视频超分之BasicVSR-阅读笔记
1.介绍
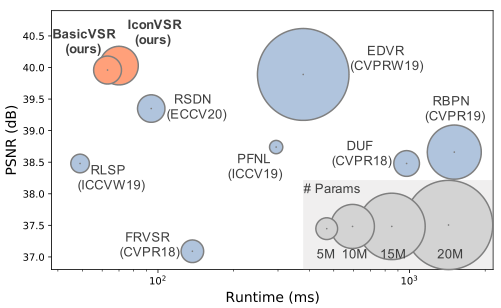
对于视频超分提出了很多方法,EDVR中采用了多尺度可变形对齐模块和多个注意层进行对齐和定位并且从不同的帧聚合特征,在RBPN中,多个投影模块用于顺序聚合多个帧中的特征。这样的设计是有效的,但不可避免地增加了运行时和模型的复杂性。此外,与SISR不同,VSR方法的潜在复杂和不同设计在实施和扩展现有方法方面造成了困难,妨碍了再现性和公平比较。我们首先根据功能将流行的VSR方法分解为子模块,大多数现有方法包含四个相互关联的组件,即传播、对齐、聚合和上采样。在上述四个组件中,传播和对齐组件的选择可能会导致性能和效率的大幅波动。我们的实验建议使用双向传播方案来最大化信息收集,并使用基于光流的方法来估计两个相邻帧之间的对应关系,以便进行特征对齐。通过使用聚合(即特征串联)和上采样(即像素洗牌)的常用设计简化这些传播和对齐组件,BasicVSR在性能和效率方面都优于现有的最新技术。
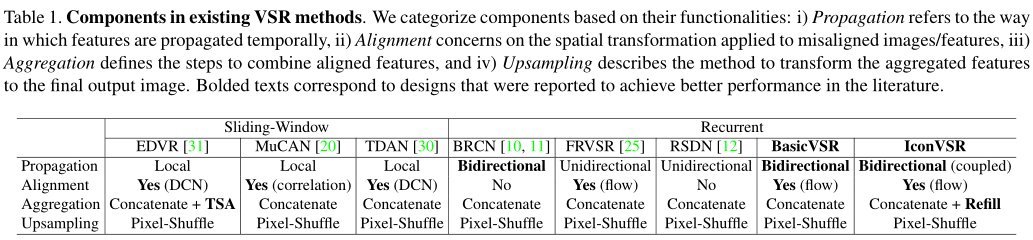
通过使用BasicVSR作为基础,我们提出了ICONVSR,它包括两个新的扩展以改进聚集和传播分量。第一个扩展名为information refill。该机制利用附加模块从稀疏选择的帧(关键帧)中提取特征,然后将特征插入到主网络中进行特征细化。第二个扩展是耦合传播方案,它促进了前向和后向传播分支之间的信息交换。这两个模块不仅减少了传播过程中由于遮挡和图像边界造成的误差累积,而且允许传播以序列形式访问完整信息,以生成高质量的特征。通过这两种新设计,IconVSR超过了BasicVSR,峰值信噪比提高了。
2.相关工作
现有的VSR方法主要可分为两个框架——滑动窗口和循环。滑动窗口框架中的早期方法预测低分辨率(LR)帧之间的光流,并为对齐执行空间扭曲。后来的方法求助于更复杂的隐式对齐方法。例如,TDAN采用可变形卷积(DCN)在特征级别对齐不同的帧。EDVR进一步以多尺度方式使用DCN,以实现更精确的对齐。DUF利用动态上采样过滤器隐式处理运动。有些方法采用循环框架。RSDN提出了一种结构块和隐藏状态自适应模块,以增强对外观变化和错误累积的鲁棒性。RRN在具有标识跳过连接的层之间采用残差映射,以确保流畅的信息流,并长期保存纹理信息。IconVSR中的信息重新填充机制让人想起基于区间的处理概念。这些方法将视频帧划分为以关键帧和非关键帧为特征的独立间隔。然后关键帧和非关键帧通过不同的管道进行处理。IconVSR通过传播分支将间隔连接起来进行一次推进。通过这种设计,长期信息可以在相互关联的时间间隔内传播,从而进一步提高效率。
3方法
