


mapred和mapreduce
总体上看,Hadoop MapReduce分为两部分:一部分是org.apache.hadoop.mapred.*,这里面主要包含旧的API接口以及MapReduce各个服务(JobTracker以及TaskTracker)的实现;另一部分是org.apache.hadoop.mapreduce.*,主要内容涉及新版本的API接口以及一些新特性(比如MapReduce安全)。hadoop版本1.x的包一般是mapreduce * hadoop版本0.x的包一般是mapred。
虽然hadoop 1.2.1源码的src文件夹下只有mapred文件夹而没有mapreduce,其实mapred文件夹是同时包含了mapred的旧API和mapreduce的新API的。如图所示:
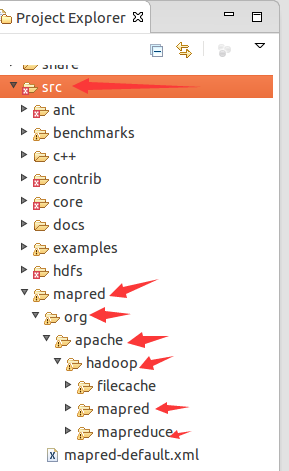
可以在这里阅读源码。
1. 首先第一条,也是小菜今天碰到这些问题的原因,新旧API不兼容。所以,以前用旧API写的hadoop程序,如果旧API不可用之后需要重写,也就是上面我的程序需要重写,如果旧API不能用的话,如果真不能用,这个有点儿小遗憾!
2. 新的API倾向于使用抽象类,而不是接口,使用抽象类更容易扩展。例如,我们可以向一个抽象类中添加一个方法(用默认的实现)而不用修改类之前的实现方法。因此,在新的API中,Mapper和Reducer是抽象类。
3. 新的API广泛使用context object(上下文对象),并允许用户代码与MapReduce系统进行通信。例如,在新的API中,MapContext基本上充当着JobConf的OutputCollector和Reporter的角色。
4. 新的API同时支持"推"和"拉"式的迭代。在这两个新老API中,键/值记录对被推mapper中,但除此之外,新的API允许把记录从map()方法中拉出,这也适用于reducer。分批处理记录是应用"拉"式的一个例子。
5. 新的API统一了配置。旧的API有一个特殊的JobConf对象用于作业配置,这是一个对于Hadoop通常的Configuration对象的扩展。在新的API中,这种区别没有了,所以作业配置通过Configuration来完成。作业控制的执行由Job类来负责,而不是JobClient,并且JobConf和JobClient在新的API中已经荡然无存。这就是上面提到的,为什么只有在mapred中才有Jobconf的原因。
6. 输出文件的命名也略有不同,map的输出命名为part-m-nnnnn,而reduce的输出命名为part-r-nnnnn,这里nnnnn指的是从0开始的部分编号。
这样了解了二者的区别就可以通过程序的引用包来判别新旧API编写的程序了。小菜建议最好用新的API编写hadoop程序,以防旧的API被抛弃!!!

新版API仍然会使用org.apache.hadoop.mapred中的一些类(可以这样理解,与org.apache.hadoop.mapred中的类相比,如果org.apache.hadoop.mapreduce中没有实现相关类,就说明新版API仍然使用这些类,如果实现了的,就会覆盖掉org.apache.hadoop.mapred中的相关类)。
以MapTask说明:
MapTask负责调度执行map操作,其中有个方法run(),在这个方法的内部,有段代码如下:
boolean useNewApi = job.getUseNewMapper();//是否使用新版API,true表示使用了新版API initialize(job, getJobID(), reporter, useNewApi); // check if it is a cleanupJobTask if (jobCleanup) { runJobCleanupTask(umbilical, reporter); return; } if (jobSetup) { runJobSetupTask(umbilical, reporter); return; } if (taskCleanup) { runTaskCleanupTask(umbilical, reporter); return; } if (useNewApi) { //使用了新版API就调用新方法 runNewMapper(job, splitMetaInfo, umbilical, reporter); } else { runOldMapper(job, splitMetaInfo, umbilical, reporter); }
参考:

