JDBC的复习
什么是JDBC
JDBC(Java DataBase Connectivity)就是Java数据库连接,说白了就是用Java语言来操作数据库。原来我们操作数据库是在控制台使用SQL语句来操作数据库,JDBC是用Java语言向数据库发送SQL语句。
JDBC原理
由SUN提供一套访问数据库的规范(就是一组接口),并提供连接数据库的协议标准,然后各个数据库厂商会遵循SUN的规范提供一套访问自己公司的数据库服务器的API出现。SUN提供的规范命名为JDBC,而各个厂商提供的,遵循了JDBC规范的,可以访问自己数据库的API被称之为驱动。
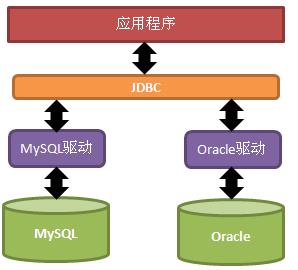
JDBC是接口,而JDBC驱动才是接口的实现,没有驱动无法完成数据库连接!每个数据库厂商都有自己的驱动,用来连接自己公司的数据库。
当然还有第三方公司专门为某一数据库提供驱动,这样的驱动往往不是开源免费的!
JDBC核心类(接口)介绍
JDBC中的核心类有:DriverManager、Connection、Statement,和ResultSet!
1.DriverManger(驱动管理器)的作用有两个:
- 注册驱动:这可以让JDBC知道要使用的是哪个驱动;
- 获取Connection:如果可以获取到Connection,那么说明已经与数据库连接上了。
2. Connection对象表示连接,与数据库的通讯都是通过这个对象展开的:
Connection最为重要的一个方法就是用来获取Statement对象;
3. Statement是用来向数据库发送SQL语句的,这样数据库就会执行发送过来的SQL语句:
- void executeUpdate(String sql):执行更新操作(insert、update、delete等);
- ResultSet executeQuery(String sql):执行查询操作,数据库在执行查询后会把查询结果,查询结果就是ResultSet;
4. ResultSet对象表示查询结果集,只有在执行查询操作后才会有结果集的产生。结果集是一个二维的表格,有行有列。操作结果集要学习移动ResultSet内部的“行光标”,以及获取当前行上的每一列上的数据:
- boolean next():使“行光标”移动到下一行,并返回移动后的行是否存在;
- XXX getXXX(int col):获取当前行指定列上的值,参数就是列数,列数从1开始,而不是0。
开始使用
mysql数据库的驱动jar包:mysql-connector-java-5.1.13-bin.jar;(注意:使用6.x的版本建议使用使用新的驱动名,6版本似乎与连接池不兼容)
这里先不使用连接池,接下来会专门写一篇连接池的笔记
初始化连接:
private Connection conn=null; public void initConnection()throws Exception{ Class.forName("com.mysql.jdbc.Driver"); conn=DriverManager.getConnection("jdbc:mysql://localhost:3306/数据库名","root","root"); }
关闭连接(其实ResultSet、Statement,以及Connection都需要关闭,我会在规范化代码的时候再说):
public void closeConnection()throws Exception{ conn.close(); }
在这里还需要介绍一个最常用的类:PreparedStatement
它是Statement接口的子接口;
强大之处:
- 防SQL攻击;
- 提高代码的可读性、可维护性;
- 提高效率!
如何得到PreparedStatement对象:
- 给出SQL语句!
- 调用Connection的PreparedStatement prepareStatement(String sql语句);
- 调用pstmt的setXxx()系列方法sql语句中的?(记得从1开始哦)赋值!
- 调用pstmt的executeUpdate()或executeQuery(),但它的方法都没有参数。
我们再说说结果集的概念:
结果集(ResultSet):通过查询语句返回的就是结果集。
结果集特性:
- 是否可滚动(是否可以移动游标)
- 是否敏感(数据库中数据改变,结果集是否改变)
- 是否可更新(是否允许通过改变结果集反向改变数据库,这一特性不推荐不常用)
默认结果集不滚动、不敏感、不可更新(但是Mysql数据库返回的结果集默认是可滚动的,要注意)
ResultSet表示结果集,它是一个二维的表格!ResultSet内部维护一个行光标(游标),ResultSet提供了一系列的方法来移动游标:
void beforeFirst()://把光标放到第一行的前面,这也是光标默认的位置; void afterLast()://把光标放到最后一行的后面; boolean first()://把光标放到第一行的位置上,返回值表示调控光标是否成功; boolean last()://把光标放到最后一行的位置上; boolean isBeforeFirst()://当前光标位置是否在第一行前面; boolean isAfterLast()://当前光标位置是否在最后一行的后面; boolean isFirst()://当前光标位置是否在第一行上; boolean isLast()://当前光标位置是否在最后一行上; boolean previous()://把光标向上挪一行; boolean next()://把光标向下挪一行; boolean relative(int row)://相对位移,当row为正数时,表示向下移动row行,为负数时表示向上移动row行; boolean absolute(int row)://绝对位移,把光标移动到指定的行上; int getRow()://返回当前光标所有行。
其中next()方法最为常用
批处理
批处理处理就是一次处理多条sql语句,不必要一句一句去发送sql语句,一次发送多条。
批处理只针对更新(增、删、改)语句,批处理没有查询什么事儿!
