
GMP模型里为什么要有P?
关于GMP模型里为什么要有P,进一步推敲问题的背后,其实这个问题本质是想问:”为什么不是 G 和 M 直接绑定就完了,还要搞多一个 P 出来,那么麻烦,为的是什么,是要解决什么问题吗?
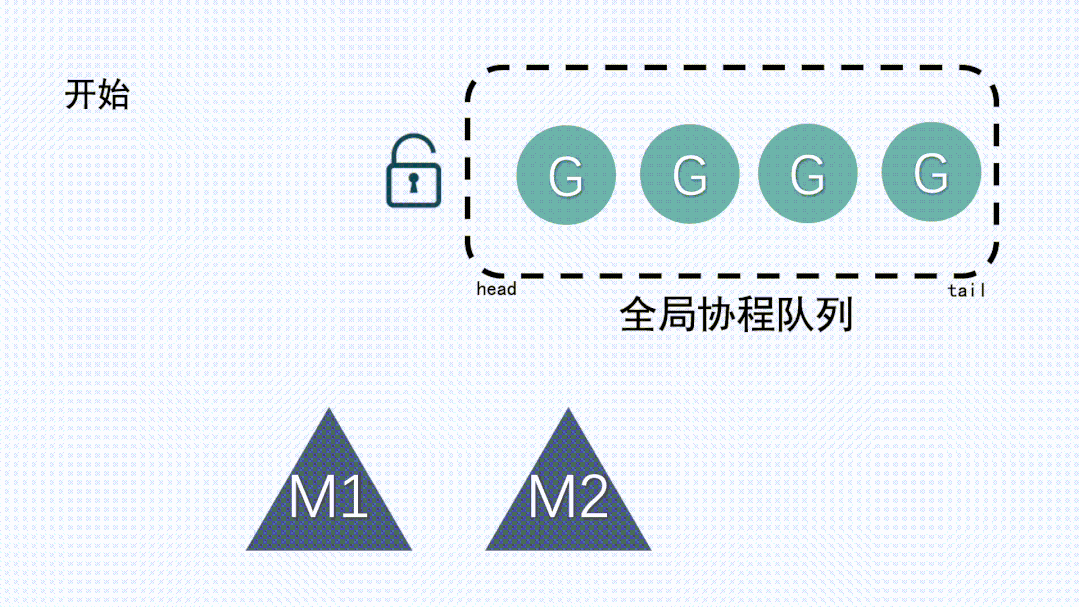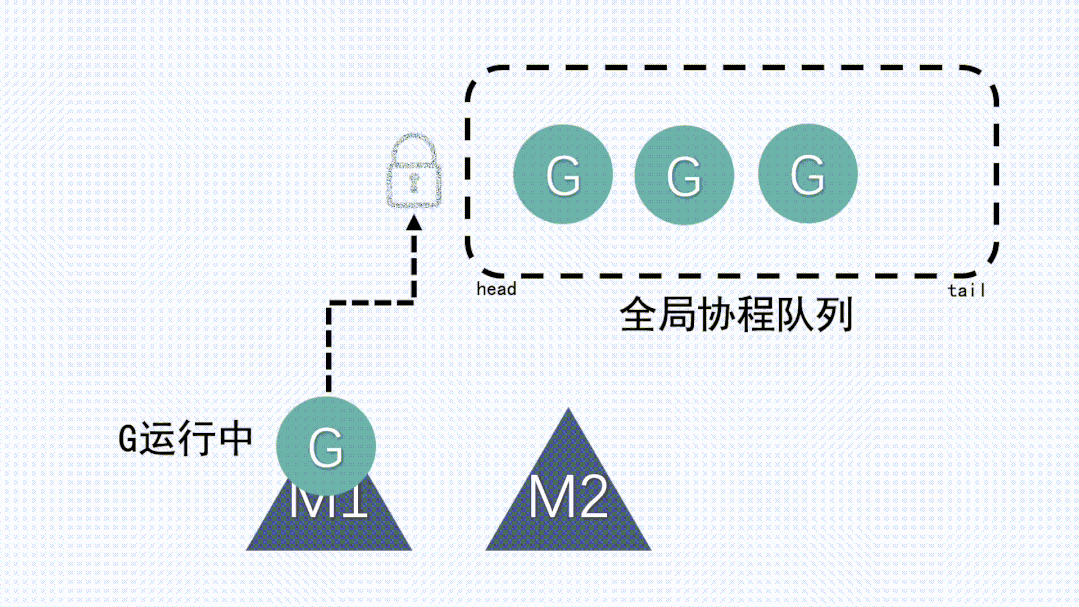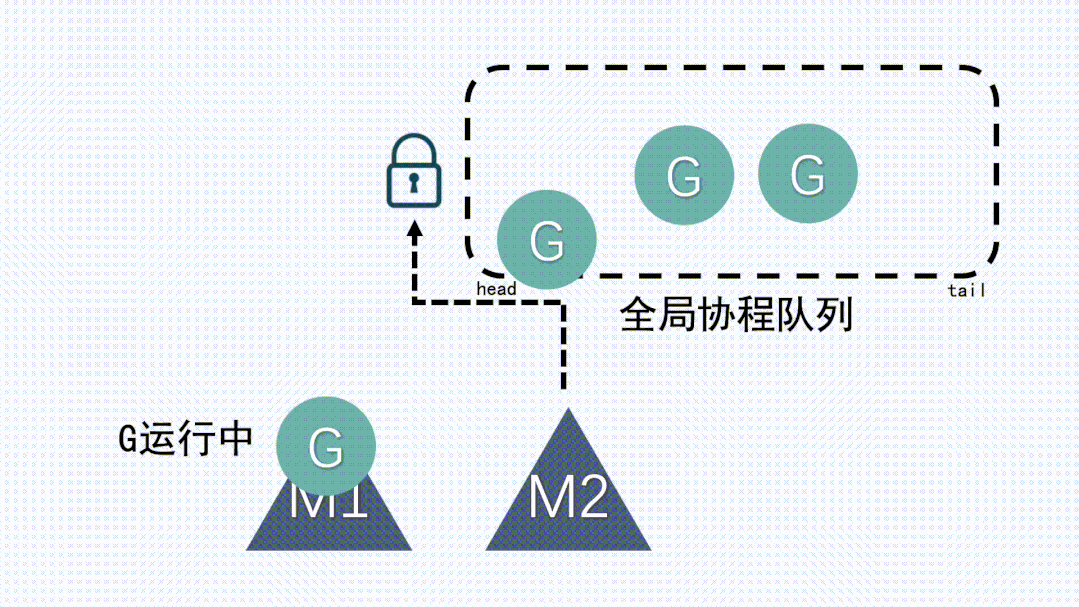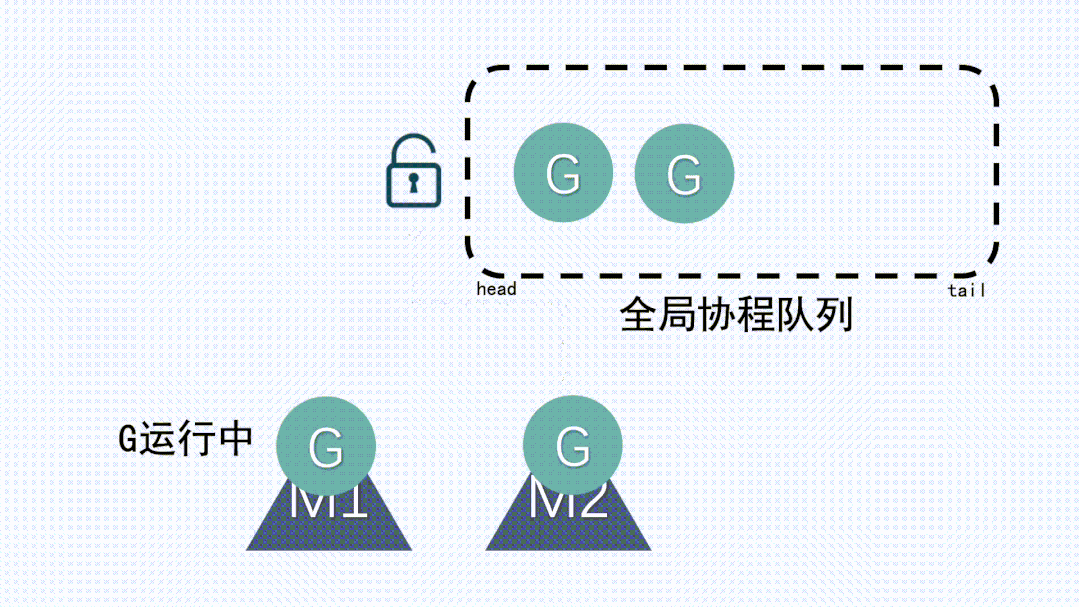
这就要说到go的历史版本了,在 Go1.1 之前 Go 的调度模型其实就是 GM 模型,也就是没有 P。 如下图:
G:gouritine协程。通常在代码里用 go 关键字执行一个方法,那么就等于起了一个G。
M:内核线程,操作系统内核其实看不见G(和P),只知道自己在执行一个线程。G(和P)都是在用户层上的实现。
-
除了G和M以外,还有一个全局协程队列,这个全局队列里放的是多个处于可运行状态的G。
-
1、M 想要执行、放回 G 都必须访问全局 G 队列,并且 M 有多个,即多线程访问同一资源需要加锁进行保证互斥 / 同步,所以全局 G 队列是有互斥锁进行保护的。
-
