
Spark IDEA 调试(反编译)
1)以WordCount为例,具体代码如下:
1 import org.apache.spark.SparkConf 2 import org.apache.spark.SparkContext; 3 import org.apache.spark.SparkContext._ 4 /** 5 * Created by hfz on 2016/4/21. 6 */ 7 object test2 { 8 def main (args: Array[String]){ 9 var conf=new SparkConf().setAppName("WordCount").setMaster("local"); 10 var sc=new SparkContext(conf); 11 var rdd=sc.textFile("data/README.md"); 12 rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_); 13 rdd.collect(); 14 15 16 } 17 18 19 }
如果我们希望深入到sc.textFile()内部搞清楚都做了什么操作,如果是Java的话,我们直接CTRL+B,IDEA就自动把jar包中的字节码反编译为Java源码,并且,我们可以直接下个断点调试程序,但是对于Scala,IDEA的反编译效果并不是很好,如下图所示:
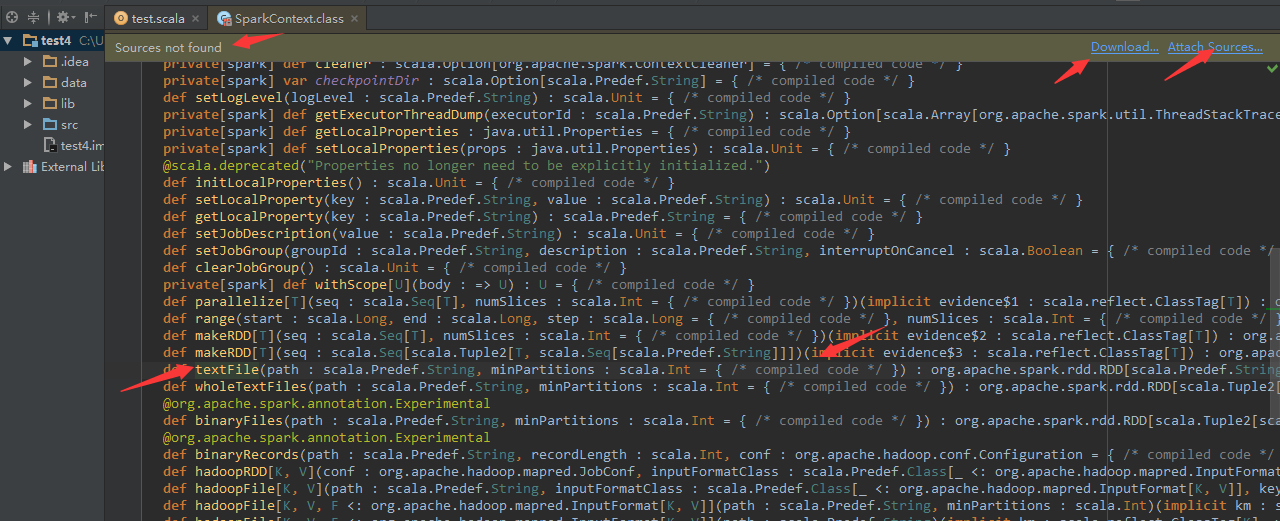
2)提示“Source not found”,我们在看textFile()方法,只可以看到方法的参数列表,方法体的内容却看不到,只能看到“compiled code”也就是“编译后的代码”。解决方法如下:
a.下载Spark1.4源码
b.然后点击右上角的“Attach Source”,添加源码,如下所示:
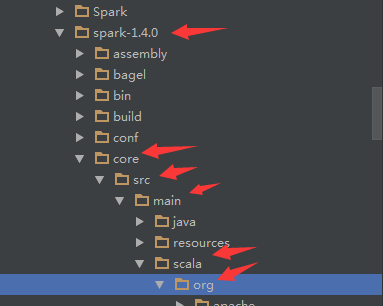
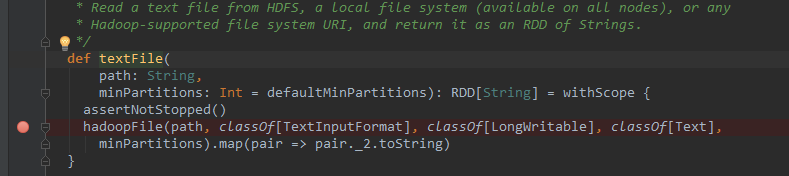
添加路径是“spark1.4.0/core/src/main/scala/org”,然后点击OK确定。“Attching”完成之后,我们就可以看到textFile()的方法体了,并且可以像之前调试hadoop一样,在这个方法下断点,运行程序的时候,会在这里命中断点,如下所示(这里只是加了个断点,没有调试):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号