1.
|
版本
|
对应特性
|
|
1.0
|
安全
HBase(append / hsynch / hflush和安全性)
webhdfs(全面支持安全性)
性能增强了对HBase对本地文件的访问
其他性能增强,错误修复和功能
|
|
1.1
|
从主干向后移植HDFS的许多性能改进
使用SPNEGO而不是Kerberized SSL进行HTTP事务的安全性方面的改进
将任务跟踪器的默认最小心跳从3秒降低到300毫秒,以增加小型集群上的作业吞吐量
Gridmix v3的端口
在hadoop-config.sh中设置MALLOC_ARENA_MAX以解决RHEL-6中的glibc问题
可拆分的bzip2文件
|
|
2.0
|
NameNode的HDFS HA(手动故障转移)
YARN又名NextGen
MapReduce
HDFS联盟
性能
HDFS和YARN/MapReduce的电线兼容性(使用protobufs)
|
|
2.2.
|
YARN-Hadoop的通用资源管理系统,允许MapReduce和其他其他数据处理框架和服务
HDFS的高可用性
HDFS联盟
HDFS快照
NFSv3访问HDFS中的数据
支持在Microsoft Windows上运行Hadoop
在hadoop-1.x上构建的MapReduce应用程序的二进制兼容性
与生态系统中其他项目的大量集成测试
|
|
2.3
|
支持HDFS中的异构存储层次结构。
HDFS数据的内存中缓存,具有集中式管理和管理功能。
通过YARN分布式缓存中的HDFS简化了MapReduce二进制文件的分发。
|
|
2.4
|
支持HDFS中的访问控制列表
对HDFS中的滚动升级的本机支持
为HDFS FSImage使用协议缓冲区以实现平稳的操作升级
HDFS中完整的HTTPS支持
支持YARN ResourceManager的自动故障转移
使用应用程序历史记录服务器和应用程序时间轴服务器增强了对YARN上新应用程序的支持
通过抢占支持YARN CapacityScheduler中的强大SLA
|
|
2.5
|
使用HTTP代理服务器时的身份验证改进。
一个新的Hadoop Metrics接收器,允许直接写入Graphite。
Hadoop兼容文件系统工作规范。
支持POSIX样式的文件系统扩展属性。
OfflineImageViewer通过WebHDFS API浏览fsimage。
NFS网关的可支持性改进和错误修复。
HDFS守护程序的现代化Web UI(HTML5和Javascript)。
YARN的REST API支持提交和杀死应用程序。
YARN的时间轴存储的Kerberos集成。
FairScheduler允许在运行时在任何指定的父队列下创建用户队列。
|
|
2.6
|
Hadoop常见
HADOOP-10433-密钥管理服务器(测试版)
HADOOP-10607-凭据提供程序(测试版)
Hadoop HDFS
异构存储层-第二阶段
HDFS-5682-用于异构存储的应用程序API
HDFS-7228 -SSD存储层
HDFS-5851-内存作为存储层(测试版)
HDFS-6584-支持档案存储
HDFS-6134-透明的静态数据加密(测试版)
HDFS- 2856-在无需root用户访问的情况下操作安全的DataNode
HDFS-6740-热插拔驱动器:支持添加/删除数据节点卷,而无需重新启动数据节点(测试版)
HDFS-6606 -AES支持更快的线路加密
Hadoopyarn
YARN-896-在YARN中支持长期运行的服务
YARN-913-应用程序的服务注册表
YARN-666-支持滚动升级
YARN-556 -ResourceManager的工作保留重启
YARN-1336 -NodeManager的保留容器重新启动
YARN-796-调度期间的支持节点标签
YARN-1051-在Capacity Scheduler(beta)中支持基于时间的资源保留
YARN-1964-支持在Docker容器中本地运行应用程序(alpha)
|
|
2.7
|
此版本放弃了对JDK6运行时的支持,并且仅与JDK 7+一起使用。
