
使用MultipleInputs和MultipleOutputs
还是计算矩阵的乘积,待计算的表达式如下:
S=F*[B+mu(u+s+b+d)]
其中,矩阵B、u、s、d分别存放在名称对应的SequenceFile文件中。
1)我们想分别读取这些文件(放在不同的文件夹中)然后计算与矩阵F的乘积,这就需要使用MultipleInputs类,那么就需要修改main()函数中对作业的配置,首先我们回顾一下之前未使用MultipleInputs的时候,对job中的map()阶段都需要进行哪些配置,示例如下:
job.setInputFormatClass(SequenceFileInputFormat.class); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(IntWritable.class); job.setMapOutputValueClass(DoubleArrayWritable.class);
FileInputFormat.setInputPaths(job, new Path(uri));
在配置job的时候对map任务的设置有五点,分别是:输入格式、所使用的mapper类、map输出key的类型、map输出value的类型以及输入路径。
然后,使用MultipleInputs时,对map的配置内容如下:
1 MultipleInputs.addInputPath(job, new Path(uri + "/b100"), SequenceFileInputFormat.class, MyMapper.class); 2 MultipleInputs.addInputPath(job, new Path(uri + "/u100"), SequenceFileInputFormat.class, MyMapper.class); 3 MultipleInputs.addInputPath(job, new Path(uri + "/s100"), SequenceFileInputFormat.class, MyMapper.class); 4 MultipleInputs.addInputPath(job, new Path(uri + "/d100"), SequenceFileInputFormat.class, MyMapper.class); 5 job.setMapOutputKeyClass(Text.class); 6 job.setMapOutputValueClass(DoubleArrayWritable.class);
首先使用addInputpath()将文件的输入路径、文件输入格式、所使用的mapper类添加到job中,所以接下来我们只需要再配置map的输出key和value的类型就可以了。
2)以上就是完成了使用MultipleInputs对map任务的配置,但是当我们使用MultipleInputs时,获得文件名的方法与以前的方法不同,所以需要将map()方法中获得文件名的代码修改为如下代码(http://blog.csdn.net/cuilanbo/article/details/25722489):
1 InputSplit split=context.getInputSplit(); 2 //String fileName=((FileSplit)inputSplit).getPath().getName(); 3 Class<? extends InputSplit> splitClass = split.getClass(); 4 5 FileSplit fileSplit = null; 6 if (splitClass.equals(FileSplit.class)) { 7 fileSplit = (FileSplit) split; 8 } else if (splitClass.getName().equals( 9 "org.apache.hadoop.mapreduce.lib.input.TaggedInputSplit")) { 10 // begin reflection hackery... 11 try { 12 Method getInputSplitMethod = splitClass 13 .getDeclaredMethod("getInputSplit"); 14 getInputSplitMethod.setAccessible(true); 15 fileSplit = (FileSplit) getInputSplitMethod.invoke(split); 16 } catch (Exception e) { 17 // wrap and re-throw error 18 throw new IOException(e); 19 } 20 // end reflection hackery 21 } 22 String fileName=fileSplit.getPath().getName();
以上就完成了map的多路径输入,不过如果我们想要将这多个文件的计算结果也输出到不同的文件这怎么办?那就使用MultipleOutputs。
3)使用MultipleOutputs之前,我们首先考虑之前我们是怎么配置reduce任务的,示例如下:
1 job.setOutputFormatClass(SequenceFileOutputFormat.class); 2 job.setReducerClass(MyReducer.class); 3 job.setOutputKeyClass(IntWritable.class); 4 job.setOutputValueClass(DoubleArrayWritable.class); 5 FileOutputFormat.setOutputPath(job,new Path(outUri));
同样的,在reduce任务的时候设置也是五点,分别是:输入格式、所使用的reduce类、renduce输出key的类型、reduce输出value的类型以及输出路径。然后,使用MultipleInputs是对reducer的配置如下:
1 MultipleOutputs.addNamedOutput(job, "Sb100", SequenceFileOutputFormat.class, IntWritable.class, DoubleArrayWritable.class); 2 MultipleOutputs.addNamedOutput(job,"Su100",SequenceFileOutputFormat.class,IntWritable.class,DoubleArrayWritable.class); 3 MultipleOutputs.addNamedOutput(job,"Ss100",SequenceFileOutputFormat.class,IntWritable.class,DoubleArrayWritable.class); 4 MultipleOutputs.addNamedOutput(job, "Sd100", SequenceFileOutputFormat.class, IntWritable.class, DoubleArrayWritable.class); 5 job.setReducerClass(MyReducer.class); 6 FileOutputFormat.setOutputPath(job,new Path(outUri));
使用MultipleOutputs的addNamedOutput()方法将输出文件名、输出文件格式、输出key类型、输出value类型配置到job中。然后我们再配置所使用的reduce类、输出路径。
4)使用MultipleOutputs时,在reduce()方法中写入文件使用的不再是context.write(),而是使用MultipleOutputs类的write()方法。所以需要修改redcue()的实现以及setup()的实现,修改后如下:
a.setup()方法
1 public void setup(Context context){ 2 mos=new MultipleOutputs(context); 3 int leftMatrixColumnNum=context.getConfiguration().getInt("leftMatrixColumnNum",100); 4 sum=new DoubleWritable[leftMatrixColumnNum]; 5 for (int i=0;i<leftMatrixColumnNum;++i){ 6 sum[i]=new DoubleWritable(0.0); 7 } 8 } 9 10
b.reduce()方法
1 public void reduce(Text key,Iterable<DoubleArrayWritable>value,Context context) throws IOException, InterruptedException { 2 int valueLength=0; 3 for(DoubleArrayWritable doubleValue:value){ 4 obValue=doubleValue.toArray(); 5 valueLength=Array.getLength(obValue); 6 for (int i=0;i<valueLength;++i){ 7 sum[i]=new DoubleWritable(Double.parseDouble(Array.get(obValue,i).toString())+sum[i].get()); 8 } 9 } 10 valueArrayWritable=new DoubleArrayWritable(); 11 valueArrayWritable.set(sum); 12 String[] xx=key.toString(). split(","); 13 IntWritable intKey=new IntWritable(Integer.parseInt(xx[0])); 14 if (key.toString().endsWith("b100")){ 15 mos.write("Sb100",intKey,valueArrayWritable); 16 } 17 else if (key.toString().endsWith("u100")) { 18 mos.write("Su100",intKey,valueArrayWritable); 19 } 20 else if (key.toString().endsWith("s100")) { 21 mos.write("Ss100",intKey,valueArrayWritable); 22 } 23 else if (key.toString().endsWith("d100")) { 24 mos.write("Sd100",intKey,valueArrayWritable); 25 } 26 for (int i=0;i<sum.length;++i){ 27 sum[i].set(0.0); 28 } 29 30 } 31 }
mos.write("Sb100",key,value)中的文件名必须与使用addNamedOutput()方法配置job时使用的文件名相同,另外文件名中不能包含"-"、“_”字符。
5)在一个Job中同时使用MultipleInputs和MultipleOutputs的完整代码如下:
1 /** 2 * Created with IntelliJ IDEA. 3 * User: hadoop 4 * Date: 16-3-9 5 * Time: 下午12:47 6 * To change this template use File | Settings | File Templates. 7 */ 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import java.io.IOException; 11 import java.lang.reflect.Array; 12 import java.lang.reflect.Method; 13 import java.net.URI; 14 15 import org.apache.hadoop.fs.Path; 16 import org.apache.hadoop.io.*; 17 import org.apache.hadoop.mapreduce.InputSplit; 18 import org.apache.hadoop.mapreduce.Job; 19 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 20 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 21 import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat; 22 import org.apache.hadoop.mapreduce.lib.input.MultipleInputs; 23 import org.apache.hadoop.mapreduce.lib.output.NullOutputFormat; 24 import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat; 25 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 26 import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs; 27 import org.apache.hadoop.mapreduce.Reducer; 28 import org.apache.hadoop.mapreduce.Mapper; 29 import org.apache.hadoop.filecache.DistributedCache; 30 import org.apache.hadoop.util.ReflectionUtils; 31 32 public class MutiDoubleInputMatrixProduct { 33 public static class MyMapper extends Mapper<IntWritable,DoubleArrayWritable,Text,DoubleArrayWritable>{ 34 public DoubleArrayWritable map_value=new DoubleArrayWritable(); 35 public double[][] leftMatrix=null;/******************************************/ 36 public Object obValue=null; 37 public DoubleWritable[] arraySum=null; 38 public double sum=0; 39 public void setup(Context context) throws IOException { 40 Configuration conf=context.getConfiguration(); 41 leftMatrix=new double[conf.getInt("leftMatrixRowNum",10)][conf.getInt("leftMatrixColumnNum",10)]; 42 System.out.println("map setup() start!"); 43 //URI[] cacheFiles=DistributedCache.getCacheFiles(context.getConfiguration()); 44 Path[] cacheFiles=DistributedCache.getLocalCacheFiles(conf); 45 String localCacheFile="file://"+cacheFiles[0].toString(); 46 //URI[] cacheFiles=DistributedCache.getCacheFiles(conf); 47 //DistributedCache. 