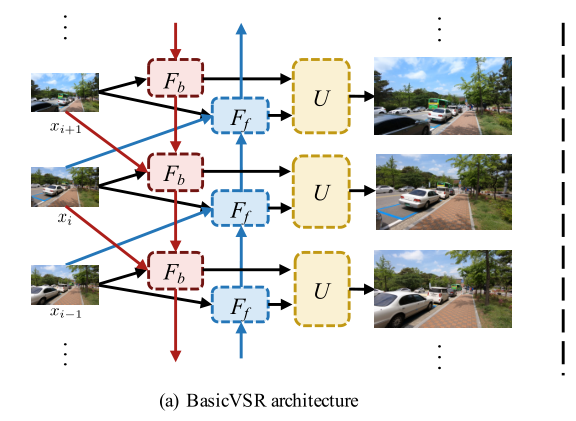
为了发现有助于VSR方法分析和开发的通用框架,我们将研究局限于通常采用的元素,如光流和残差块。BasicVSR的概述如图所示。
3.1传播
传播是VSR中最有影响力的组成部分之一。它指定如何利用视频序列中的信息。现有的传播方案可分为三大类: 局部传播、单向传播、双向传播。
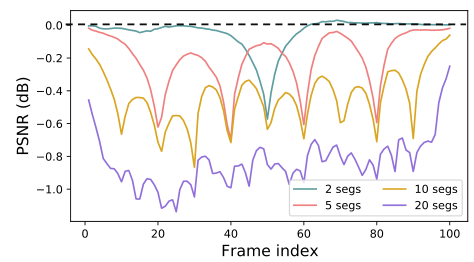
局部传播:该窗口方法将局部窗口内的LR图像作为输入,并利用局部信息进行恢复。可访问的信息被限制在本地。远程帧的省略不可避免地限制了滑动窗口方法的潜力。我们从一个全局感受野(在时间维度)开始,然后逐渐减少感受野。我们将测试序列分成K个片段,并使用我们的BasicVSR独立地恢复每个片段。图中描绘了与情况K=1(全局传播)的PSNR差。首先,当节段数减少时,PSNR的差异减小(即性能更好)。这表明,远距离帧中的信息有利于恢复,不应忽视。在每段的两端,峰值信噪比的差异最大,这表明有必要采用长序列来积累长期信息。
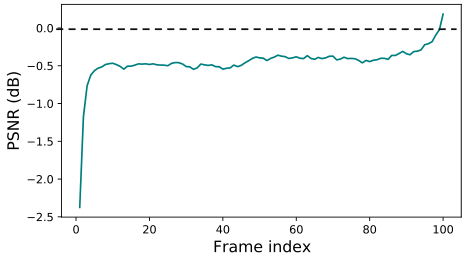
单向传播:信息从第一帧顺序传播到最后一帧,不同帧接收的信息是不平衡的。第一帧除了自身之外不接收来自视频序列的信息,而最后一帧接收来自整个序列的信息。因此,早期帧的结果可能不太理想,将BasicVSR(使用双向传播)与其单向变体(具有可比的网络复杂度)进行了比较。我们可以看到,在早期时间,单向模型获得的峰值信噪比(PSNR)明显低于双向传播,并且随着帧数的增加,更多信息被聚集,差异逐渐减小。此外,在仅使用部分信息的情况下,观察到一致的性能下降0.5 dB。这些观察揭示了单向传播的次优性。通过从序列的最后一帧传回信息,可以提高输出质量。
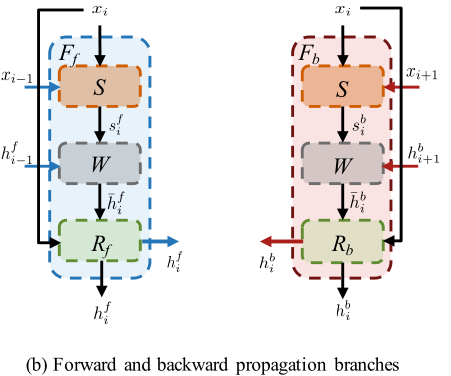
双向传播:上述两个问题可以通过双向传播同时解决,其中特征在时间上独立地向前和向后传播。BasicVSR采用了一种典型的双向传播方案。给定LR图像xi和邻帧xi-1和xi+1,以及来着邻帧相应的特征传播,定义为hfi-1和hbi+1,Fb和Ff分别表示反向和正向传播分支:
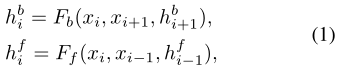
3.2对齐
空间对齐在VSR中起着重要作用,因为它负责对齐高度相关但没有对齐图像/用于后续聚合的功能。主流作品可分为三类:无对齐、图像对齐和特征对齐。进行实验来分析每一个类别,并验证我们对特征对齐的选择。