默认的批处理是关闭的,需要我们在配置连接的url中,配置参数(在上面我们还是将连接数据库的信息放在代码中,这种硬编码不灵活,接下来我们要使用properties文件来配置)
dbconfig.properties(等使用连接池的时候,这些信息就可以配置到连接池的配置文件中):
driverClassName=com.mysql.jdbc.Driver
url=jdbc\:mysql\://localhost\:3306\数据库名
username=root
password=root
这才是默认没有开启批处理的配置,接下来我们要加上这个参数
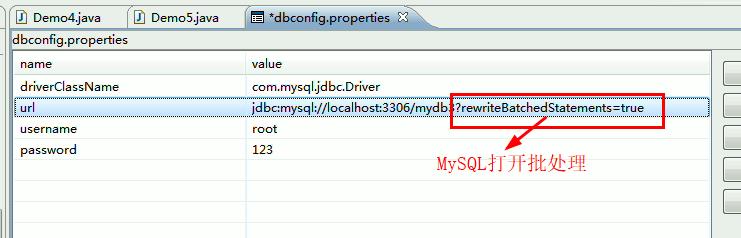
加上这个参数后,就可以在Dao层开始使用批处理了
可以多次调用Statement类的addBatch(String sql)方法,把需要执行的所有SQL语句添加到一个“批”中,然后调用Statement类的executeBatch()方法来执行当前“批”中的语句。
- void addBatch(String sql):添加一条语句到“批”中;
- int[] executeBatch():执行“批”中所有语句。返回值表示每条语句所影响的行数据;
- void clearBatch():清空“批”中的所有语句。
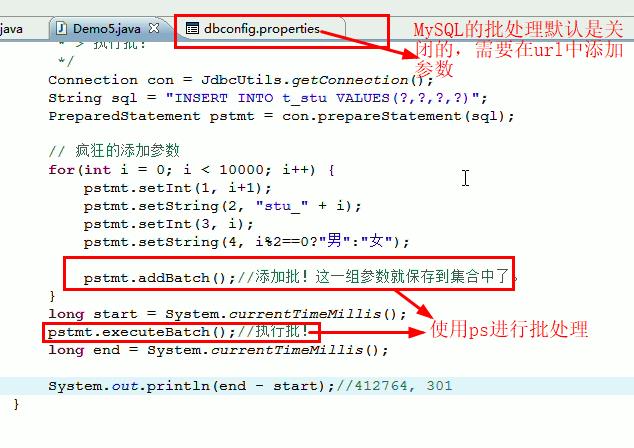
这个JdbcUtil类,是自己编写的,随后给出
con = JdbcUtils.getConnection(); String sql = "insert into stu values(?,?,?,?)"; pstmt = con.prepareStatement(sql); for(int i = 0; i < 10; i++) { pstmt.setString(1, "S_10" + i); pstmt.setString(2, "stu" + i); pstmt.setInt(3, 20 + i); pstmt.setString(4, i % 2 == 0 ? "male" : "female"); pstmt.addBatch(); } pstmt.executeBatch();
当执行了“批”之后,“批”中的SQL语句就会被清空!也就是说,连续两次调用executeBatch()相当于调用一次!因为第二次调用时,“批”中已经没有SQL语句了。
还可以在执行“批”之前,调用Statement的clearBatch()方法来清空“批”!
