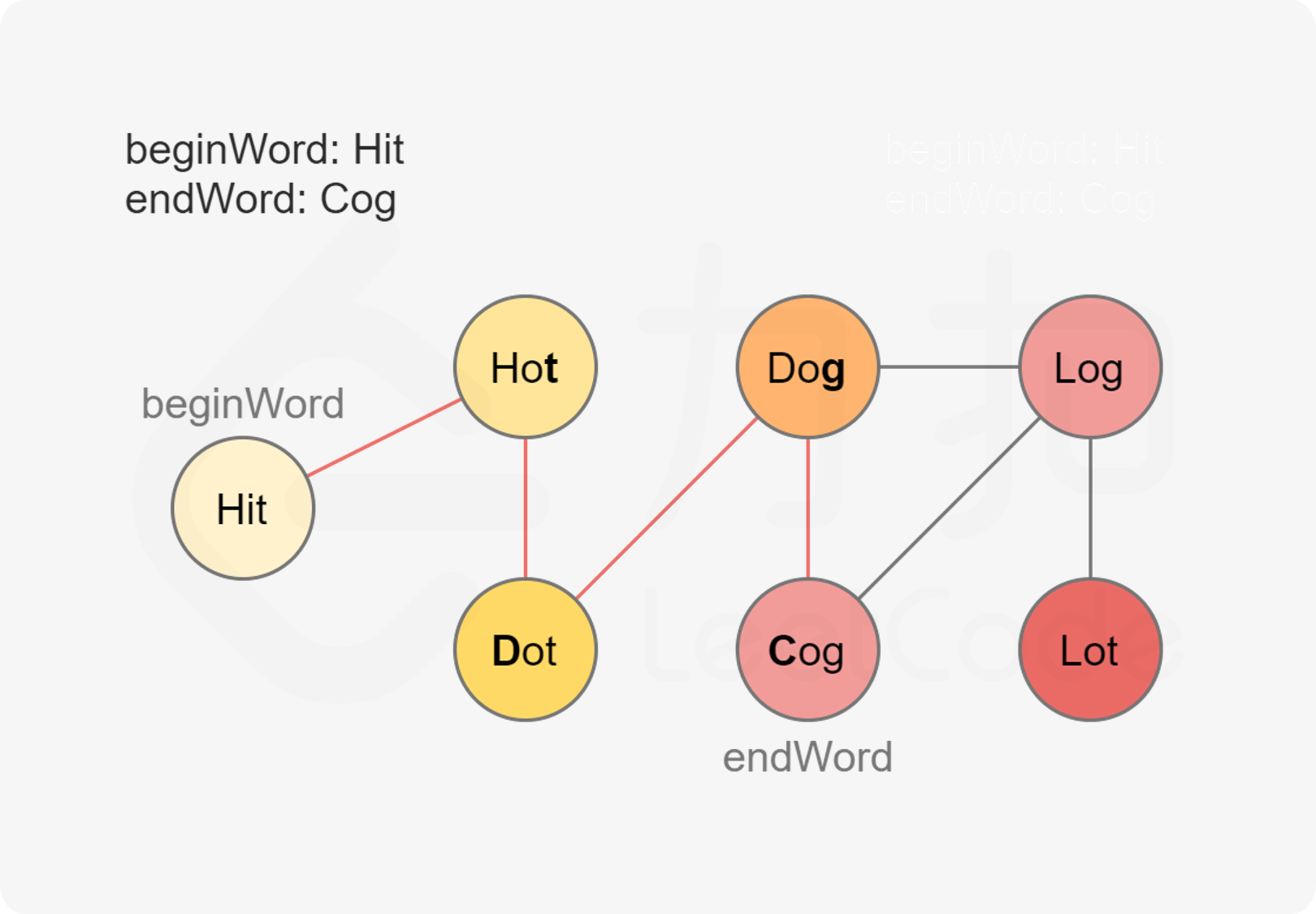
具体建图过程:
- 如果直接对单词两两比较以确定两者之间是否只有一个字符不同,从而确定两者之间是否有边,那么每个单词需要的时间复杂度是 ,其中 是单词个数。
- 为了优化这个问题,可以从当前单词出发,在单词每个位置替换字母(有26个选择)形成新单词,再检查这个新单词是否存在于单词列表中,如果存在则说明两者之间有一条边。这样每个单词需要的时间复杂度是 。
Set<String> visited = new HashSet<>(); // 确保每个单词只入队一次
Queue<String> queue = new LinkedList<>();
Set<String> wordSet;
int ladderLength(String beginWord, String endWord, List<String> wordList) {
// 1. 将 WordList 放到哈希表里,便于判断某个单词是否存在于 wordList 中
wordSet = new HashSet<>(wordList);
// if(wordSet.size() == 0 || !wordSet.contains(endWord))
// return 0;
// wordSet.remove(beginWord);
// 2. BFS
queue.offer(beginWord);
visited.add(beginWord);
// 这里的最短路径是所经过结点的数量,所以直接初始化为 1
int step = 1;
while(!queue.isEmpty()) {
int size = queue.size(); // 需要缓存队列 size
for(int i = 0; i < size; i++) {
String word = queue.poll();
// 在这个判断过程中会入队新元素
if(isSimilar(word, endWord))
return step + 1;
}
step++;
}
return 0;
}
// 判断两个单词是否只有一个位置的字母不同
boolean isSimilar(String s1, String s2) {
char[] s1CharArray = s1.toCharArray();
// 依次改变 s1 每个位置的字母,看形成的新单词是否与 s2 相同
for(int i = 0; i < s2.length(); i++) {
// 先缓存当前位置字母,在当前轮循环结束后恢复
char origin = s1CharArray[i];
for(char c = 'a'; c <= 'z'; c++) {
if(c == origin) continue;
s1CharArray[i] = c;
String newWord = String.valueOf(s1CharArray);
// 新单词存在于单词列表中,才可进行进一步比较
if(wordSet.contains(newWord)) {
if(newWord.equals(s2)) return true;
if(!visited.contains(newWord)) {
queue.offer(newWord);
// 添加到队列后,即可标记为已访问
visited.add(newWord);
}
}
}
s1CharArray[i] = origin;
}
return false;
}
130. 被围绕的区域#
给你一个 m x n 的矩阵 board ,由若干字符 'X' 和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
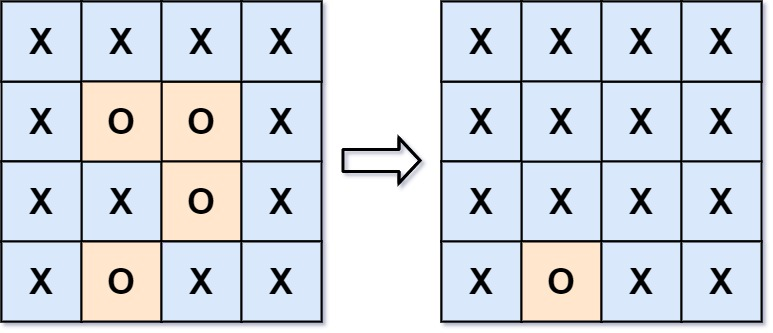
没有被包围的 O 是那些在边界的 O,以及与这些 O 连通的 O,所以我们采用逆向思维,先将这些没有被包围的 O 找出来,剩下那些 O 就是需要被替换成 X 的。
- 从边界上的 O 出发,通过 BFS/DFS 找到所有相连的 O,将其标记为 A;
- 然后遍历每一个位置,将 O 替换成 X;
- 最后将 A 恢复为 O。
方法一:DFS
void solve(char[][] board) {
int M = board.length, N = board[0].length;
// 将上下边界的 O 及与其相连的 O 替换成 A
for(int col = 0; col < N; col++) {
if(board[0][col] == 'O')
dfs(board, 0, col);
if(board[M-1][col] == 'O')
dfs(board, M-1, col);
}
// 将左右边界的 O 集与其相连的 O 替换成 A
for(int row = 0; row < M; row++) {
if(board[row][0] == 'O')
dfs(board, row, 0);
if(board[row][N-1] == 'O')
dfs(board, row, N-1)