48 System.out.println("local path is:"+cacheFiles[0].toString()); 49 // URI[] cacheFiles=DistributedCache.getCacheFiles(context.getConfiguration()); 50 FileSystem fs =FileSystem.get(URI.create(localCacheFile), conf); 51 SequenceFile.Reader reader=null; 52 reader=new SequenceFile.Reader(fs,new Path(localCacheFile),conf); 53 IntWritable key= (IntWritable)ReflectionUtils.newInstance(reader.getKeyClass(),conf); 54 DoubleArrayWritable value= (DoubleArrayWritable)ReflectionUtils.newInstance(reader.getValueClass(),conf); 55 int valueLength=0; 56 int rowIndex=0; 57 while (reader.next(key,value)){ 58 obValue=value.toArray(); 59 rowIndex=key.get(); 60 if(rowIndex<1){ 61 valueLength=Array.getLength(obValue); 62 } 63 leftMatrix[rowIndex]=new double[conf.getInt("leftMatrixColumnNum",10)]; 64 //this.leftMatrix=new double[valueLength][Integer.parseInt(context.getConfiguration().get("leftMatrixColumnNum"))]; 65 for (int i=0;i<valueLength;++i){ 66 leftMatrix[rowIndex][i]=Double.parseDouble(Array.get(obValue, i).toString()); 67 } 68 69 } 70 } 71 public void map(IntWritable key,DoubleArrayWritable value,Context context) throws IOException, InterruptedException { 72 obValue=value.toArray(); 73 InputSplit split=context.getInputSplit(); 74 //String fileName=((FileSplit)inputSplit).getPath().getName(); 75 Class<? extends InputSplit> splitClass = split.getClass(); 76 77 FileSplit fileSplit = null; 78 if (splitClass.equals(FileSplit.class)) { 79 fileSplit = (FileSplit) split; 80 } else if (splitClass.getName().equals( 81 "org.apache.hadoop.mapreduce.lib.input.TaggedInputSplit")) { 82 // begin reflection hackery... 83 try { 84 Method getInputSplitMethod = splitClass 85 .getDeclaredMethod("getInputSplit"); 86 getInputSplitMethod.setAccessible(true); 87 fileSplit = (FileSplit) getInputSplitMethod.invoke(split); 88 } catch (Exception e) { 89 // wrap and re-throw error 90 throw new IOException(e); 91 } 92 // end reflection hackery 93 } 94 String fileName=fileSplit.getPath().getName(); 95 96 97 98 99 100 if (fileName.startsWith("FB")) { 101 context.write(new Text(String.valueOf(key.get())+","+fileName),value); 102 } 103 else{ 104 arraySum=new DoubleWritable[this.leftMatrix.length]; 105 for (int i=0;i<this.leftMatrix.length;++i){ 106 sum=0; 107 for (int j=0;j<this.leftMatrix[0].length;++j){ 108 sum+= this.leftMatrix[i][j]*Double.parseDouble(Array.get(obValue,j).toString())*(double)(context.getConfiguration().getFloat("u",1f)); 109 } 110 arraySum[i]=new DoubleWritable(sum); 111 //arraySum[i].set(sum); 112 } 113 map_value.set(arraySum); 114 context.write(new Text(String.valueOf(key.get())+","+fileName),map_value); 115 } 116 } 117 } 118 public static class MyReducer extends Reducer<Text,DoubleArrayWritable,IntWritable,DoubleArrayWritable>{ 119 public DoubleWritable[] sum=null; 120 public Object obValue=null; 121 public DoubleArrayWritable valueArrayWritable=null; 122 private MultipleOutputs mos=null; 123 124 public void setup(Context context){ 125 mos=new MultipleOutputs(context); 126 int leftMatrixColumnNum=context.getConfiguration().getInt("leftMatrixColumnNum",100); 127 sum=new DoubleWritable[leftMatrixColumnNum]; 128 for (int i=0;i<leftMatrixColumnNum;++i){ 129 sum[i]=new DoubleWritable(0.0); 130 } 131 } 132 133 public void reduce(Text key,Iterable<DoubleArrayWritable>value,Context context) throws IOException, InterruptedException { 134 int valueLength=0; 135 for(DoubleArrayWritable doubleValue:value){ 136 obValue=doubleValue.toArray(); 137 valueLength=Array.getLength(obValue); 138 for (int i=0;i<valueLength;++i){ 139 sum[i]=new DoubleWritable(Double.parseDouble(Array.get(obValue,i).toString())+sum[i].get()); 140 } 141 } 142 valueArrayWritable=new