一、为什么需要持久化
redis里有10gb数据,突然停电或者意外宕机了,再启动的时候10gb都没了?!所以需要持久化,宕机后再通过持久化文件将数据恢复。
二、优缺点
1、rdb文件
rdb文件都是二进制,很小。比如内存数据有10gb,rdb文件可能就1gb,只是举例。
2、优点
-
由于rdb文件都是二进制文件,所以很小,在灾难恢复的时候会快些。
-
他的效率(主进程处理命令的效率,而不是持久化的效率)相对于aof要高(bgsave而不是save),因为每来个请求他都不会处理任何事,只是bgsave的时候他会fork()子进程且可能copyonwrite,但copyonwrite只是一个寻址的过程,纳秒级别的。而aof每次都是写盘操作,毫米级别。没法比。
3、缺点
数据可靠性比aof低,也就是会丢失的多。因为aof可以配置每秒都持久化或者每个命令处理完就持久化一次这种高频率的操作,而rdb的话虽然也是靠配置进行bgsave,但是没有aof配置那么灵活,也没aof持久化快,因为rdb每次全量,aof每次只追加。
三、RDB持久化的两种方法
配置文件也可以配置触发rdb的规则。配置文件配置的规则采取的是bgsave的原理。
1、save
1.1、描述
同步、阻塞
1.2、缺点
致命的问题,持久化的时候redis服务阻塞(准确的说会阻塞当前执行save命令的线程,但是redis是单线程的,所以整个服务会阻塞),不能继对外提供请求,GG!数据量小的话肯定影响不大,数据量大呢?每次复制需要1小时,那就相当于停机一小时。
2、bgsave
2.1、描述
异步、非阻塞
2.2、原理
fork() + copyonwrite
2.3、优点
他可以一边进行持久化,一边对外提供读写服务,互不影响,新写的数据对我持久化不会造成数据影响,你持久化的过程中报错或者耗时太久都对我当前对外提供请求的服务不会产生任何影响。持久化完会将新的rdb文件覆盖之前的。
四、fork()
bgsave原理是fork() + copyonwrite,那么现在来聊一下fork()
1、fork()是什么
fork()是unix和linux这种操作系统的一个api,而不是Redis的api。
2、fork()有什么用
fork()用于创建一个子进程,注意是子进程,不是子线程。fork()出来的进程共享其父类的内存数据。仅仅是共享fork()出子进程的那一刻的内存数据,后期主进程修改数据对子进程不可见,同理,子进程修改的数据对主进程也不可见。
比如:A进程fork()了一个子进程B,那么A进程就称之为主进程,这时候主进程子进程所指向的内存空间是同一个,所以他们的数据一致。但是A修改了内存上的一条数据,这时候B是看不到的,A新增一条数据,删除一条数据,B都是看不到的。而且子进程B出问题了,对我主进程A完全没影响,我依然可以对外提供服务,但是主进程挂了,子进程也必须跟随一起挂。这一点有点像守护线程的概念。Redis正是巧妙的运用了fork()这个牛逼的api来完成RDB的持久化操作。
五、Redis中的fork()
Redis巧妙的运用了fork()。当bgsave执行时,Redis主进程会判断当前是否有fork()出来的子进程,若有则忽略,若没有则会fork()出一个子进程来执行rdb文件持久化的工作,子进程与Redis主进程共享同一份内存空间,所以子进程可以搞他的rdb文件持久化工作,主进程又能继续他的对外提供服务,二者互不影响。
我们说了他们之后的修改内存数据对彼此不可见,但是明明指向的都是同一块内存空间,这是咋搞得?肯定不可能是fork()出来子进程后顺带复制了一份数据出来,如果是这样的话比如我有4g内存,那么其实最大有限空间是2g,我要给rdb留出一半空间来,扯淡一样!那他咋做的?采取了copyonwrite技术。
六、copyonwrite
很简单,现在不就是主进程和子进程共享了一块内存空间,怎么做到的彼此更改互不影响吗?