}
// 将剩余的 O 替换为 X,同时恢复 A 为 O
for(int row = 0; row < M; row++) {
for(int col = 0; col < N; col++) {
if(board[row][col] == 'O')
board[row][col] = 'X';
if(board[row][col] == 'A')
board[row][col] == 'O';
}
}
}
void dfs(char[][] board, int row, int col) {
// base case
if(row < 0 || row >= board.length
|| col < 0 || col >= board[0].length)
return;
if(board[row][col] != 'O')
return;
// 执行任务
board[row][col] = 'A';
// 访问相邻结点
dfs(board, row - 1, col);
dfs(board, row + 1, col);
dfs(board, row, col - 1);
dfs(board, row, col + 1);
}
方法二:BFS
和 DFS 唯一的不同在于标记 O 为 A 的方式。
- 首先将四个边界上的 O 所在位置当做「第一层」放入队列,同时将其变为 A;
- 然后不断出队,检查上下左右四个方向的相邻位置,如果是 O,则同样入队,并变为 A。
- 最后遍历每个位置,将 O 变为 X,并将 A 变为 O。
void solve(char[][] board) {
int M = board.length, N = board[0].length;
Queue<int[]> queue = new LinkedList<>();
// 上下两边界的 O 所在的位置入队
for(int col = 0; col < N; col++) {
if(board[0][col] == 'O') {
queue.offer(new int[]{0, col});
board[0][col] = 'A';
}
if(board[M-1][col] == 'O') {
queue.offer(new int[]{M-1, col});
board[M-1][col] = 'A';
}
}
// 左右两边界的 O 所在的位置入队
for(int row = 0; row < M; row++) {
if(board[row][0] == 'O') {
queue.offer(new int[]{row, 0});
board[row][0] = 'A';
}
if(board[row][N-1] == 'O') {
queue.offer(new int[] {row, N-1});
board[row][N-1] = 'A';
}
}
// 开始 BFS
int[] rowInc = {-1, 1, 0, 0};
int[] colInc = {0, 0, -1, 1};
while(!queue.isEmpty()) {
int[] curCell = queue.poll();
int row = curCell[0], col = curCell[1];
for(int k = 0; k < 4; k++) {
int newRow = row + rowInc[k];
int newCol = col + colInc[k];
if(newRow < 0 || newRow >= M || newCol < 0 || newCol >= N
|| board[newRow][newCol] != 'O')
continue;
queue.offer(new int[]{newRow, newCol});
board[newRow][newCol] = 'A';
}
}
// 遍历每个位置,将 O 变成 X
for(int row = 0; row < M; row++) {
for(int col = 0; col < N; col++) {
if(board[row][col] == 'O')
board[row][col] = 'X';
if(board[row][col] == 'A')
board[row][col] = 'O';
}
}
}
139. 单词拆分#
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
方法一:DFS
思路:
"leetcode"能否被拆分,可以拆分为一系列子问题:"l"是否是单词表的单词、剩余子串能否被拆分。"le"是否是单词表的单词、剩余子串能否被拆分。"lee"... 以此类推
- 用 DFS 回溯,考察所有的拆分可能,指针从左往右扫描:
- 如果指针的左侧部分是单词,则对剩余子串递归考察。
- 如果指针的左侧部分不是单词,不用看了,回溯,考察别的分支。
此外,为了避免重复计算,使用一个 备忘录 记录 从每个位置开始的子串能否被拆分。在搜索过程中遇到相同的子问题,直接返回备忘录中的值,就不用递归计算了。