再附上一个较常用数据库的properties配置(这些配型也都可以配置到连接池的配置中):
#mysql #url=jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=utf8&useServerPrepStmts=true&cachePrepStmts=true&prepStmtCacheSize=50&prepStmtCacheSqlLimit=300 #driverClassName=com.mysql.jdbc.Driver #mssql #driverClassName=com.microsoft.jdbc.sqlserver.SQLServerDriver #url=jdbc:sqlserver://127.0.0.1:1433;DatabaseName=mydb #mssql jtds #driverClassName=net.sourceforge.jtds.jdbc.Driver #url=jdbc:jtds:sqlserver://127.0.0.1:1433;DatabaseName=mydb #orcale #driverClassName=oracle.jdbc.driver.OracleDriver #url=jdbc:oracle:thin:@localhost:1521:mydb #access #driverClassName=sun.jdbc.odbc.JdbcOdbcDriver #url=jdbc:odbc:driver={Microsoft Access Driver (*.mdb)};DBQ=mdb\\mydb.mdb
预处理
我们每向服务器发送一条sql语句,服务器需要做的的工作:
-
校验sql语句的语法!
-
编译:一个与函数相似的东西!
-
执行:调用函数
现在连接的数据库几乎没有不支持预处理的
每个pstmt都与一个sql模板绑定在一起,先把sql模板给数据库,数据库先进行校验,再进行编译。执行时只是把参数传递过去而已!
若二次执行时,就不用再次校验语法,也不用再次编译!直接执行!
时间类型
数据库类型与java中类型的对应关系:
数据库: java.sql.Date
Java: java.sql.Time
注意:
领域对象(domain/model)中的所有属性不能出现java.sql包下的东西!即不能使用java.sql.Date;
ResultSet#getDate()返回的是java.sql.Date()
PreparedStatement#setDate(int, Date),其中第二个参数也是java.sql.Date
java.sql包下给出三个与数据库相关的日期时间类型,分别是:
Date:表示日期,只有年月日,没有时分秒。会丢失时间;
Time:表示时间,只有时分秒,没有年月日。会丢失日期;
Timestamp:表示时间戳,有年月日时分秒,以及毫秒。
这三个类都是java.util.Date的子类。
时间类型相互转换
把数据库的三种时间类型赋给java.util.Date,基本不用转换,因为这是把子类对象给父类的引用,不需要转换。
java.sql.Date date = … java.util.Date d = date; java.sql.Time time = … java.util.Date d = time; java.sql.Timestamp timestamp = … java.util.Date d = timestamp;
当需要把java.util.Date转换成数据库的三种时间类型时,这就不能直接赋值了,这需要使用数据库三种时间类型的构造器。java.sql包下的Date、Time、TimeStamp三个类的构造器都需要一个long类型的参数,表示毫秒值。创建这三个类型的对象,只需要有毫秒值即可。我们知道java.util.Date有getTime()方法可以获取毫秒值,那么这个转换也就不是什么问题了。
java.utl.Date d = new java.util.Date(); java.sql.Date date = new java.sql.Date(d.getTime());//会丢失时分秒 Time time = new Time(d.getTime());//会丢失年月日 Timestamp timestamp = new Timestamp(d.getTime());
大数据
所谓大数据,就是大的字节数据,或大的字符数据。标准SQL中提供了如下类型来保存大数据类型 :
|
类型 |
长度 |
|
tinyblob |
28--1B(256B) |
|
blob |
216-1B(64K) |
|
mediumblob |
224-1B(16M) |
|
longblob |
232-1B(4G) |