此版本尚未准备好用于生产。关键问题正在通过测试和下游采用得到解决。生产用户应等待2.7。1 / 2 .7.2释放。
Hadoop常见
HADOOP-9629-支持Windows Azure存储-Blob作为Hadoop中的文件系统。
Hadoop HDFS
HDFS-3107-支持文件截断
HDFS-7584-支持每种存储类型的配额
HDFS-3689-支持具有可变长度块的文件
Hadoopyarn
YARN-3100-使YARN授权可插入
YARN-1492 -YARN本地化资源的自动共享,全局缓存(测试版)
Hadoop MapReduce
MAPREDUCE-5583-能够限制作业的正在运行的Map / Reduce任务
MAPREDUCE-4815-对于具有许多输出文件的超大型作业,可以加快FileOutputCommitter的速度。
|
|
2.8
|
共同
支持异步呼叫重试和故障转移,可在重试工作中用于异步DFS实现。
可以通过通用的servlet过滤器为UI提供跨框架脚本(XFS)防护。
S3A改进:增加了插入任何AWSCredentialsProvider的功能,除了XML配置文件之外,还支持从hadoop凭据提供程序API读取s3a凭据,支持Amazon
STS临时凭据
WASB的改进:添加了附加API支持
Build增强功能:将开发支持替换为Yetus的包装,提供基于docker的解决方案来设置构建环境,删除CHANGES.txt并重新制作更改日志和发行说明。
添加对LDAP组映射服务的posixGroups支持。
支持与Azure数据湖(ADL)集成,作为与Hadoop兼容的替代文件系统。
HDFS
WebHDFS增强功能:在WebHDFS中集成CSRF预防过滤器,在WebHDFS中支持OAuth2,通过WebHDFS禁用/允许快照
允许长时间运行的Balancer使用keytab登录
添加ReverseXML处理器,该处理器从XML文件重建fsimage。这将使创建fsimage进行测试变得容易,并且在损坏时手动编辑fsimage。
支持嵌套加密区域
DataNode生命线协议:一种用于报告DataNode活跃度的替代协议。这可以防止NameNode在心跳处理受到延迟的高度过载的群集中错误地将DataNode标记为陈旧或死机。
将HDFS操作的调用者上下文记录到审核日志中
一个新的Datanode命令,用于驱逐写入器,该命令在缓慢的写入器阻止数据节点退役时很有用。
yarn
Windows中的NodeManager CPU资源监视。
NM关闭更加顺畅:NM将立即注销到RM,而不是等待超时成为LOST(如果未启用NM工作保留)。
添加了在AM尝试卡住的情况下使特定AM尝试失败的功能。
YARN审核日志中的CallerContext支持。
ATS版本控制支持:一种新的配置,用于指示时间轴服务版本。
映射还原
允许节点标签在提交MR作业时被指定
添加新工具以将汇总的日志合并到HAR文件中
|
|
3.0
|
最低要求的Java版本从Java 7增加到Java 8
现在已针对Java 8的运行时版本编译了所有Hadoop
JAR。仍在使用Java 7或更低版本的用户必须升级到Java 8。
支持HDFS中的擦除编码
与复制相比,擦除编码是一种持久存储数据的方法,可节省大量空间。与标准HDFS复制的3倍开销相比,像Reed-Solomon(10,4)这样的标准编码的空间开销为1.4倍。
由于擦除编码在重建期间会带来额外的开销,并且大部分执行远程读取,因此传统上已将其用于存储较冷,访问频率较低的数据。用户在部署此功能时应考虑擦除编码的网络和CPU开销。
HDFS删除编码文档中提供了更多详细信息。
YARN时间轴服务v.2
我们正在介绍YARN时间轴服务主要版本:v.2的早期预览(alpha 2)。YARN Timeline Service v.2解决了两个主要挑战:提高Timeline Service的可伸缩性和可靠性,以及通过引入流和聚合来增强可用性。
提供了YARN Timeline
Service v.2 alpha 2,以便用户和开发人员可以对其进行测试并提供反馈和建议,以使其可以替代Timeline