boolean wordBreak(String s, List<String> wordList) {
int len = s.length();
int[] memo = new int[len];
Arrays.fill(memo, -1); // 0 表示 false,1 表示 true
return dfs(s, 0, wordList, memo);
}
boolean dfs(String s, int start, List<String> wordList) {
int len = s.length();
if(start == len) return true;
if(memo[start] != -1)
return memo[start] == 1 ? true : false;
// 从 start 位置开始,尝试从后面的每个位置开始切分
// 如果切分出的第一个单词在 wordList 中,
// 且后面的序列也可以切分,则返回 true
// 注意这里是 i <= len
for(int i = start + 1; i <= len; i++) {
String prefix = s.substring(start, i);
if(wordList.contains(prefix) && dfs(i)) {
memo[start] = 1;
return true;
}
}
memo[start] = 0;
return false;
}
方法二:BFS
维护一个队列,用指针表示一个结点。
- 初始状态下,指针 0 入队;
- 元素不断出队,每出队一个指针
i,查看i+1,i+2……与指针i围起来的子串,如果存在于 wordDict中,则将它入队,在后面继续考察以它为起点的剩余子串。 - 直到指针越界,此时如果前缀子串存在于 wordDict 中,则返回
true; - 整个 BFS 过程始终没有返回
true,则返回false。
boolean wordBreak(String s, List<String> wordDict) {
int len = s.length();
Set<String> wordSet = new HashSet<>();
// queue 记录每个索引位置,从 0 开始搜索
Queue<Integer> queue = new LinkedList<>();
boolean[] visited = new boolean[len];
queue.offer(0);
while(!queue.isEmpty()) {
int start = queue.poll();
if(visited[start]) continue; // 访问过则跳过
visited[start] = true; // 出队被处理后标记为已访问
for(int i = start + 1; i <= len; i++) {
String prefix = s.substring(start, i);
// 只有在前缀是单词时才继续迭代,否则跳过
if(wordSet.contains(prefix)) {
if(i < len) { // 还没越界,还能继续切分
queue.push(i);
} else { // 指针越界,说明整个字符串被切分完毕
return true;
}
}
}
}
return false;
}
方法三:动态规划
dp[i] 表示子串 s[0..i-1] 是否能由可以切分。具体来说,需要遍历子串中每一个分割点 j ,判断 s[0..j-1] 和 s[j, i-1] 是否能被切分,都是的话 dp[i] 才为 true 。所以状态转移方程为:
boolean wordBreak(String s, List<String> wordDict) {
Set<String> wordSet = new HashSet<>(wordDict);
boolean[] dp = new boolean[s.length()+1];
dp[0] = true; // 表示:空串可以切分
for(int i = 1; i <= s.length(); i++) {
// 遍历每一个分割点,试图寻找一个使得子串可切分的分割点
for(int j = 0; j < i; j++) {
if(dp[j] && wordSet.contains(s.substring(j, i))) {
dp[i] = true;
break;
}
}
}
return dp[s.length()];
}
113. 路径总和 II#
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
方法一:DFS
用一个列表来存储符合条件的路径,用一个双端队列存储到达当前结点的路径(用双端队列模拟栈的从栈顶插入删除的操作,同时又有队列先入先出的功能)。具体遍历过程为:
- 从根结点开始 DFS,每经过一个结点,将结点入队。
- 当遍历到叶结点时,如果当前路径之和等于目标值,则说明当前路径符合条件,将其加入结果列表。
- 当遍历到叶结点,但当前路径之和不等于目标值时,将当前节点从队尾删除(向上回溯)。