|
tinyclob |
28--1B(256B) |
|
clob |
216-1B(64K) |
|
mediumclob |
224-1B(16M) |
|
longclob |
232-1B(4G) |
但是,在mysql中没有提供tinyclob、clob、mediumclob、longclob四种类型,而是使用如下四种类型来处理文本大数据:
|
类型 |
长度 |
|
tinytext |
28--1B(256B) |
|
text |
216-1B(64K) |
|
mediumtext |
224-1B(16M) |
|
longtext |
232-1B(4G) |
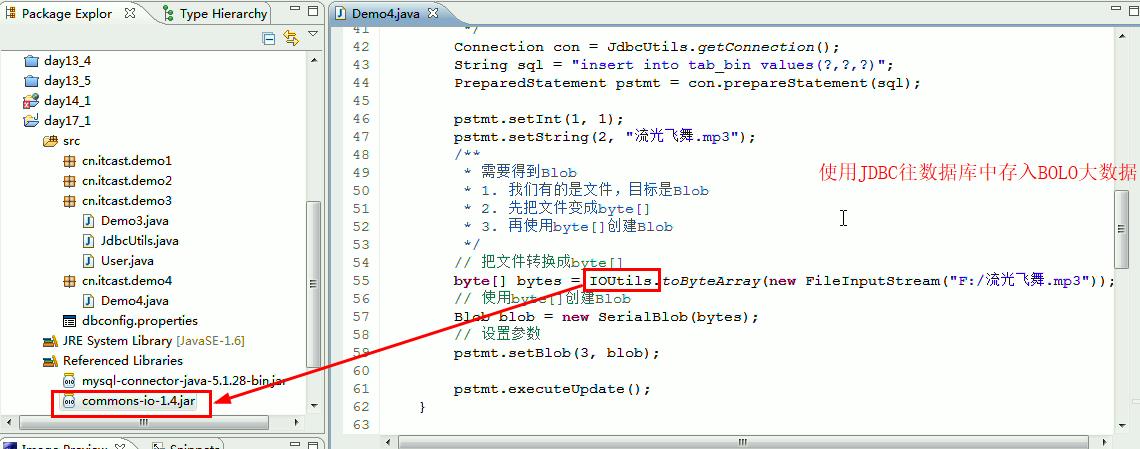
往数据库中添加大数据(二进制上传到数据库中,使用的是commons-iojar包中的IOUtil类,这个包还有一个常用的FileUtils文件操作类):
public void fun1() throws Exception { /* * 1. 得到Connection * 2. 给出sql模板,创建pstmt * 3. 设置sql模板中的参数 * 4. 调用pstmt的executeUpdate()执行 */ Connection con = JdbcUtils.getConnection(); String sql = "insert into tab_bin values(?,?,?)"; PreparedStatement pstmt = con.prepareStatement(sql); pstmt.setInt(1, 1); pstmt.setString(2, "a.mp3"); /** * 需要得到Blob * 1. 我们有的是文件,目标是Blob * 2. 先把文件变成byte[] * 3. 再使用byte[]创建Blob */ // 把文件转换成byte[] byte[] bytes = IOUtils.toByteArray(new FileInputStream("F:/a.mp3")); // 使用byte[]创建Blob Blob blob = new SerialBlob(bytes); // 设置参数 pstmt.setBlob(3, blob); pstmt.executeUpdate(); }
IOUtil是commons-iojar包中的类,需要导入这个jar
从数据库中读BLOB到硬盘:
/** * 从数据库读取mp3 * @throws SQLException */ @Test public void fun2() throws Exception { /* * 1. 创建Connection */ Connection con = JdbcUtils.getConnection(); /* * 2. 给出select语句模板,创建pstmt */ String sql = "select * from tab_bin"; PreparedStatement pstmt = con.prepareStatement(sql); /* * 3. pstmt执行查询,得到ResultSet */ ResultSet rs = pstmt.executeQuery(); /* * 4. 获取rs中名为data的列数据 */ if(rs.next()) { Blob blob = rs.getBlob("data"); /* * 把Blob变成硬盘上的文件! */ /* * 1. 通过Blob得到输入流对象 * 2. 自己创建输出流对象 * 3. 把输入流的数据写入到输出流中 */ InputStream in = blob.getBinaryStream(); OutputStream out = new FileOutputStream("c:/lgfw.mp3"); IOUtils.copy(in, out); } }
还需要注意的是:
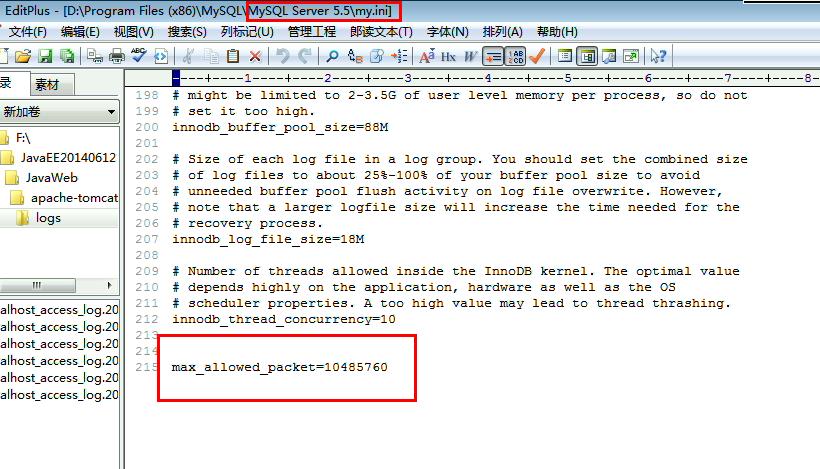
MySQL有默认的数据包大小,需要我们修改它,不然就会报这个异常:
com.mysql.jdbc.PacketTooBigException: Packet for query is too large (9802817 > 1048576). You can change this value on the server by setting the max_allowed_packet' variable.
在my.ini中设置,在[mysqld]下添加max_allowed_packet=大小(字节为单位),例如:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号