Servicev.1.x。仅应以测试能力使用。
YARN时间轴服务v.2文档中提供了更多详细信息。
Shell脚本重写
Hadoop Shell脚本已被重写,以修复许多长期存在的错误并包括一些新功能。尽管一直在寻求兼容性,但是某些更改可能会破坏现有的安装。
不兼容的更改记录在发行说明中,并在HADOOP-9902上进行了相关讨论。
Unix Shell指南文档中提供了更多详细信息。高级用户也将对Unix Shell API文档感到满意,该文档描述了许多新功能,尤其是与可扩展性有关的功能。
带阴影的客户罐
2.x版本中提供的hadoop-client Maven工件将Hadoop的可传递依赖项拉到Hadoop应用程序的类路径中。如果这些传递依赖项的版本与应用程序使用的版本冲突,则可能会出现问题
HADOOP-11804添加了新的hadoop-client-api和hadoop-client-runtime工件,将Hadoop的依赖项隐藏在一个jar中。这样可以避免将Hadoop的依赖项泄漏到应用程序的类路径中。
支持机会容器和分布式计划。
引入了ExecutionType的概念,应用程序现在可以请求执行类型为Opportunistic的容器。即使调度时没有可用资源,也可以在NM上调度这种类型的容器以执行。在这种情况下,这些容器将在NM处排队,等待资源可用以启动它。机会容器的优先级比默认的“ 保证”容器低,因此如果需要,可以抢占机会以为“保证”容器腾出空间。这将提高群集利用率。
默认情况下,机会容器由中央RM分配,但是还添加了支持,以允许由实现为AMRMProtocol拦截器的分布式调度程序分配机会容器。
|
2.

HDFS主要有以下几个部分组成:
一.Client:切分文件;访问HDFS;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。
二.NameNode:Master节点,在hadoop1.X中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。对于大型的集群来讲,Hadoop1.x存在两个最大的缺陷:
三.1)对于大型的集群,namenode的内存成为瓶颈,namenode的扩展性的问题;
2)namenode的单点故障问题。
针对以上的两个缺陷,Hadoop2.x以后分别对这两个问题进行了解决。
对于缺陷1)提出了Federation namenode来解决,该方案主要是通过多个namenode来实现多个命名空间来实现namenode的横向扩张。从而减轻单个namenode内存问题。
针对缺陷2),hadoop2.X提出了实现两个namenode实现热备HA的方案来解决。其中一个是处于standby状态,一个处于active状态。
DataNode:Slave节点,存储实际的数据,汇报存储信息给NameNode。
四.Secondary NameNode:辅助NameNode,分担其工作量;定期合并fsimage和edits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。
b. YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager(RM)和若干个针对应用程序的ApplicationMaster(AM)。这里的应用程序是指传统的MapReduce作业或作业的DAG(有向无环图)。
该框架是hadoop2.x以后对hadoop1.x之前JobTracker和TaskTracker模型的优化,而产生出来的,将JobTracker的资源分配和作业调度及监督分开。该框架主要有ResourceManager,Applicationmatser,nodemanager。其主要工作过程如下:
ResourceManager主要负责所有的应用程序的资源分配,
ApplicationMaster主要负责每个作业的任务调度,也就是说每一个作业对应一个ApplicationMaster。
Nodemanager是接收Resourcemanager 和ApplicationMaster的命令来实现资源的分配执行体
3.
①projects
②projects list
③hadoop
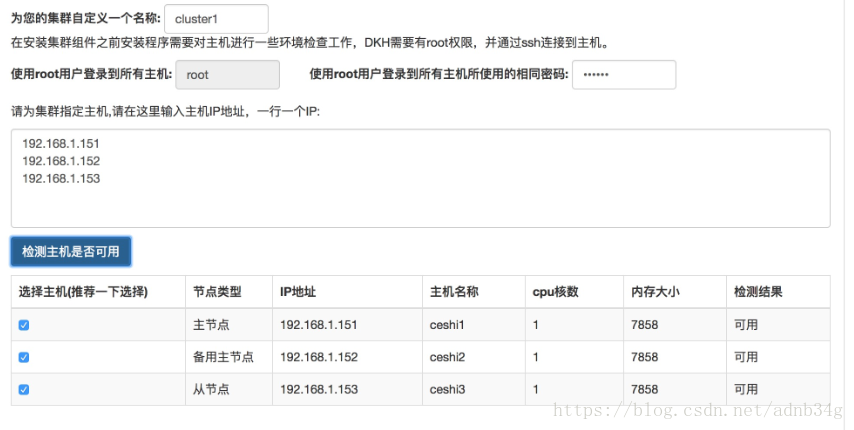
集群指定主机
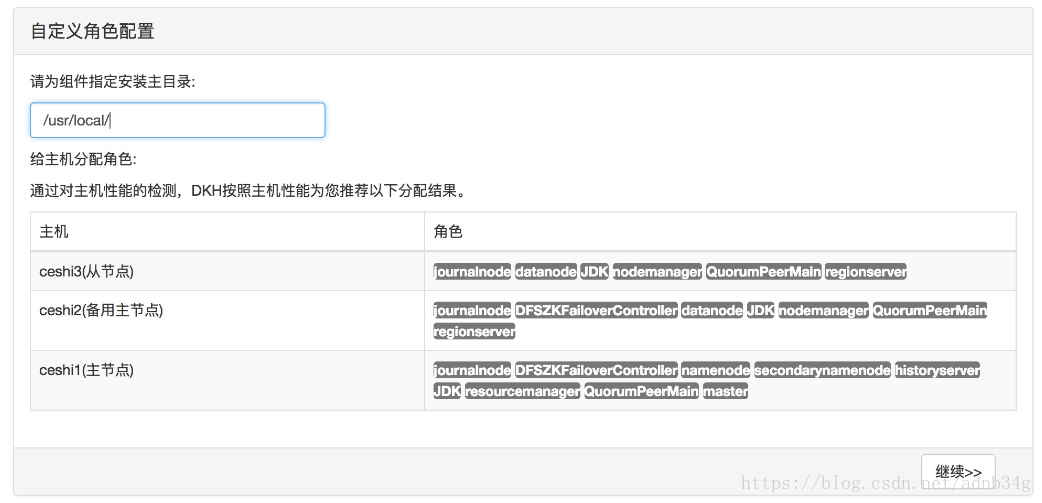
、集群安装(DKM各组件安装):这里有3种安装方式 “基本安装”,“完整安装”,“自定义安装”选择自定义

可以查看各机器分配的角色
开始安装组件:我以“基本安装”方式来进行示例,其他方式类同,选择“下一步”会出现如下图的进度条。

点击登录,进入到集群监控界面,进入到集群监控界面就表示安装成功了

选择HTTP中的任意三个
验证完整性
4.
华为——FusionInsight HD(简称FI),FI是基于hadoop2.72版开发的,坚持分层,解耦,开放的原则,得益于高可靠性,在全国各地政府、运营商、金融系统有较多案例。
FI的特性为高可靠性,系统可靠性,数据可靠性,所有组件无单点故障,所有管理节点HA(high 可用),软硬件健康状态监控,跨数据中心容灾,支持硬盘热拔插,强大的组织支撑能力,服务到位,半年做一次全面巡检,它的安全性高,系统安全,认证安全,数据安全,具有可视化集群管理,易运维,能够一键式组件安装部署,有.NTP(时钟)自动配置,还有自动配置主机映射关系,能够资源分布监控和自定义监控阈值,对于日志级别动态调整并且针对元数据向导式备份管理,还能够多租户管理(资源分配,只针对计算和存储资源)和多组件UI间单点登陆。


