


由SequenceFile.Writer(key,value)谈toString()方法
之前有篇博客(http://www.cnblogs.com/lz3018/p/5243503.html)介绍以SequenceFile作为输入源进行矩阵乘法的过程,首先是将矩阵存储到SequenceFile文件中,然后使用hadoop命令:hadoop fs -text /10IntArray 查看此SequenceFile文件中内容的时候,显示如下:

而我们写SequenceFile文件的代码如下:
1 /** 2 * Created with IntelliJ IDEA. 3 * User: hadoop 4 * Date: 16-3-4 5 * Time: 上午10:36 6 * To change this template use File | Settings | File Templates. 7 */ 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import java.io.IOException; 12 import java.net.URI; 13 import org.apache.hadoop.io.IntWritable; 14 import org.apache.hadoop.io.SequenceFile; 15 import org.apache.hadoop.io.ArrayWritable; 16 public class SequenceFileWriterDemo { 17 public static void main(String[] args) throws IOException { 18 String uri="/home/hadoop/2016Test/SeqTest/10IntArray"; 19 Configuration conf=new Configuration(); 20 FileSystem fs=FileSystem.get(URI.create(uri),conf); 21 Path path=new Path(uri); 22 IntWritable key=new IntWritable(); 23 IntArrayWritable value=new IntArrayWritable();//定义IntArrayWritable类型的alue值。 24 value.set(new IntWritable[]{new IntWritable(1),new IntWritable(2),new IntWritable(3), 25 new IntWritable(4)}); 26 SequenceFile.Writer writer=null; 27 writer=SequenceFile.createWriter(fs,conf,path,key.getClass(),value.getClass()); 28 int i=0; 29 while(i<10){ 30 key.set(i++); 31 //value.set(intArray); 32 writer.append(key,value); 33 } 34 writer.close();//一定要加上这句,否则写入SequenceFile会失败,结果是一个空文件。 35 System.out.println("done!"); 36 } 37 } 38 class IntArrayWritable extends ArrayWritable { 39 public IntArrayWritable(){ 40 super(IntWritable.class); 41 } 42 }
当我们把[1,2,3,4]转化为IntArrayWritable类型的value之后,再调用writer.append(key,value)就把这个向量写入文件了。其实这就是将一个序列化的过程,将“活对象”持久化存储(因为一般对象只有在JVM运行的时候才能存在),对象的持久化存储可以在JVM停止之后仍然存在。序列化的过程存储的只是对象的“状态”,也就是对象的成员变量,所以类的成员方法以及静态变量是不存储的。
但是,当我们使用命令查看这个文件中的内容时,为什么内容看起来那么奇怪呢?
1)这要从今天遇到的一个问题开始说起。代码如下:
public class test{ public static void main(String[] args){ int[] intArray={1,2,3}; String s=intArray.toString(a);//将数组转化为字符串,然后输出,多么朴素的想法,但是,结果... System.out.println(s); } }
当System.out.println()检测到输入是一个对象而不是字符或者数字时就会调用这个对象的toString()方法进行输出。Object是所有类的父类,其有一个toString()方法,而整型数组(int [])并没有重写这个toString()方法,所以调用Object的方法,定义如下:
public String toString() { return getClass().getName() + "@" + Integer.toHexString(hashCode()); }
hashCode()的返回值是jdk根据对象地址算出来的可以唯一标识这个对象的int型数值。而Integer.toHexString(int i)就是将这个int的数值首先转化为16进制表示的无符号整形数,然后再将这个数转化为字符串,示例如下(http://www.yiibai.com/javalang/integer_tohexstring.html):
import java.lang.*; public class IntegerDemo { public static void main(String[] args) { int i = 170; System.out.println("Number = " + i); /* returns the string representation of the unsigned integer value represented by the argument in hexadecimal (base 16) */ System.out.println("Hex = " + Integer.toHexString(i)); } }
输出结果如下:
Number = 170
Hex = aa
至此,我们就明白了以下结果的含义:
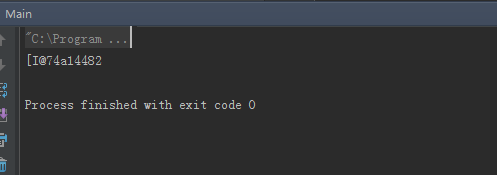
[I@74a14482
int[] intArray={1,2,3},"["应该是表示这个是说明对象数组类型,"I"表示是整型变量,然后就是"@",最后是74a14482就是对象的哈希值的16进制表示形式。原因我们已经搞清楚了,那么怎么才能使其输出正常呢(http://www.linuxidc.com/Linux/2014-12/110127.htm)?