List<List<Integer>> result = new ArrayList<>();
Deque<Integer> path = new LinkedList<>();
List<List<Integer>> pathSum(TreeNode root, int targetSum) {
getPath(root, targetSum);
return result;
}
void getPath(TreeNode node, int sum) {
// 每经过一个结点,将结点入栈
path.offerLast(node.val);
int newSum = sum - node.val;
// 到达叶结点,满足条件就加入结果列表,否则出栈
if(node.left == null && node.right == null && newSum == 0) {
result.add(new ArrayList<Integer>(path));
}
// 未到达叶结点,则继续向下搜索
if(node.left != null)
getPath(node.left, newSum);
if(node.right != null)
getPath(node.right, newSum);
// 到达叶结点,但不满足条件,则出栈
path.pollLast();
}
337. 打家劫舍 III#
小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。这个地方的所有房屋的排列类似于一棵二叉树。 如果 两个直接相连的房子在同一天晚上被打劫 ,房屋将自动报警。
给定二叉树的 root 。返回在不触动警报的情况下 ,小偷能够盗取的最高金额 。
方法:基于 DFS 的动态规划
这个问题实际上是说:给定一棵二叉树,每个结点有两种状态——选择和不选择,问:在不能同时选中有父子关系的结点的情况下,能选择的结点的最大权值之和为多少?
用 表示选择结点 的情况下,以 为根的子树能选择的结点权值之和的最大值; 表示在不选择 的情况下,以 为根的子树能选择的结点权值之和的最大值。同时用 分别表示 的左右孩子。则状态转移关系为:
- 当 $$ 被选择时, 都不能被选择,所以此时 。
- 当 不被选择时, 可以都不选择,也可以只选择一个,也可以两个都选择。各种情况下的最大值即为所求:。
可以用哈希表存储 的函数值,用 DFS 后序遍历这棵树,就可以得到每个结点的 。 就是答案。
Map<TreeNode, Integer> f = new HashMap<>();
Map<TreeNode, Integer> g = new HashMap<>();
int rob(TreeNode root) {
dfs(root);
return Math.max(f.getOrDefault(root, 0), g.getOrDefault(root, 0));
}
void dfs(TreeNode node) {
if(node == null) return;
// 后序遍历
dfs(node.left);
dfs(node.right);
f.put(node, node.val + g.getOrDefault(node.left, 0)
+ g.getOrDefault(node.right, 0));
g.put(node, Math.max(f.getOrDefault(node.left, 0), g.getOrDefault(node.left, 0))
+ Math.max(f.getOrDefault(node.right, 0), g.getOrDefault(node.right, 0)));
}
934. 最短的桥#
在给定的二维二进制数组 A 中,存在 两座岛。(岛是由四面相连的 1 形成的一个最大组。)
现在,我们可以将 0 变为 1,以使两座岛连接起来,变成一座岛。返回必须翻转的 0 的最小数目。(可以保证答案至少是 1 。)
方法:DFS+BFS
- 用 DFS 找到第一座岛屿,并将第一座岛屿上的陆地全部修改为 2,表示已访问过。
- 然后用 BFS 从第一座岛屿周围紧邻的海水开始,“一圈圈地” 向外扩张,直到抵达第二座岛屿上的任意一块陆地。此时,搜索的层数即为最短桥的长度。(最短 就可以联想到 BFS)
int[] dx = {-1, 1, 0, 0};
int[] dy = {0, 0, -1, 1};
int shortestBridge(int[][] A) {
int rows = A.length, cols = A[0].length;
// 先 DFS 将找到的第一个岛都赋值为 2,
// 并将第一座岛旁边的 0 全部放入队列
Queue<int[]> queue = new LinkedList<>();
boolean flag = false;
for(int i = 0; i < rows; i++) {
// 找到岛上一个点,通过 DFS 就能识别出整座岛了,
// 然后就可以直接退出,无需后续计算了。
if(flag) break;
