


输入格式--InputFormat和InputSplit
1)InputFormat的类图:
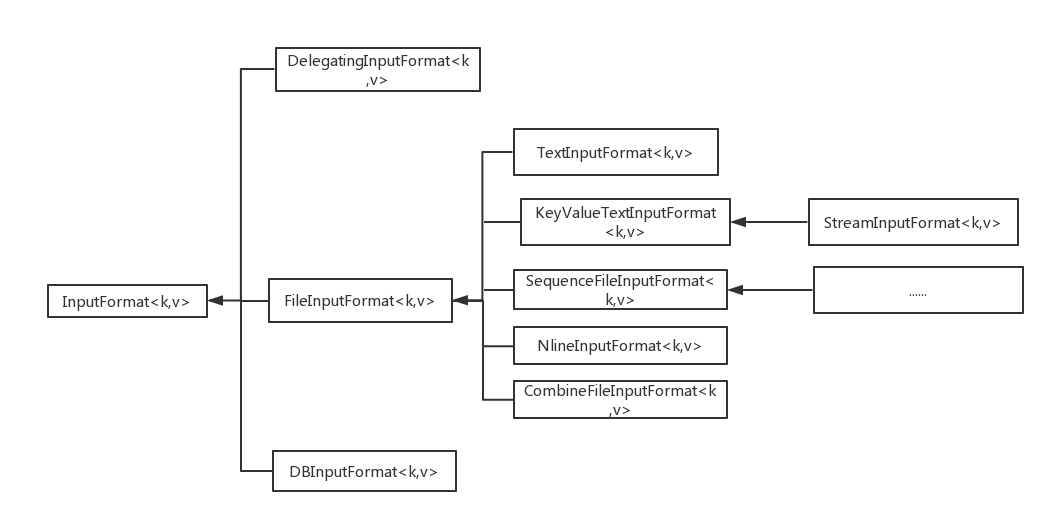
InputFormat 直接子类有三个:DBInputFormat、DelegatingInputFormat和FileInputFormat,分别表示输入文件的来源为从数据库、用于多个输入以及基于文件的输入。对于FileInputFormat,即从文件输入的输入方式,又有五个继承子类:CombineFileInputFormat,KeyValueTextInput,NLineInoutFormat,SequenceFileInputFormat,TextInputFormat。
2)InputSplit的类图
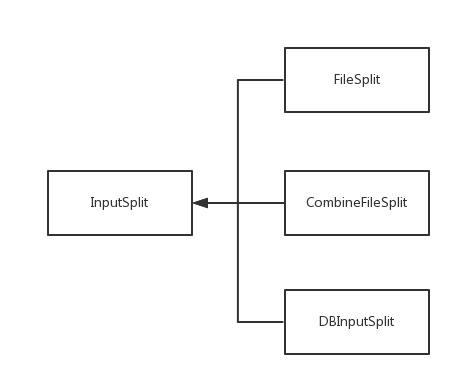
输入分片InputSplit 类有三个子类继承:FileSplit (文件输入分片),CombineFileSplit(多文件输入分片)以及DBInputSplit(数据块输入分片)。
3)InputFormat:
InputFormat有三个作用:
a.验证作业数据的输入形式和格式(要与MR程序中使用的格式相同,比如是TextInputFormat还是DBInputFormat)
b.将输入的数据切分为多个逻辑上的InputSplit,其中每一个InputSplit作为一个MApper的输入。
c.提供一个RecordReader,用于将InputSplit的内容转换为可以作为map输入的<k,v>键值对。
使用代码来指定MR作业数据的输入格式:
job.setInputFormatClass(TextInputFormat.class)
其实,InputFormat是一个抽象类,只是提供了两个抽象方法:
abstract List<InputSplit>getSplits(JobContext context);
abstract RecordReader<K,V> createRecordReader(InputSplit split,TaskAttemptContext context)
只提供两个抽象方法是有原因的,首先不同的格式的文件切片的方法不同(对应于getSplits),同一份文件可能希望读出不同形式的内容(对应createRecordReader)。
getSplits:
InputFormat的直接派生类需要实现此方法,例如FileInputFormat和DBInputFormat。另外,InputSplit的类型在选择了InputFormat的类型就已经确定了的,因为每个InputFormat的派生类都实现了getSplits,在此方法内部已经生成了对应的InputSplit。
createRecordReader:
FileInputFormat的派生类都实现了这个方法。
4)
InputSplit:
任何数据分块儿的实现都继承自抽象基类InputSplit,它位于org.apache.hadoop.mapreduce.InputSplit。此抽象类中有两个抽象方法:
abstract long getLength() abstract String[] getLocation()
getLength()返回该块儿的大小,单位是字节。getLocation()返回存储该数据块的数据节点的名称,例如:String[0]="Slave1",String[1]="Slave2".
这两个方法也是需要在InputSplit的派生类中实现的。
5)
InputSplit的大小:
一个数据分片的大小由以下三行代码确定:
goalSize=totalSize/(numSplits==0?1:numSplits)
//totalSize是输入数据文件的大小,numSplits是用户设置的map数量,就是按照用户自己
//的意愿,每个分片的大小应该是goalSize
minSize=Math.max(job.getLong("mapred.min.split.size",1),minSplitSize)
//hadoop1.2.1中mapred-default.xml文件中mapred.min.split.size=0,所以job.getLong("mapred.min.split.size",1)=0,而minSplitSize是InputSplit中的一个数据成员,在File//Split中值为1.所以minSize=1,其目的就是得到配置中的最小值。
splitSize=Math.max(minSize,Math.min(goalSize,blockSize))
//真正的分片大小就是取按照用户设置的map数量计算出的goalSize和块大小blockSize中最小值(这是为了是分片不会大于一个块大小,有利于本地化计算),并且又比minSize大的值。