DoubleArrayWritable(); 143 valueArrayWritable.set(sum); 144 String[] xx=key.toString(). split(","); 145 IntWritable intKey=new IntWritable(Integer.parseInt(xx[0])); 146 if (key.toString().endsWith("b100")){ 147 mos.write("Sb100",intKey,valueArrayWritable); 148 } 149 else if (key.toString().endsWith("u100")) { 150 mos.write("Su100",intKey,valueArrayWritable); 151 } 152 else if (key.toString().endsWith("s100")) { 153 mos.write("Ss100",intKey,valueArrayWritable); 154 } 155 else if (key.toString().endsWith("d100")) { 156 mos.write("Sd100",intKey,valueArrayWritable); 157 } 158 for (int i=0;i<sum.length;++i){ 159 sum[i].set(0.0); 160 } 161 162 } 163 } 164 165 public static void main(String[]args) throws IOException, ClassNotFoundException, InterruptedException { 166 String uri="data/input"; 167 String outUri="sOutput"; 168 String cachePath="data/F100"; 169 HDFSOperator.deleteDir(outUri); 170 Configuration conf=new Configuration(); 171 DistributedCache.addCacheFile(URI.create(cachePath),conf);//添加分布式缓存 172 /**************************************************/ 173 //FileSystem fs=FileSystem.get(URI.create(uri),conf); 174 //fs.delete(new Path(outUri),true); 175 /*********************************************************/ 176 conf.setInt("leftMatrixColumnNum",100); 177 conf.setInt("leftMatrixRowNum",100); 178 conf.setFloat("u",0.5f); 179 // conf.set("mapred.jar","MutiDoubleInputMatrixProduct.jar"); 180 Job job=new Job(conf,"MultiMatrix2"); 181 job.setJarByClass(MutiDoubleInputMatrixProduct.class); 182 //job.setOutputFormatClass(NullOutputFormat.class); 183 job.setReducerClass(MyReducer.class); 184 job.setMapOutputKeyClass(Text.class); 185 job.setMapOutputValueClass(DoubleArrayWritable.class); 186 MultipleInputs.addInputPath(job, new Path(uri + "/b100"), SequenceFileInputFormat.class, MyMapper.class); 187 MultipleInputs.addInputPath(job, new Path(uri + "/u100"), SequenceFileInputFormat.class, MyMapper.class); 188 MultipleInputs.addInputPath(job, new Path(uri + "/s100"), SequenceFileInputFormat.class, MyMapper.class); 189 MultipleInputs.addInputPath(job, new Path(uri + "/d100"), SequenceFileInputFormat.class, MyMapper.class); 190 MultipleOutputs.addNamedOutput(job, "Sb100", SequenceFileOutputFormat.class, IntWritable.class, DoubleArrayWritable.class); 191 MultipleOutputs.addNamedOutput(job,"Su100",SequenceFileOutputFormat.class,IntWritable.class,DoubleArrayWritable.class); 192 MultipleOutputs.addNamedOutput(job,"Ss100",SequenceFileOutputFormat.class,IntWritable.class,DoubleArrayWritable.class); 193 MultipleOutputs.addNamedOutput(job, "Sd100", SequenceFileOutputFormat.class, IntWritable.class, DoubleArrayWritable.class); 194 FileOutputFormat.setOutputPath(job,new Path(outUri)); 195 System.exit(job.waitForCompletion(true)?0:1); 196 } 197 198 199 } 200 class DoubleArrayWritable extends ArrayWritable { 201 public DoubleArrayWritable(){ 202 super(DoubleWritable.class); 203 } 204 public String toString(){ 205 StringBuilder sb=new StringBuilder(); 206 for (Writable val:get()){ 207 DoubleWritable doubleWritable=(DoubleWritable)val; 208 sb.append(doubleWritable.get()); 209 sb.append(","); 210 } 211 sb.deleteCharAt(sb.length()-1); 212 return sb.toString(); 213 } 214 } 215 216 class HDFSOperator{ 217 public static boolean deleteDir(String dir)throws IOException{ 218 Configuration conf=new Configuration(); 219 FileSystem fs =FileSystem.get(conf); 220 boolean result=fs.delete(new Path(dir),true); 221 System.out.println("sOutput delete"); 222 fs.close(); 223 return result; 224 } 225 }
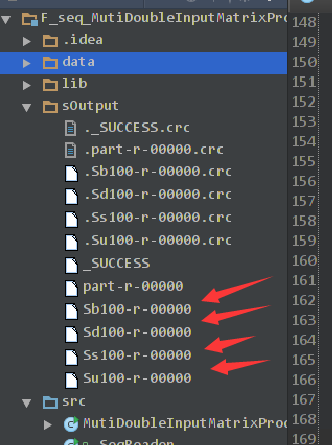
6)运行结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号