OO第三单元总结——JML规格
一、JML简介
1.JML语言的理论基础
-
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言 (Behavior Interface Specification Language,BISL),基于Larch方法构建。BISL提供了对方法和类型的规格定义手段。
- 一般而言,JML有两种主要的用法:
(1)开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。
(2)针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义
基本语言:
1.注释结构
行注释的表示方式 为 //@annotation ,块注释的方式为 /* @ annotation @*/ 。
2.JML表达式
2.1 原子表达式
\result表达式、\old( expr )表达式、\not_assigned(x,y,...)表达式、\not_modified(x,y,...)表达式、\nonnullelements( container )表达式、\type(type)表达式、\typeof(expr)表达式……
2.2 量化表达式
\forall表达式、\exists表达式、\sum表达式、\product表达式、\max表达式、\min表达式、\num_of表达式……
2.3 集合表达式
集合构造表达式:可以在JML规格中构造一个局部的集合(容器),明确集合中可以包含的元素。
2.4 操作符
(1) 子类型关系操作符: E1<:E2
(2) 等价关系操作符: b_expr1<==>b_expr2
(3) 推理操作符: b_expr1==>b_expr2
(4) 变量引用操作符
3. 方法规格
(1) 前置条件(pre-condition) : requires P; 。
(2) 后置条件(post-condition) : ensures P; 。
(3) 副作用范围限定(side-effects) : assignable 或者 modifiable 。
4. 类型规格
JML针对类型规格定义了多种限制规则,从课程的角度,我们主要涉及两类,不变式限制(invariant)和约束限制 (constraints)。无论哪一种,类型规格都是针对类型中定义的数据成员所定义的限制规则,一旦违反限制规则,就称 相应的状态有错。
2.工具链
JML的一大优势就在于其丰富的外围工具,它们都被罗列在了http://www.eecs.ucf.edu/~leavens/JML//download.shtml上。其中比较重要的几个如下:
- OpenJML:首选的JML相关工具,以提供全面且支持最新Java标准的JML相关支持为目标,能够进行静态规格检查(ESC,Extended Static Cheking)、运行时规格检查(RAC,Runtime Assertion Checking)和形式化验证等一系列功能。OpenJML提供了自带的命令行版本和Eclipse插件版本。
- JML Editing:官方的Eclipse插件,提供了JML规格的代码高亮及代码补全。
- JMLUnitNG:JMLUnit的替代工具,能够根据JML规格自动生成基于测试库TestNG的单元测试集。
- jmldoc:能够通过JML生成javadoc的工具。现已合并入OpenJML中。
JML还有一系列其他工具,但是这些工具大都是从不同角度根据规格进行代码测试的,这些功能已被OpenJML所涵盖。
二、部署SMT Solver进行验证
略(选做)
三、部署JMLUnitNG并针对Graph接口的实现进行测试
-
JMLUnitNG的部署方法仰仗伦佬。
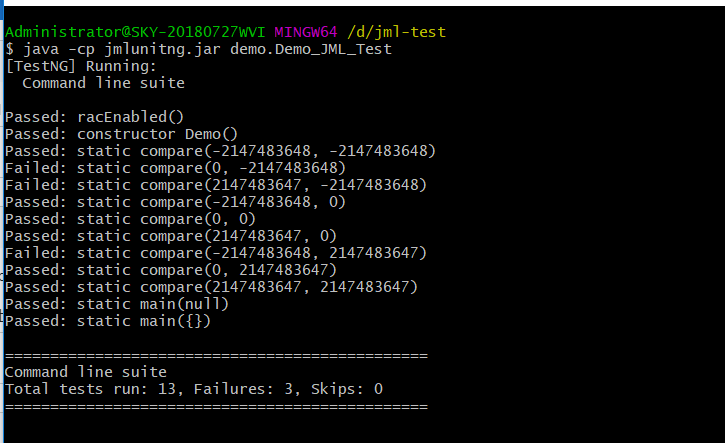
- 以下是测试结果