无对齐:现有的递归方法通常不会在传播期间执行对齐。不一致的特征/图像阻碍聚合,最终导致性能不达标。这种次优性可以通过我们的实验反映出来,我们移除了BasicVSR中的空间对齐模块。在这种情况下,我们直接连接不对齐的特征进行恢复。如果没有适当的对齐,传播的特征就不会与输入图像在空间上对齐。因此,像卷积这样的局部操作具有相对较小的感受野,无法有效地聚合来自相应位置的信息。且psnr下降的很多。
图像对齐:早期的工作通过计算光流并在恢复之前扭曲图像来执行对齐。将空间对齐从图像级移动到特征级会产生显著的改善。我们比较了BasicVSR变体上的图像扭曲和特征扭曲。由于光流估计不准确,扭曲图像不可避免地受到模糊和不正确的影响。细节的丢失最终导致产出下降。当采用图像对齐时,观察到0.17 dB的下降。这一观察证实了将空间对齐转移到特征级别的必要性。
特征对齐:移除图像对齐的较差性能促使我们求助于特征对齐。BasicVSR采用光流进行空间对齐,我们没有像以前的作品那样扭曲图像,而是对特征进行扭曲以获得更好的性能。然后将对齐的特征传递给多个残差块进行细化:
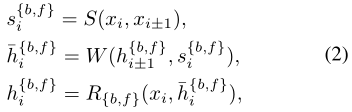
S和W分别表示流估计和空间扭曲模块,R{b,f}表示残差块的堆栈。
3.3聚合和上采样
BasicVSR采用基本组件进行聚合和上采样。具体地说,给定中间特征h{b,f}i,使用由多个卷积和pixelshuffle组成的上采样模块来生成输出HR图像,U为上采样模块

总结:上述分析推动了BasicVSR的设计选择。对于传播,BasicVSR选择了双向传播,重点是长期和全局传播。对于对齐,BasicVSR采用了一种简单的基于流的对齐,但在功能级别进行。对于聚合和上采样,选择流行的特征串联和像素混洗就足够了。尽管BasicVSR是一种简单而简洁的方法,但它在恢复质量和效率方面都取得了很好的效果。BasicVSR也具有高度的通用性,因为它可以方便地容纳额外的组件,以处理更具挑战性的场景。
3.4从BasicVSR到IconVSR
IconVSR引入了两个新组件——信息填充机制和耦合传播,以减轻传播过程中的错误积累,并促进信息聚合。
Information-Refill:在遮挡区域和图像边界上的不准确对齐是一个突出的挑战,可能会导致错误累积,尤其是如果我们在我们的框架中采用长期传播。为了缓解这些错误特征带来的不良影响,我们提出了一种用于特征细化的信息填充机制。 另一个特征提取器用于从输入帧(关键帧)的子集及其各自的邻居中提取深度特征。然后通过卷积将提取的特征与对齐的特征h_i(等式2)融合:
其中E和C分别对应于特征提取器和卷积。Ikey表示选定关键帧的索引集。然后,细化后的特征被传递给残差块,以进一步细化。特征提取和特征融合仅应用于稀疏选择的关键帧。信息重新填充机制带来的计算负担微不足道。
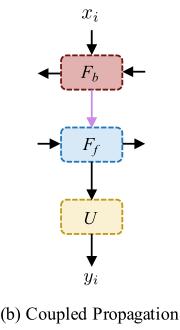