for(int j = 0; j < cols; j++) {
// 发现一块陆地后,开始搜索整座岛
if(A[i][j] == 1) {
dfs(A, queue, i, j);
// 只需从任意一块陆地扩展搜索即可搜索出整个岛
// 然后就退出两重循环
flag = true;
break;
}
}
}
// BFS 寻找下一座岛,遍历时将所有 0 赋值为 2
int step = 0;
while(!queue.isEmpty()) {
step++;
int size = queue.size();
// 从当前层的海水向四周搜索,直到遇到下一个岛屿
for(int i = 0; i < size; i++) {
int[] cell = queue.poll();
for(int k = 0; k < 4; k++) {
int newRow = cell[0] + dx[k];
int newCol = cell[1] + dy[k];
// 向四周扩展时下标越界
if(newRow < 0 || newRow = rows
|| newCol < 0 || newCol = cols)
continue;
// 找到第二座岛中的陆地
if(A[newRow][newCol] == 1)
return step;
// 已访问过,则跳过
else if(A[newRow][newCol] == 2)
continue;
// 遇到的还是海水,就入队继续搜索
A[newRow][newCol] = 2;
queue.add(new int[]{newRow, newCol});
} // end of for k
} // end of for i
} // end of while
return step;
}
void dfs(int[][] A, Queue<int[]> queue, int x, int y) {
// 将陆地 1 的值修改为 2,然后向四个方向延伸
// 延伸过程中,如果遇到 0 则说明它是与第一座岛紧邻的,加入队列
// 如果遇到 2 说明之前已经处理过了,直接返回
// 1.base case
if(x < 0 || x == A.length || y < 0
|| y == A[0].length || A[x][y] == 2)
return;
if(A[x][y] == 0) { // 第一座岛屿紧邻的海水,入队
queue.add(new int[]{x, y});
return;
}
// 2.执行任务:将陆地修改为 2,表示已访问过
A[x][y] = 2;
// 3.访问相邻位置
for(int i = 0; i < 4; i++) {
int newX = x + dx[i], newY = y + dy[i];
dfs(A, queue, newX, newY);
}
}
994. 腐烂的橘子#
给定二维数组表示的网格,每个单元格表示一个橘子的状态:0 表示没有橘子,1 表示新鲜橘子,2 表示烂橘子。每个单位时间内,烂橘子会污染上下左右四个相邻位置的新鲜橘子,使其变成烂橘子。求解所有新鲜橘子都被污染的最小时间,如果最后存在不能被污染的新鲜橘子,则返回 -1.
分析:每分钟每个腐烂的橘子都会使上下左右相邻的新鲜橘子腐烂,这其实是一个模拟广度优先搜索的过程。上下左右相邻的新鲜橘子就是该腐烂橘子尝试访问的同一层的节点,路径长度就是新鲜橘子被腐烂的时间。
与基础BFS的不同之处在于,可能存在孤立的新鲜橘子,所以需要统计新鲜橘子的总数,并在污染过程中更新这个数量。搜索过程的结束条件不单单是队列为空,还要考虑是否还有新鲜橘子。
int orangesRotting(int[][] grid) {
int M = grid.length, N = grid[0].length;
Queue<int[]> queue = new LinkedList<>();
int freshCount = 0; // 需要知道新鲜橘子的个数
for(int i = 0; i < M; i++) {
for(int j = 0; j < N; j++) {
if(grid[i][j] == 1) freshCount++
if(grid[i][j] == 2) queue.add(new int[] {i, j});
}
}
// 开始搜索
int minutes = 0;
while(freshCount > 0 && !queue.isEmpty()) {
int size = queue.size();
for(int i = 0; i < size; i++) {
int[] cur = queue.poll();
int row = cur[0], col = cur[1];
// 上
if(row > 0 && grid[row-1][col] == 1) {
grid[row-1][col] = 2; // 污染
queue.add(new int[] {row-1, col});
freshCount--; // 更新新鲜橘子的个数
}
// 下、左、右类似,省略
// ...