[TestNG] Running: Command line suite Passed: racEnabled() Passed: constructor MyGraph() Passed: <<homework.MyGraph@18ef96>>.addPath(null) Passed: <<homework.MyGraph@ba4d54>>.containsEdge(-2147483648, -2147483648) Passed: <<homework.MyGraph@de0a01f>>.containsEdge(0, -2147483648) Passed: <<homework.MyGraph@4c75cab9>>.containsEdge(2147483647, -2147483648) Passed: <<homework.MyGraph@1ef7fe8e>>.containsEdge(-2147483648, 0) Passed: <<homework.MyGraph@6f79caec>>.containsEdge(0, 0) Passed: <<homework.MyGraph@67117f44>>.containsEdge(2147483647, 0) Passed: <<homework.MyGraph@5d3411d>>.containsEdge(-2147483648, 2147483647) Passed: <<homework.MyGraph@2471cca7>>.containsEdge(0, 2147483647) Passed: <<homework.MyGraph@5fe5c6f>>.containsEdge(2147483647, 2147483647) Passed: <<homework.MyGraph@6979e8cb>>.containsNode(-2147483648) Passed: <<homework.MyGraph@763d9750>>.containsNode(0) Passed: <<homework.MyGraph@2be94b0f>>.containsNode(2147483647) Passed: <<homework.MyGraph@d70c109>>.containsPathId(-2147483648) Passed: <<homework.MyGraph@17ed40e0>>.containsPathId(0) Passed: <<homework.MyGraph@50675690>>.containsPathId(2147483647) Skipped: <<homework.MyGraph@31b7dea0>>.containsPath(null) Passed: <<homework.MyGraph@3ac42916>>.getDist() Passed: <<homework.MyGraph@47d384ee>>.getDistinctNodeCount() Passed: <<homework.MyGraph@2d6a9952>>.getGraph() Failed: <<homework.MyGraph@22a71081>>.getPathById(-2147483648) Failed: <<homework.MyGraph@3930015a>>.getPathById(0) Failed: <<homework.MyGraph@629f0666>>.getPathById(2147483647) Failed: <<homework.MyGraph@1bc6a36e>>.getPathId(null) Failed: <<homework.MyGraph@1ff8b8f>>.getShortestPathLength(-2147483648, -2147483648) Failed: <<homework.MyGraph@387c703b>>.getShortestPathLength(0, -2147483648) Failed: <<homework.MyGraph@224aed64>>.getShortestPathLength(2147483647, -2147483648) Failed: <<homework.MyGraph@c39f790>>.getShortestPathLength(-2147483648, 0) Failed: <<homework.MyGraph@71e7a66b>>.getShortestPathLength(0, 0) Failed: <<homework.MyGraph@2ac1fdc4>>.getShortestPathLength(2147483647, 0) Failed: <<homework.MyGraph@5f150435>>.getShortestPathLength(-2147483648, 2147483647) Failed: <<homework.MyGraph@1c53fd30>>.getShortestPathLength(0, 2147483647) Failed: <<homework.MyGraph@50cbc42f>>.getShortestPathLength(2147483647, 2147483647) Passed: <<homework.MyGraph@75412c2f>>.getUpdateDist() Failed: <<homework.MyGraph@282ba1e>>.isConnected(-2147483648, -2147483648) Failed: <<homework.MyGraph@13b6d03>>.isConnected(0, -2147483648) Failed: <<homework.MyGraph@f5f2bb7>>.isConnected(2147483647, -2147483648) Failed: <<homework.MyGraph@73035e27>>.isConnected(-2147483648, 0) Failed: <<homework.MyGraph@64c64813>>.isConnected(0, 0) Failed: <<homework.MyGraph@3ecf72fd>>.isConnected(2147483647, 0) Failed: <<homework.MyGraph@483bf400>>.isConnected(-2147483648, 2147483647) Failed: <<homework.MyGraph@21a06946>>.isConnected(0, 2147483647) Failed: <<homework.MyGraph@77f03bb1>>.isConnected(2147483647, 2147483647) Failed: <<homework.MyGraph@326de728>>.removePathById(-2147483648) Failed: <<homework.MyGraph@25618e91>>.removePathById(0) Failed: <<homework.MyGraph@7a92922>>.removePathById(2147483647) Failed: <<homework.MyGraph@71f2a7d5>>.removePath(null) Passed: <<homework.MyGraph@2cfb4a64>>.size() =============================================== Command line suite Total tests run: 50, Failures: 26, Skips: 1 ===============================================
- 我还按伦佬的流程,实际操作了一遍。菜菜的我需要反复练习……
四、梳理框架设计