2)使用Arrays.toStrings()将数组转化为字符串,代码如下:
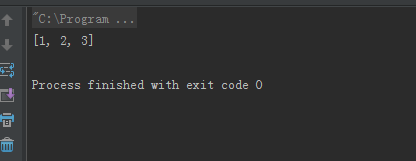
/** * Created by hfz on 2016/2/28. */ import java.util.Arrays; public class Main { public static void main(String[] args){ int[] a=new int[]{1,2,3}; String s= Arrays.toString(a); System.out.println(s); } }
Arrays.toString()上的实现如下:
public static String toString(int[] a) { if (a == null) return "null"; int iMax = a.length - 1; if (iMax == -1) return "[]"; StringBuilder b = new StringBuilder(); b.append('['); for (int i = 0; ; i++) { b.append(a[i]); if (i == iMax) return b.append(']').toString(); b.append(", "); } }
结果如下所示:
做个总结,使用system.out.print(var)输出变量var时,当检测到var是引用类型的话,也就是对象,就会自动调用其toString()方法,然后输出对象对应的字符串。当我们使用writer.append(key,value)时(写文件时应该也是会检测写入变量的类型),检测到value是对象,所以会调用其toString()方法,因为我们自定义的IntArrayWritable并没有覆盖父类Object的toString()方法,所以是调用了Object的toString()方法,
public String toString() { return getClass().getName() + "@" + Integer.toHexString(hashCode()); }
所以写入文件的value是“IntArrayWritable@5dcf0778”(数组类型会在类名称之前加“[”),后来我们使用命令查看文件内容时看到的自然就是:
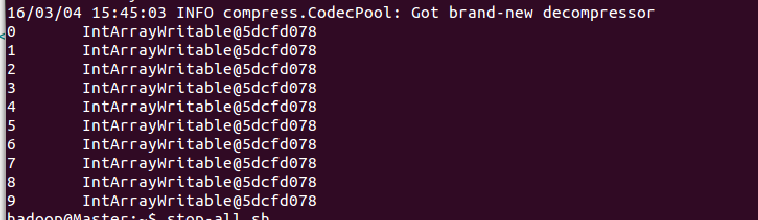
key可以正常显示?因为IntWritable重载了toString()方法呀,所以我们还需要在IntArrayWritable中增加一个toString()方法才可以正常显示。那么,怎么才能使IntArrayWritable也正常显示呢?只需要IntArrayWritable重载toString()方法就可以了。其最新定义如下:
1 class IntArrayWritable extends ArrayWritable { 2 public IntArrayWritable(){ 3 super(IntWritable.class); 4 } 5 public String toString(){ 6 StringBuilder sb=new StringBuilder(); 7 for (Writable val:get()){ 8 IntWritable intWritable=(IntWritable)val; 9 sb.append(intWritable.get()); 10 sb.append(","); 11 } 12 return sb.toString(); 13 }
有一点需要注意,就是ArrayWritable的get方法以Writable[]返回值values,而我们需要的是IntWriable型的值,如果采用下列方法:
IntWritable[] intArray=(IntWritable[])get();
不过会报错,“Writable[] can't cast to IntWritable[]”。
正确的方法是采用以下的方法(http://qiuqiang1985.iteye.com/blog/1622065):
for (Writable val:get()){ IntWritable intWritable=(IntWritable)val; }
然后看到的就如我们希望的那样。