}
minutes++;
}
if(freshCount > 0) return -1;
return minutes;
}
200. 岛屿数量#
方法一:DFS
int numsOfIsland(int[][] grid) {
int M = grid.length, N = grid[0].length;
int result = 0;
for(int r = 0; r < M; r++) {
for(int c = 0; c < N; c++) {
if(grid[r][c] == 1) {
result++;
dfs(grid, r, c);
}
}
}
return result;
}
void dfs(int[][] grid, int r, int c) {
// base case
if(r<0 || r>=grid.length || c<0 || c>=grid[0].length)
return;
if(grid[r][c] != 1)
return;
// 访问这个元素
grid[r][c] = 2;
// 访问相邻元素
dfs(grid, r-1, c);
dfs(grid, r+1, c);
dfs(grid, r, c-1);
dfs(grid, r, c+1);
}
方法二:BFS
int numsOfIsland(int[][] grid) {
int M = grid.length, N = grid[0].length;
int result = 0;
for(int r = 0; r < M; r++) {
for(int c = 0; c < N; c++) {
// 队列中只存储陆地区块
Queue<int[]> queue = new LinkedList<>();
if(grid[r][c] == 1) {
result++;
queue.offer(new int[] {r, c});
grid[r][c] = 2;
while(!queue.isEmpty()) {
int[] rowcol = queue.poll();
int row = rowcol[0], col = rowcol[1];
// 访问相邻结点
int[] rInc = {-1, 1, 0, 0};
int[] cInc = {0, 0, -1, 1};
for(int k = 0; k < 4; k++) {
int newR = row + rInc[k], newC = col + cInc[k];
if(newR<0 || newR>=M || newC<0 || newC>=N)
continue;
if(grid[newR][newC] != 1)
continue;
queue.offer(new int[] {newR, newC});
grid[newR][newC] = 2;
}
} // end of while
} // end of if
} // end of for j
} // end of for i
return result;
}
连通分量#
用二维数组表示图,位置 (i,j) 如果为 1 则表示两结点相连,求出连通分量数量。
方法一:DFS
遍历所有结点,对于每个结点,如果它尚未被访问过,则从该结点开始DFS——找出跟它相连的每个结点,并从这些结点继续DFS,直到所有相连结点均被访问过,即可得到一个连通分量。遍历完所有结点后,即可得到连通分量总数。
int findCircleNum(int[][] isConnected) {
int len = isConnected.length;
boolean[] visited = new boolean[len];
int circleCount = 0;
for(int i = 0; i < len; i++) {
if(!visited[i]) {
dfs(isConnected, visited, i);
circleCount++;
}
}
return circleCount;
}
void dfs(int[][] graph, boolean[] visited, int i) {
for(int j = 0; j < graph.length; j++) {
if(graph[i][j] == 1 && !visited[j]) {
visited[j] = true;
dfs(graph, visited, j);
}
}
}
遍历过程中需要做的只是记录
visited状态。
方法二:BFS
对每一个结点,开始BFS,直到找到所有相连结点。同样地,遍历过程也只是记录 visited 状态。
int findCircleNum(int[][] isConnected) {
int len = isConnected.length;
int circleCount = 0;
Queue<Integer> queue = new LinkedList<>();
boolean[] visited = new boolean[len];
for(int i = 0; i < len; i++) {
if (!visited[i]) {
queue.offer(i);
while(!queue.isEmpty()) {
int cur = queue.poll();
visited[cur] = true;
for(int j = 0; j < len; j++) {
if(isConnected[cur][j] == 1 && !visited[j]) {
queue.offer(j);
}
}
}
circleCount++;
}
}
return circleCount;
}
695. 岛屿的最大面积#
用二维数组表示一块区域,元素 0 表示海水,1 表示陆地,相连的陆地形成岛屿,求最大岛屿的面积。
方法一:DFS
- 我们需要直到每个网格相连的连通岛屿的面积,然后取最大值。
- 在计算每个岛屿面积时,需要往上下左右四个方向探索。
- 为了避免重复访问一块陆地,在第一次访问后,将这块陆地的值置为 0。
int maxAreaOfIsland(int[][] grid) {
int M = grid.length, N = grid[0].length;
int maxArea = 0;
for(int i = 0; i < M; i++) {
for(int j = 0; j < N; j++) {
maxArea = Math.max(dfs(grid, i, j), maxArea);
}
}
return maxArea;
}
int dfs(int[][] grid, int row, int col) {