1、原理
主进程fork()子进程之后,内核把主进程中所有的内存页的权限都设为read-only,然后子进程的地址空间指向主进程。这也就是共享了主进程的内存,当其中某个进程写内存时(这里肯定是主进程写,因为子进程只负责rdb文件持久化工作,不参与客户端的请求),CPU硬件检测到内存页是read-only的,于是触发页异常中断(page-fault),陷入内核的一个中断例程。
中断例程中,内核就会把触发的异常的页复制一份(这里仅仅复制异常页,也就是所修改的那个数据页,而不是内存中的全部数据),于是主子进程各自持有独立的一份。
数据修改之前的样子

数据修改之后的样子
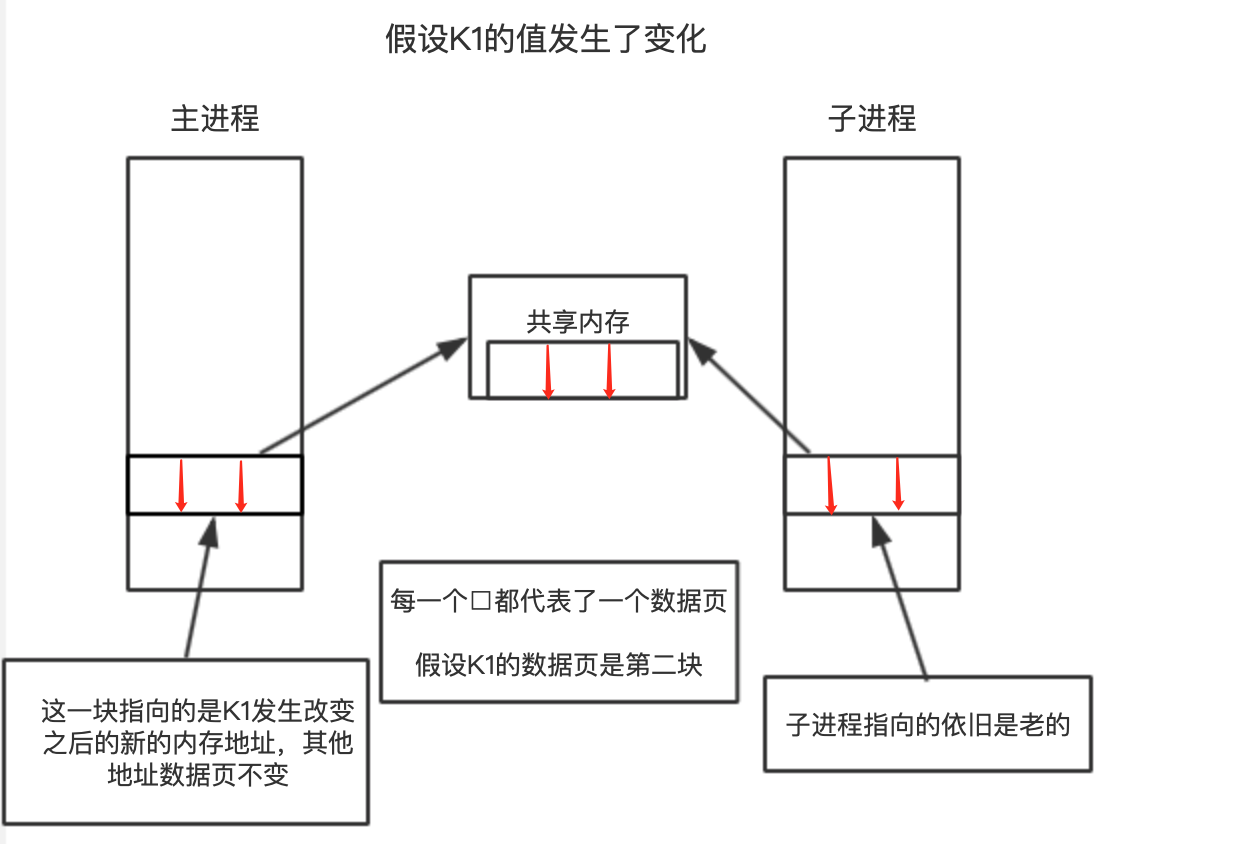
2、回到原问题
其实就是更改数据的之前进行copy一份更改数据的数据页出来,比如主进程收到了set k 1请求(之前k的值是2),然后这同时又有子进程在rdb持久化,那么主进程就会把k这个key的数据页拷贝一份,并且主进程中k这个指针指向新拷贝出来的数据页地址上,然后进行更改值为1的操作,这个主进程k元素地址引用的新拷贝出来的地址,而子进程引用的内存数据k还是修改之前的。
3、一段话总结
copyonwritefork()出来的子进程共享主进程的物理空间,当主子进程有内存写入操作时,read-only内存页发生中断,将触发的异常的内存页复制一份(其余的页还是共享主进程的)。
4、额外补充
在 Redis 服务中,子进程只会读取共享内存中的数据,它并不会执行任何写操作,只有主进程会在写入时才会触发这一机制,而对于大多数的 Redis 服务或者数据库,写请求往往都是远小于读请求的,所以使用fork()加上写时拷贝这一机制能够带来非常好的性能,也让BGSAVE这一操作的实现变得很简单。
七、疑问
0、调用fork()也会阻塞啊
我只能说没毛病,但是这个阻塞真的可以忽略不计。尤其是相对于阻塞主线程的save。
1、会同时存在多个子进程吗?
不会,主进程每次收到bgsave命令需要fork()子进程之前都会判断是否存在子进程了,若存在也会忽略掉这次bgsave请求。若不存在我会fork()出子进程进行工作。
为什么这么搞?
我猜测原因如下:
-
如果支持并行存在多个子进程,那么不仅会拉低服务器性能,还会造成数据问题,比如八点的bgsave在工作,九点又来个bgsave命令。这时候九点的先执行完了,八点的后执行完了,那九点的不白执行了吗?这是我所谓的数据问题。再比如,都没执行完,十点又开一个bgsave,越积越多,服务器性能被拉低。
-
那为什么不阻塞?判断有子进程在工作,就等待,等他执行完我在上场,那一样,越积越多,文件过大,只会造成堆积。
2、如果没有copyonwrite这种技术是什么效果?
-
假设是全量复制,那么内存空间直接减半,浪费资源不说,数据量10g,全量复制这10g的时间也够长的。这谁顶得住?
-
如果不全量复制,会是怎样?相当于我一边复制,你一边写数据,看着貌似问题不大,其实不然。比如现在Redis里有k1的值是1,k2的值是2,比如bgsave了,这时候rdb写入了k1的值,在写k2的值之前时,有个客户端请求
set k1 11
set k2 22
那么持久化进去的是k2 22,但是k1的值还是1,而不是最新的11,所以会造成数据问题,所以采取了copyonwrite技术来保证触发bgsave请求的时候无论你怎么更改,都对我rdb文件的数据持久化不会造成任何影响。
八、总结
此篇都是重点,废话很少。没啥可总结的。Redis作者对底层操作系统了解的很多,先是epoll,又是现在的fork()和copyonwrite。佩服三连!!!