Coupled Propagation:在双向设置中,特征通常在两个相反的方向上独立传播。在这种设计中,每个传播分支中的特征都是基于之前帧或未来帧的部分信息来计算的。为了利用序列中的信息,我们提出了一种耦合传播方案,其中传播模块相互连接,在耦合传播中,将反向传播的特征hbi作为正向传播模块中的输入(等式1,3),通过耦合传播,前向传播分支接收来自过去和未来帧的信息,从而产生更高质量的特征,从而获得更好的输出。更重要的是,由于耦合传播只需要改变分支连接,因此可以在不引入计算开销的情况下获得性能增益。
4.实验
数据集设置:REDS和Vimeo-90K。对于REDS,使用REDS-4作为测试集。我们还将REDS-val4定义为我们的验证集。剩下的用于训练。我们使用Vid4、UDM10和Vimeo-90K-T以及Vimeo-90K作为测试集。我们使用双三次(BI)和模糊下采样(BD)两种退化方法,对我们的模型进行了4倍下采样测试。 我们分别使用经过预训练的SPyNet和EDVR-M4作为流量估计模块和特征提取器。我们采用Adam优化器和余弦退火方案。特征抽取器和流量估计器的初始学习率设置为1×10-4和2.5×10-5,其他设置为2*10-4。总迭代次数为300K,在前5000次迭代中,特征抽取器和流估计器的权重是固定的。批量大小为8,输入LR帧的补丁大小为64×64。我们使用Charbonnier的loss。
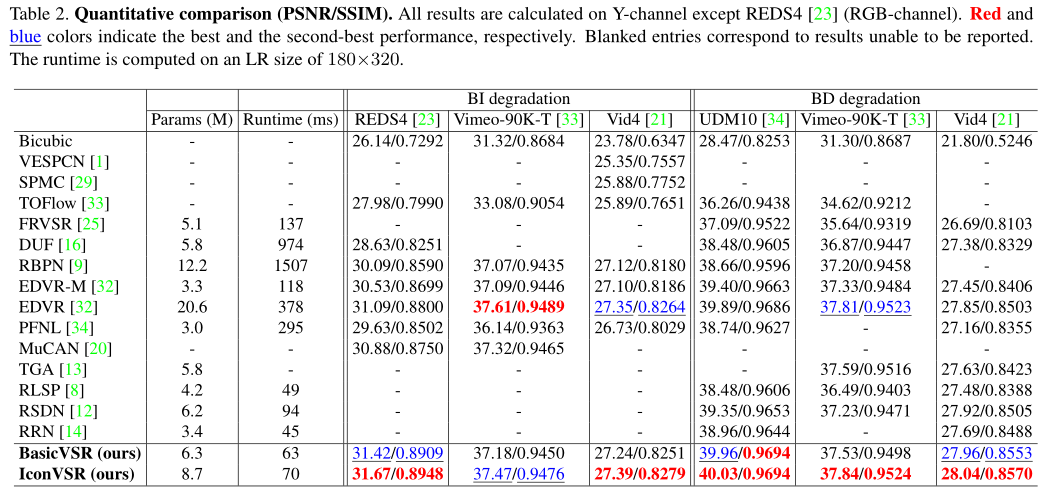
各个数据上表现:
5.消融研究
5.1从BasicVSR到IconVSR
Information-Refill:我们定性地可视化信息填充前后的特征,以深入了解其机制。填充前扭曲特征中的边界像素由于不存在通信而变为零。丢失的信息不可避免地会恶化特征质量,导致输出质量下降。 通过我们的信息补充机制,附加功能可用于在功能对齐不良的区域“补充”丢失的信息。然后,检索到的信息可用于后续的特征细化和传播。

耦合传播:为了消除耦合传播方案,我们禁用了信息填充机制,并将IconVSR与BasicVSR进行了比较。在图中,黄色框表示在先前帧中被遮挡的区域,并且BasicVSR中的前向传播分支无法接收该区域的信息。红色框表示序列的所有帧中都存在一个区域,因此可以在后面的帧中找到该区域的大量“快照”。通过耦合传播,可以更有效地利用反向传播的特征,从而重建更多细节和更精细的边缘。


5.2 Tradeoff in IconVSR
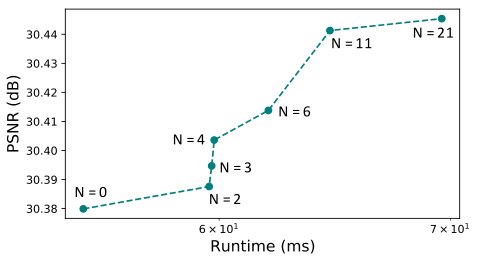