// 递归出口
if(row < 0 || row > grid.length-1
|| col < 0 || col > grid[0].length-1 || grid[row][col] == 0) {
return 0;
}
grid[row][col] = 0; // 将访问过的陆地置为 0
int area = 1;
// 上下左右探索
int[] rowIncrease = {-1, 1, 0, 0};
int[] colIncrease = {0, 0, -1, 1};
for(int i = 0; i < 4; i++) {
int rowIndex = row + rowIncrease[i],
colIndex = col + colIncrease[i];
area += dfs(grid, rowIndex, colIndex);
}
return area;
}
上面的 DFS 使用了递归,还可以显式地使用栈来存储将要访问的区块,每次在出栈时检查这个区块是陆地还是海水。
int maxAreaOfIsland(int[][] grid) {
int M = grid.length, N = grid[0].length;
int maxArea = 0;
for(int i = 0; i < M; i++) {
for(int j = 0; j < N; j++) {
// 计算当前位置所属岛屿的面积
int curArea = 0;
Deque<Int[]> stack = new LinkedList<>();
stack.push(new int[] {i, j});
while(!stack.isEmpty()) {
int[] rowcol = stack.pop();
int row = rowcol[0], col = rowcol[1];
// 检查索引是否合法,以及该区块是否为陆地
if(row < 0 || row > M-1 || col < 0 || col > N-1
|| grid[row][col] == 0)
continue;
// 如果为陆地,则向四个方向探索
curArea++;
grid[row][col] = 0;
int[] rowIncrease = {-1, 1, 0, 0};
int[] colIncrease = {0, 0, -1, 1};
for(int k = 0; k < 4; k++) {
int rowIndex = row + rowIncrease[i],
colIndex = col + colIncrease[i];
// 相邻位置入栈
stack.push(new int[] {rowIndex, colIndex});
}
} // end of while
maxArea = Math.max(maxArea, curArea);
} // end of for j
} // end of for i
}
方法二:BFS
BFS 和上面使用栈的 DFS 很像,只是用队列代替了栈。
int maxAreaOfIsland(int[][] grid) {
int M = grid.length, N = grid[0].length;
int maxArea = 0;
for(int i = 0; i < M; i++) {
for(int j = 0; j < N; j++) {
int curArea = 0;
Queue<int[]> queue = new LinkedList<>();
queue.offer(new int[] {i, j});
while(!queue.isEmpty()) {
int rowcol = queue.poll();
int row = rowcol[0], col = rowcol[1];
if(row < 0 || row > M-1 || col < 0 || col > N-1
|| grid[row][col] == 0)
continue;
// 遇到陆地
curArea++;
grid[row][col] = 0;
int[] rowIncrease = {-1, 1, 0, 0};
int[] colIncrease = {0, 0, -1, 1};
for(int k = 0; k < 4; k++) {
int rowIndex = row + rowIncrease[k];
int colIndex = col + colIncrease[k];
queue.offer(new int[] {rowIndex, colIndex});
}
} // end of while
maxArea = Math.max(maxArea, curArea);
} // end of for j
} // end of for i
}
542. 01 矩阵#
给定 1 和 0 组成的矩阵,求出每个位置与 0 的最小距离。
方法:多源 BFS
class Solution {
public int[][] updateMatrix(int[][] mat) {
int M = mat.length, N = mat[0].length;
int[][] result = new int[M][N];
int[][] visited = new int[M][N];
Queue<int[]> queue = new LinkedList<>();
for(int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
if(mat[i][j] == 0) {
queue.offer(new int[] {i, j});
visited[i][j] = 1;
}
}
}
while(!queue.isEmpty()) {
int[] rowcol = queue.poll();
int i = rowcol[0], j = rowcol[1];
int[] di = {-1,1,0,0};
int[] dj = {0,0,-1,1};
for(int k = 0; k < 4; k++) {
int newi = i + di[k], newj = j + dj[k];
if(newi < 0 || newi >= M || newj < 0 || newj >= N
|| visited[newi][newj] == 1)
continue;
result[newi][newj] = result[i][j] + 1;
queue.offer(new int[] {newi, newj});
