

词向量
转载:https://www.cnblogs.com/MartinLwx/p/10005520.html#4209708
为什么需要词向量?
众所周知,不管是机器学习还是深度学习本质上都是对数字的数字,Word Embedding(词嵌入)做的事情就是将单词映射到向量空间里,并用向量来表示
update 2019-5-2
> 从信息论的角度来看,就是引入了新的信息,所以能做更多的事情
> 还有TF-IDF词向量的词频+一定的权重值进行统计描述,缺点是单纯考虑词频,而忽略了词之间的位置信息和相互关系。
end
一个简单的对比
- One-hot Vector
对应的词所在的位置设为1,其他为0;
例如:King, Queen, Man and Woman这句里面Queen对应的向量就是[0,1,0,0][0,1,0,0]
不足:难以发现词之间的关系,以及难以捕捉句法(结构)和语义(意思)之间的关系
- Word2Vec
基本思想是把每个词表征为KK维的实数向量(每个实数都对应着一个特征,可以是和其他单词之间的联系),将相似的单词分组映射到向量空间的不同部分。也就是Word2Vec能在没有人为干涉下学习到单词之间的关系。
举个最经典的例子:
king- man + woman = queen
实际上的处理是:从king提取了maleness的含义,加上了woman具有的femaleness的意思,最后答案就是queen.
借助表格来理解就是:
| animal | pet | |
|---|---|---|
| dog | -0.4 | 0.02 |
| lion | 0.2 | 0.35 |
比如,animal那一列表示的就是左边的词与animal这个概念的相关性
两个重要模型
-
原理:拥有差不多上下文的两个单词的意思往往是相近的
-
Continuous Bag-of-Words(CBOW)
-
功能:通过上下文预测当前词出现的概率
-
BOW的思想:v(“abc”)=1/3(v(“a”)+v(“b”)+v(“c”))v(“abc”)=1/3(v(“a”)+v(“b”)+v(“c”))
-
原理分析
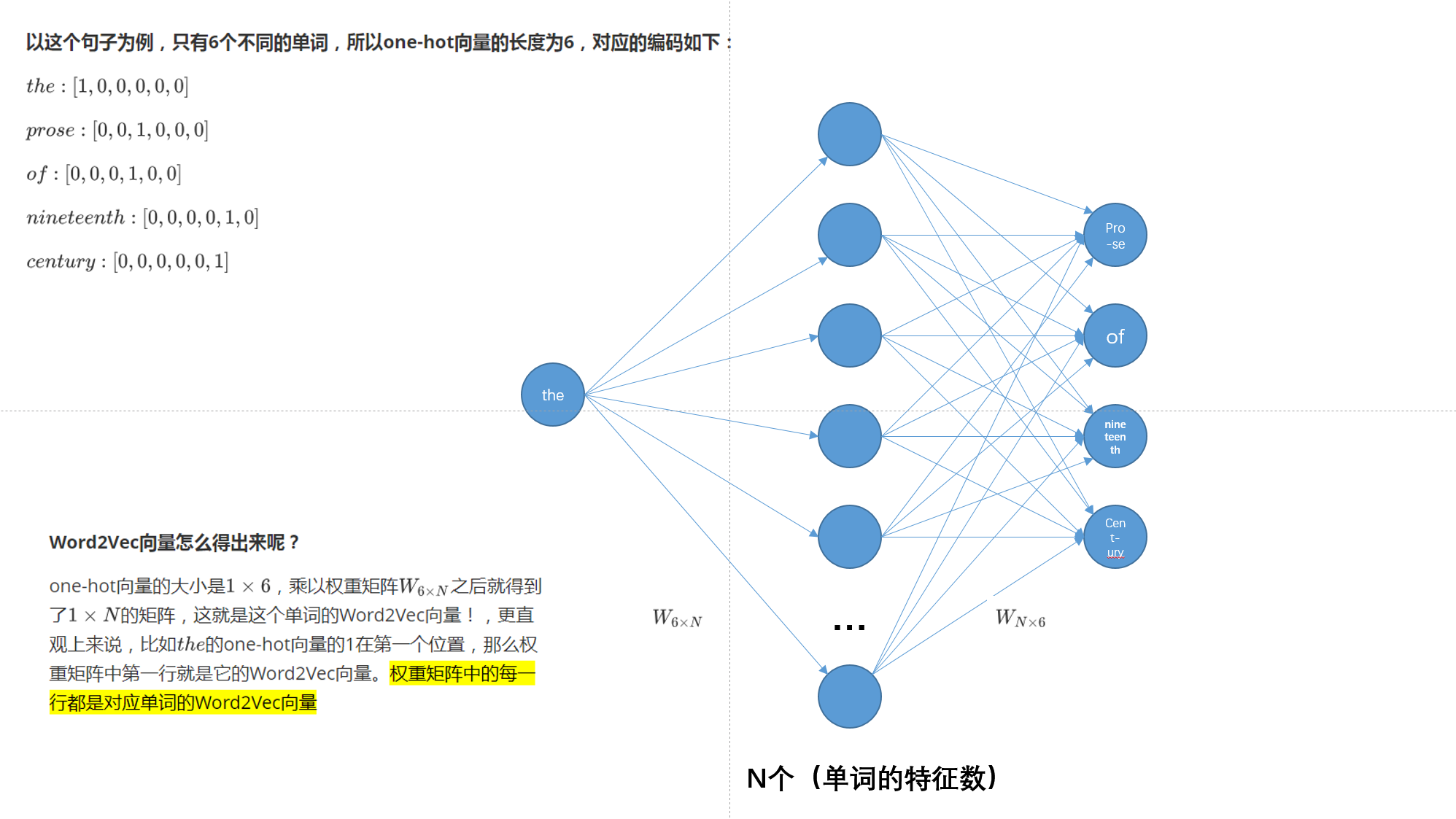
假设文本如下:“the florid prose of the nineteenth century.”
