上一篇博客介绍了logback的StaticLoggerBinder类怎么初始化并创建LoggerContext,这篇博客准备接下来介绍一下,LoggerContext怎么创建日志框架真正的核心类Logger。为什么logback框架提供的Logger是树形结构的呢?这就是在LoggerContext里实现的
还是先上图,对LoggerContext和周边类的关系有一个整体上的认识
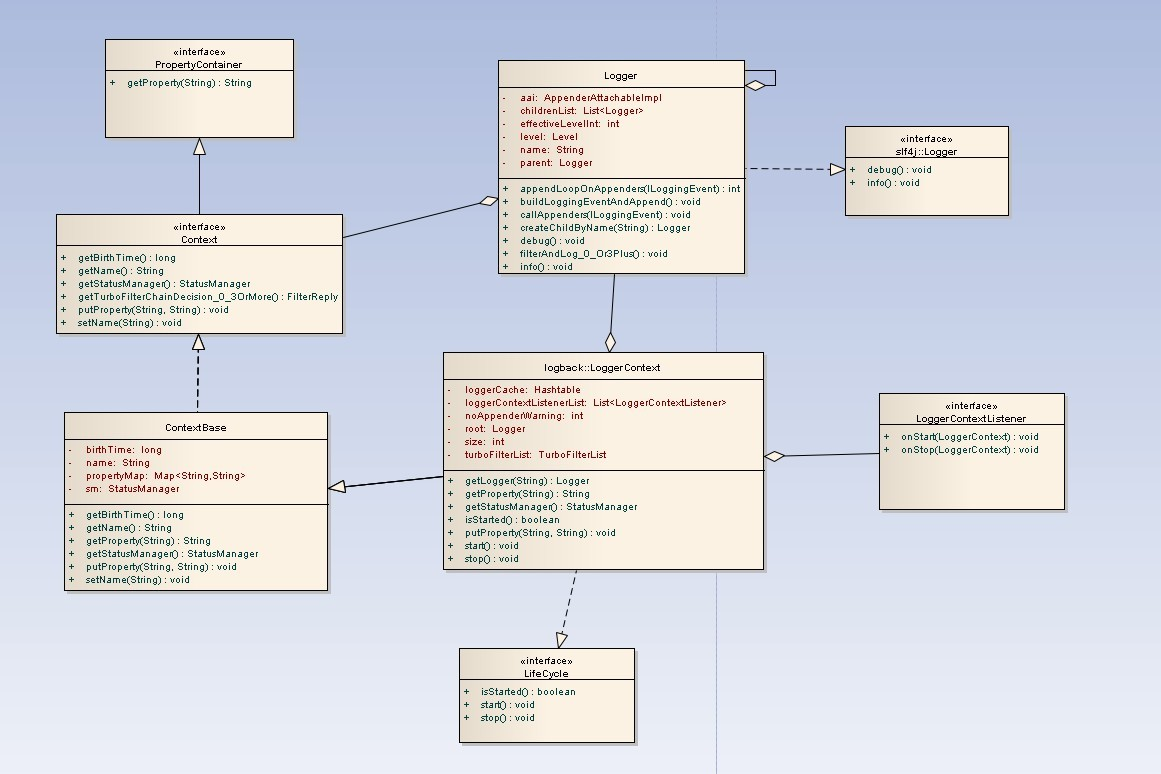
从图中可以看到,LoggerContext类除了ILoggerFactory接口之外,还实现了LifeCycle接口,并继承自ContextBase类
LoggerContext最核心的方法是getLogger(String name),这个方法放在最后介绍,先介绍一下其它字段和方法,这些字段和方法,大部分都是为了getLogger()方法服务的
首先需要澄清一点,虽然LoggerContext没有显式地采用单例模式,但实际上应用从来不会直接获取到LoggerContext类的实例,都是通过StaticLoggerBinder内的defaultLoggerContext字段来间接引用LoggerContext的实例,而StaticLoggerBinder本身是单例的,所以程序中用到的LoggerContext也始终是同一个实例,这点很重要
看看LoggerContext内的字段
public class LoggerContext extends ContextBase implements ILoggerFactory, LifeCycle { /** Default setting of packaging data in stack traces */ public static final boolean DEFAULT_PACKAGING_DATA = false; final Logger root; private int size; private int noAppenderWarning = 0; final private List<LoggerContextListener> loggerContextListenerList = new ArrayList<LoggerContextListener>(); private Map<String, Logger> loggerCache; private LoggerContextVO loggerContextRemoteView; private final TurboFilterList turboFilterList = new TurboFilterList(); private boolean packagingDataEnabled = DEFAULT_PACKAGING_DATA; private int maxCallerDataDepth = ClassicConstants.DEFAULT_MAX_CALLEDER_DATA_DEPTH; int resetCount = 0; private List<String> frameworkPackages;
1、root是根Logger
2、size用来表示LoggerContext一共创建了几个Logger
3、loggerCache的名字起得有点误导性,实际上不止是一个cache,LoggerContext创建的所有Logger,都保存在这里
4、loggerContextRemoteView是一个LoggerContext的VO对象,保存了LoggerContext的一些值,比如name、birthTime等,大家可以自己看看
5、turboFilterList保存所有的TurboFilter,TurboFilter顾名思义,是一种快速过滤器,对是否记录日志有一票通过和一票否决的权力,后面的博客在介绍Filter时,会专门介绍
6、resetCount是用来统计该LoggerContext调用过几次reset()方法
7、其它几个字段,我暂时不太清楚是干什么的
来看看LoggerContext的构造方法吧
public LoggerContext() { super(); this.loggerCache = new ConcurrentHashMap<String, Logger>(); this.loggerContextRemoteView = new LoggerContextVO(this); this.root = new Logger(Logger.ROOT_LOGGER_NAME, null, this); this.root.setLevel(Level.DEBUG); loggerCache.put(Logger.ROOT_LOGGER_NAME, root); initEvaluatorMap(); size = 1; this.frameworkPackages = new ArrayList<String>(); }
这个方法基本上是只会调用一次的,在StaticLoggerBinder里
public ILoggerFactory getLoggerFactory() { if (!initialized) { return defaultLoggerContext; } if (contextSelectorBinder.getContextSelector() == null) { throw new IllegalStateException("contextSelector cannot be null. See also " + NULL_CS_URL); } return contextSelectorBinder.getContextSelector().getLoggerContext(); }
在构造LoggerContext的时候,对上面提到的字段进行了初始化,并创建了根Logger
final FilterReply getTurboFilterChainDecision_0_3OrMore(final Marker marker, final Logger logger, final Level level, final String format, final Object[] params, final Throwable t) { if (turboFilterList.size() == 0) { return FilterReply.NEUTRAL; } return turboFilterList.getTurboFilterChainDecision(marker, logger, level, format, params, t); }