第一次作业:
老老实实按照官方提供的接口写的。
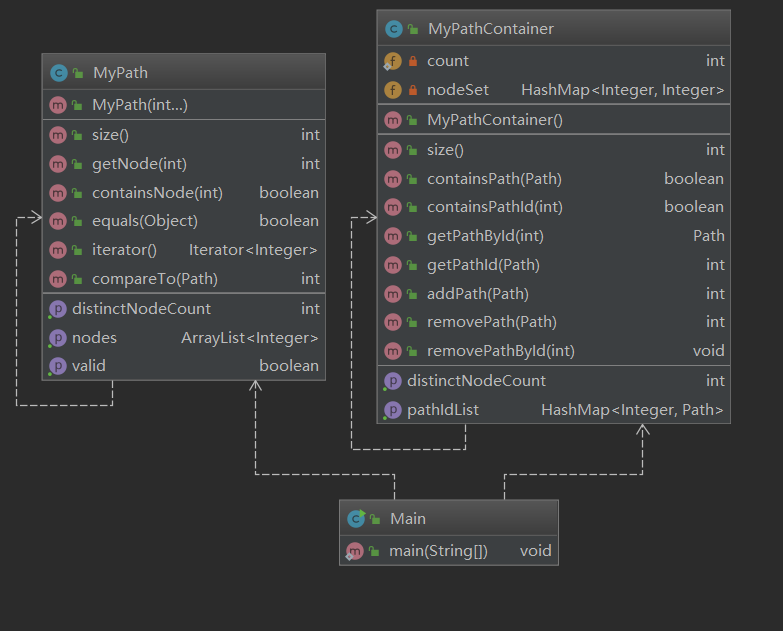
第二次作业:(下图是我debug之后的代码框架。与之前的代码相比,框架是相同的,只是部分存储的数据结构不同)
作业框架基本和接口一样。第二次作业主要在MyPathContaineri的基础上增加了几个接口,我没有选择继承,而是直接Ctrl C 、Ctrl V了(捂脸)。

第三次作业:
难度提升,这一次的框架还是按照官方给的接口来写的。不过我将对图的操作以及floyd算法的操作封装成了一个类MyMap类。
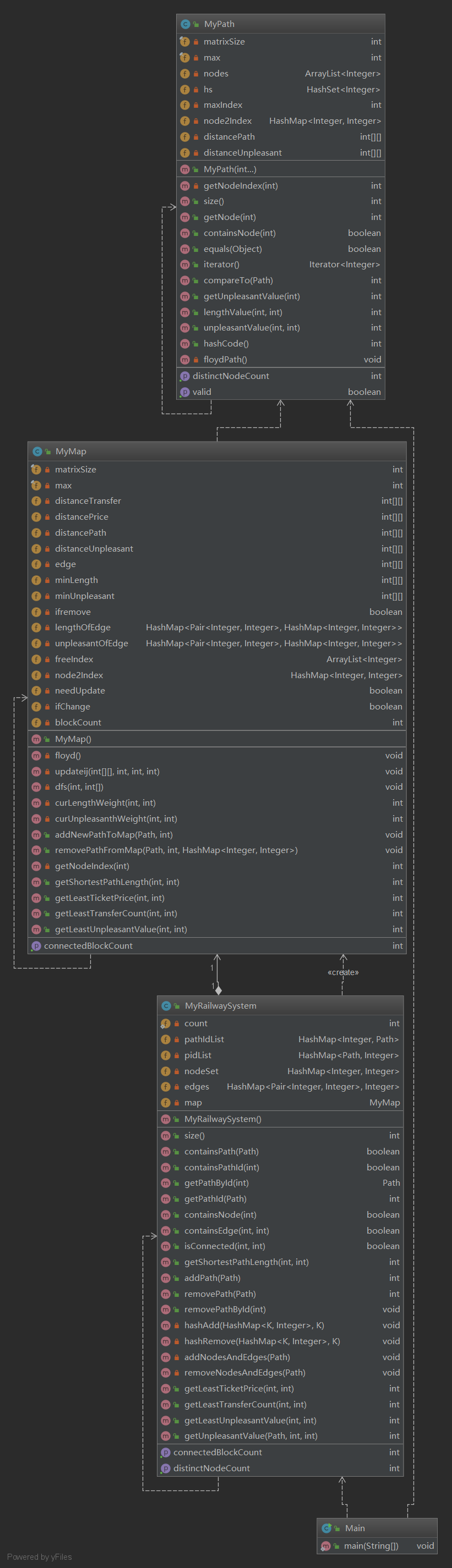
这三次作业我的框架是没变的,第二次和第三次我用的都是邻接矩阵初始化距离矩阵,利用floyd算法来求最小权重的路径。不过在第二次作业TLE之后,我发现hashmap在这种算法下远不如静态数据运算快,所以第三次作业是用的静态数组来完成的算法。
五、分析代码实现的bug和修复情况
第一次作业:
这次作业实现难度不大,关键在于复杂度的控制。在这次作业中,我利用了已有的容器(如 hashmap 、hashset等)来减少我自己写的代码量。当初想着,这些已经有的容器的算法肯定比我写得强多了,却没真正深入探究容器自身实现的复杂度。
Mypath类中,当需要getDistinctNodeCount时,我都会new一个hashset来统计。这对path这个类来说,确实是比较简单且复杂度低的方法。
但是我在MyPathContainer 类里偷懒,依然用的是这个方法。然而MyPathContainer类里会频繁地add和remove,导致每当getDistinctNodeCount时,我都会重头统计,复杂度是O(n)。这一问题让我在强测中TLE了。
bug修复时,我通过增加一个HashMap存储当前某个节点出现了多少次,将复杂度分散到add和remove操作中,getDistinctNodeCount时只需输出当前hashmap的size即可,复杂度降到了O(1)。
第二次作业:
对于第二次作业新增的方法,我运用的是Floyd算法来完成的。考虑到add和remove的指令占比很小,选择Floyd算法是非常合适的,第二、三作业的结果也证实了这一点。
不过这次我还是TLE了,我入了hashmap的坑。我本想,第二次作业是个稀疏矩阵,用hashmap存储会更节俭一点。却万万没想到,在有下标索引的情况下,静态数组查询、更新等的实现速度是远远快于hashmap 的。从此,我对hashmap的蜜汁好感产生了动摇……
第三次作业:
这一次作业我机智地没有选择拆点法(听说拆点法很难写而且运行时间太久……)
我选择了另一种主流思想,每一条Path连成一个完全图存入MyMap中。当初做抉择的时候,考虑到拆点法是在删增Path的时候需与图中几乎全部的信息比对来动态改变每个节点的个数,而完全图的方法的任何一个操作都是对一个Path独立的(加是加一个完全图,删是删一个完全图),并不需要与其他Path进行比较。基于这一点,我觉得完全图这种简单的构图方式比较适合我。
我估计是对TLE产生了心里阴影,这次我是在我能力范围内尽可能地优化复杂度,结果把自己给优化死了……这次求最少换乘次数、最短路径(最少票价)、最小不满意度,都是同一张图,但是赋三种权值。
由算法的实现可知,每条边的权值都要是这条边在它所属的所有path中权值最小的。我为每条边存储了一个他所属的Path的id和在这个Path中它的权值的栈。add和remove的时候,给距离矩阵初始化的时候,就会从每个边的栈中找到最小的权值给它附上。可是我在我这些优化的时候,因为一些笔误导致我更新遗漏,强测wa了。
六、对规格撰写和理解上的心得体会
感觉规格专业很像离散数学中的谓词逻辑,所以理解起来并不是很难。
主要的体会是:
规格只是对结果的描述,却没有限定实现的具体方法;
规格定义中只能调用pure方法,描述的是状态而非动态过程。