虽然IconVSR使用固定的关键帧间隔进行训练,但可以减少关键帧的数量以加快推理。PSNR使用不同数量的关键帧。我们发现PSNR与关键帧的数量正相关,验证了信息填充机制的贡献。在没有关键帧的极端情况下,IconVSR退化为循环网络。尽管如此,它仍然在REDS-val4上实现了30.38 dB的峰值信噪比,比BasicVSR高0.21 dB。这证明了我们的耦合传播方案的有效性,它可以在不引入额外计算开销的情况下使用。
6.结论
这项工作致力于寻找通用和有效的VSR基线,以便于VSR方法的分析和扩展。通过对现有元素的分解和分析,我们提出了BasicVSR,这是一种简单而有效的网络,其性能优于现有的技术水平,具有很高的效率。我们在BasicVSR的基础上,提出了IconVSR和两个新组件,以进一步提高性能。BasicVSR和IconVSR可以作为未来工作的强大基线,架构设计的发现可能会扩展到其他低级视觉任务,如视频去模糊、去噪和着色。
附录
结构:都采用SPyNet作为流量估计器。我们在每个传播分支中使用30个残差块。特性通道设置为64。在IconVSR中,我们采用EDVRM作为额外的特征提取器,因为它在效率和质量之间保持了良好的平衡。表总结了这些组件的复杂性。BasicVSR和IconVSR共享相同的流量估计器和主网络。主网络是一个轻量级网络,仅由490万个参数组成。流量估计器和特征提取器与主网络一起进行微调。在我们所有的实验中,每五帧被选为关键帧。请注意,特征提取程序仅应用于关键帧。因此,它带来的计算负担是微不足道的。

实验设置:当在REDS上训练时,我们使用15帧序列作为输入,并计算15幅输出图像的损失。在Vimeo-90K上训练时, 我们通过翻转原始图像来临时增加输入序列来临时增加序列以允许更长的传播时间。 换句话说,我们用14帧的序列进行训练。在推理过程中,我们将整个视频序列作为输入。
损失函数:我们使用Charbonnier loss,因为它能更好地处理异常值,并比传统的l2损失更好,zi表示基本真值HR帧,N表示像素数。
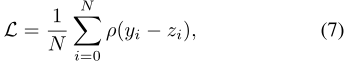
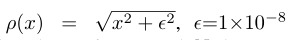
退化:我们使用两种降阶方法——双三次(BI)和模糊降采样(BD)对模型进行4倍降采样训练和测试。对于BI使用MATLAB函数imresize进行下采样。对于BD使用σ=1.6的高斯滤波器模糊gt,然后每四个像素进行一次子采样。
总结:BasicVSR是视频超分非常好的一个baseline,使用双向传播以及光流对齐,简单,效果好,可以考虑在该模型上进行创新。
论文链接:https://arxiv.org/pdf/2012.02181.pdf
代码链接:https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/basicvsr/README.md