2、创建、销毁、调度 G 都需要每个 M 获取锁,这就形成了激烈的锁竞争。
-
3、M 转移 G 会造成延迟和额外的系统负载,这要求每个M都要能运行新创建的G:比如当 G 中包含创建新协程的时候,M 创建了 G’,为了继续执行 G,需要把 G’交给 M’执行,也造成了很差的局部性,因为 G’和 G 是相关的,最好放在 M 上执行,而不是其他 M’。
-
4、系统调用 (CPU 在 M 之间的切换) 导致频繁的线程阻塞和取消阻塞操作增加了系统开销。
- 而引入P后,P的本地队列做了一部分这个工作,本的本地队列对于M来说没有并发,并且对于全局G队列的依赖大大降低了。
最终加入了P从GM模型转变为GMP模型
-
为什么 P 的逻辑不直接加在 M 上
1、G的上下文交由M管理肯定如由P来管理,毕竟M是内核线程,开销更大
2、M 被系统调用阻塞后,我们是指望把他既有未执行的任务分配给其余继续运行的M,而不是一阻塞就致使当前M中所有的G都被阻塞。
3、其实引入P后,就有了两级调度系统,M不再关注于G的上下文,也不用去全局查找G,只需要在当前P的本地G队列获取执行G即可,所有与G有关的而可能带来的问题都交由P完成,而P是用户层级的,比线程解决这些问题时要方便的多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号