想象有个滑动窗口,中间的词是关键词,两边为相等长度(m,是超参数)的文本来帮助分析。文本的长度为7,就得到了7个one-hot向量,作为神经网络的输入向量,训练目标是:最大化在给定前后文本7情况下输出正确关键词的概率,比如给定("prose","of","nineteenth","century")的情况下,要最大化输出"the"的概率,用公式表示就是P("the"|("prose","of","nineteenth","century"))P("the"|("prose","of","nineteenth","century"))
-
特性
- hidden layer只是将权重求和,传递到下一层,是线性的
-
-
Skip-gram
- 功能:根据当前词预测上下文
- 原理分析
- 和CBOW相反,则我们要求的概率就变为P(Context(w)|w)P(Context(w)|w)
- 以上面的句子为例,数据集的构成,(input,output),(input,output)就是(the,prose),(the,of),(the,nineteenth),(the,century)(the,prose),(the,of),(the,nineteenth),(the,century)
- 损失函数
- 如果假设当前词为ww,那么可以写成P(wt+j|wt)(−m<=j<=m,j≠0)P(wt+j|wt)(−m<=j<=m,j≠0),每个词都会有一个概率,训练的目标就是最大化这些概率的乘积
- 也就是:L(θ)=∏(−m≤j≤m,j≠0)P(wt+j|wt;θ)L(θ)=∏(−m≤j≤m,j≠0)P(wt+j|wt;θ),表示准确度,要最大化
- 在概率中也经常有:J(θ)=−1TlogL(θ)=−1T∑Tt=1∑log(P(wt+j|wt;θ))J(θ)=−1TlogL(θ)=−1T∑t=1T∑log(P(wt+j|wt;θ)),加个负号就改成最小
- 概率示意P(o|c)=exp(uTovc)∑vw=1exp(uTwvc)P(o|c)=exp(uoTvc)∑w=1vexp(uwTvc)
- vcvc:当cc为中心词时用vv
- ucuc:当cc在ContextContext里时用uu
- 优点
- 在数据集比较大的时候结果更准确
-
不足
- 词的顺序不重要,并没有考虑到中文的语法
- 一词多义:比如tie的意思有很多个,要如何聚类,可以分出tie-1,tie-2等



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】