visited[newi][newj] = 1;
}
}
return result;
}
}
207. 课程表#
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。请你判断是否可能完成所有课程的学习?如果可以,返回一个学习顺序列表 。
分析:这个问题可以建模为拓扑排序问题:
- 将每一门课看成一个结点;
- 如果 A 是 B 的先导课程,那么存在一条 A -> B 的有向边。
求出该图是否存在拓扑排序,就可以判断是否有一种符合要求的课程顺序。而如果存在环,就说明不存在拓扑排序。
方法一:DFS
用一个栈来存储所有已经搜索完成的结点。如果一个结点的所有出邻居都已经搜索完成,那么回溯到这个结点时,该结点本身也会变成一个搜索完成的结点,将其入栈。这样一来,对所有结点的搜索完成时,从栈顶到栈底的序列就是一种拓扑排序。
每个结点在搜索过程中有三种状态:
- 未搜索:还没有碰到这个结点;
- 搜索中:搜索过这个结点,但是还没有回溯到它,即这个结点还未入栈(还有出邻居未完成搜索);
- 已完成:已经回溯到了这个结点,即它已经入栈。
根据这三种状态,在每一轮搜索开始时,任取一个 未搜索 的结点开始进行 DFS。然后:
- 将当前搜索的结点 u 标记为 搜索中,遍历该结点的每一个出邻居 v:
- 如果 v 为 未搜索,则开始搜索 v,搜索完成时回溯到 u;
- 如果 v 为 搜索中,说明找到了一个环,因此不存在拓扑排序;
- 如果 v 为 已完成,说明 v 已在栈中,不用进行任何操作。
- 当 u 的所有出邻居都为 已完成 时,将 u 放入栈中,标记它为 已完成。
在整个 DFS 结束后,如果没有发现环,那么栈中存储的这个顺序就是一种拓扑排序。
List<List<Integer>> edges; // 存储有向图
int[] visited; // 标记每个结点的状态
int[] result; // 用数组模拟栈,n-1 位置为栈底
boolean valid = true; // 判断有向图中是否有环
int index; // 栈下标
int[] findOrder(int numCourses, int[][] prerequisites) {
edges = new ArrayList<>();
for(int i =0; i < numCourses; i++)
edges.add(new ArrayList<>());
visited = new int[numCourses];
result = new int[numCourses];
index = numCourses - 1; // 从栈底开始存储
// 构造边表
for(int[] prerequisite : prerequisites)
edges.get(prerequisite[1]).add(prerequisite[0]);
// 每次挑选一个未搜索的结点,开始进行DFS
for(int i = 0; i < numCourses && valid; ++i)
if(visited[i] == 0) dfs(i);
if(!valid) return new int[0];
return result;
}
// 通过 DFS 设置 valid
void dfs(int u) {
visited[u] = 1; // 搜索中
for(int v : edges.get(u)) {
if(visited[v] == 0) {
dfs(v);
if(!valid) return; // 有环立即结束
} else if(visited[v] == 1) {
valid = false;
return;
}
}
visited[u] = 2; // 已完成
result[index--] = u; // 完成的节点入栈
}
方法二:BFS
考虑拓扑排序中最前面的点,该结点一定不会有任何入边。将一个结点加入结果序列之后,就可以移除它的所有出边,表示它的出邻居少了一门先导课程。如果某个出邻居变成了 没有任何入边的结点,就说明这个邻居可以加入结果序列了。按照这样的流程,不断地将没有入边的结点加入结果序列,直到:
- 结果序列包含所有结点——得到一种拓扑排序;或者
- 不存在没有入边的结点——存在环。
具体算法如下:
使用一个队列(而不是栈)来进行BFS,开始时,所有入度为 0 的结点都被放入队列,他们就是可以作为拓扑排序中最前面的那些结点,并且它们之间的相对顺序无关紧要。
在 BFS 每一步中,首先取出队首节点 u:
- 将 u 放入结果序列;
- 将 u 的所有出邻居的入度减少 1,此时如果某个结点的入度变成了 0,就将它放入队列中。
在 BFS 结束后,如果结果序列长度为 n,则说明找到了一个拓扑排序;否则说明有环。
List<List<Integer>> edges;
int[] indegree;
int[] result;
int index;
int[] findOrder(int numCourses, int[][] prerequisites) {
edges = new ArrayList<>();
for(int i = 0; i < numCourses; i++)
edges.add(new ArrayList<>());
indegree = new int[numCourses];
result = new int[numCourses];
index = 0;
// 构造边表并统计入度
for(int [] prerequisite : prerequisites) {
edges.get(prerequisite[1]).add(prerequisite[0]);
indegree[prerequisite[0]]++; // 入度加1
}
Queue<Integer> queue = new LinkedList<>();
for(int i = 0; i < numCourses; i++)
if(indgree[i] == 0) queue.offer(i);
while(!queue.isEmpty()) {
int u = queue.poll();
result[index++] = u;
for(int v : edges.get(u)) {
indegree[v]--;
if(indgree[v] == 0)
queue.offer(v);
}
}
if(index != numCourses)
return new int[0];
return result;
}




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义