这个方法命名很烂,从命名上完全看不出这个方法的意图。该方法主要是在Logger要记录日志之前,用TurboFilter做一下过滤先,如果没有配置TurboFilter,就跳过过滤;否则的话,用TurboFilter做一下过滤。这部分内容涉及到fitler过滤,会在后面的博客里详细介绍
这个类中还有一系列侦听器方法,这篇博客先略过
接下来就是核心的getLogger()方法
public final Logger getLogger(final Class<?> clazz) { return getLogger(clazz.getName()); } @Override public final Logger getLogger(final String name) { // 1、如果name是null,抛出异常,不过这个情况基本是不会发生的 if (name == null) { throw new IllegalArgumentException("name argument cannot be null"); } // 2、如果请求的是ROOT Logger,那么就直接返回root if (Logger.ROOT_LOGGER_NAME.equalsIgnoreCase(name)) { return root; } int i = 0; Logger logger = root; // 3、然后检查一下请求的Logger是否已经创建过了,如果已经创建过,就直接从loggerCache中返回 Logger childLogger = (Logger) loggerCache.get(name); // if we have the child, then let us return it without wasting time if (childLogger != null) { return childLogger; } // 如果还没创建过,那就开始逐层创建,比如请求的Logger的name是com.company.package.ClassName,
// 那么一共会创建4个Logger,分别是Logger[com]、Logger[com.company]、Logger[com.company.package]、Logger[com.company.package.ClassName] String childName; while (true) { int h = LoggerNameUtil.getSeparatorIndexOf(name, i); if (h == -1) { childName = name; } else { childName = name.substring(0, h); } // move i left of the last point i = h + 1; synchronized (logger) { childLogger = logger.getChildByName(childName); if (childLogger == null) { childLogger = logger.createChildByName(childName); loggerCache.put(childName, childLogger); incSize(); } } logger = childLogger; if (h == -1) { return childLogger; } } }
上面代码比较清晰,就是根据"."来解析name,然后创建Logger,每创建一个Logger,都放到loggerCache中,并且把size++
创建Child Logger是有点讲究的,除了创建Logger实例之外,还有维护父子关系,并且处理Level继承的问题,这个是在Logger类的createChildByName(String childName)方法里实现的
Logger createChildByName(final String childName) { int i_index = LoggerNameUtil.getSeparatorIndexOf(childName, this.name.length() + 1); if (i_index != -1) { throw new IllegalArgumentException("For logger [" + this.name + "] child name [" + childName + " passed as parameter, may not include '.' after index" + (this.name.length() + 1)); } if (childrenList == null) { childrenList = new CopyOnWriteArrayList<Logger>(); } Logger childLogger; childLogger = new Logger(childName, this, this.loggerContext); childrenList.add(childLogger); childLogger.effectiveLevelInt = this.effectiveLevelInt; return childLogger; }
首先检查一下name是否是合法的。然后创建childLogger
Logger(String name, Logger parent, LoggerContext loggerContext) { this.name = name; this.parent = parent; this.loggerContext = loggerContext; }
在上面的this.parent = parent里,设置了父Logger
然后在childrenList.add(childLogger)里,将新创建的Logger加到子Logger列表里
最后把子Logger的生效级别设置为当前Logger的生效级别
总结一下创建Logger的完整流程:
1、如果请求ROOT logger,则直接返回root
2、如果请求的Logger已经存在,则直接返回
3、如果请求的Logger尚未创建,则从ROOT开始,级联创建所有Logger
4、每创建一个Logger,都要设置父子关系,继承生效级别(至于Appender是怎么继承的,在后面的博客里介绍)
5、每创建一个Logger,都将其放入loggerCache,并将size++
关于在每次调用LoggerFactory.getLogger(String name)时,logback是怎么返回Logger的,这篇博客就介绍完了。下一篇博客会介绍,当调用Logger.info(String msg)时,会发生的事情
参考:
由于使用的版本较高,本文稍有不同,新版本中也见到很多新的编程思想
