

Python做性能测试-1、Locust基础篇
前言:说起性能测试,大家想到的基本上都是工具jmeter和loadrunner多少也对执行性能测试的方式有一点认识,这些工具基本都实现了请求-响应-结果统计分析这样完整的测试链路,用户方面只需组织这些现成的插件即可实现性能测试过程,但是这些都不是对python友好的工具,对于python系用户来说不能用python接入和封装是一件很让人扫兴的事情,“Locust是使用Python语言编写实现的开源性能测试工具,简洁、轻量、高效,并发机制基于gevent协程,可以实现单机模拟生成较高的并发压。
那么什么是Locust呢?翻译过来就是蝗虫,支持Python 2.7、3.4、3.5和3.6。
理论:
1、Locust是一个易于使用,分布式,用户负载测试工具。它旨在测试web站点(或其他系统)的负载测试,并计算系统能够处理多少并发用户。在测试期间,我们定义一群蝗虫会攻击你的网站,每个蝗虫(或者测试用户)的行为是由您定义的,集群过程是由web UI实时监控的。
这将帮助您在允许真正的用户进入之前进行测试并识别代码中的瓶颈。蝗虫完全是基于事件的,因此可以在一台机器上支持数千个并发用户。与其他许多基于事件的应用程序不同,它不使用回调。相反,它通过gevent使用轻量级过程。每个蝗虫都在自己的进程中运行(正确地说,是绿色的)。这允许我们在Python中编写非常有表现力的场景,而不用回调使代码变得复杂。
2、用普通的Python编写用户测试场景不需要笨拙的ui或膨胀的xml,只需像通常那样编写代码即可。基于coroutines而不是回调,代码看起来和行为都像正常的,阻塞Python代码。分布式和可伸缩—支持成千上万的用户,蝗虫支持在多台机器上运行负载测试。由于基于事
件,即使一个Locust节点也可以在一个进程中处理数千个用户。这背后的部分原因是,即使您模拟了那么多用户,也不是所有用户都在积极地攻击您的系统。通常,用户都不知道下一步该做什么。每秒请求数!=在线用户数。基于web的UILocust有一个简洁的HTML+JS用户界面,实时显示相关的测试细节。由于UI是基于web的,所以它是跨平台的,易于扩展。可以测试任何系统尽管蝗虫是面向web的,但它几乎可以用来测试任何系统。只要写一个客户,不管你想测试什么,用蝗虫攻击它!这是超级简单!打算保持这种状态。所有繁重的任务都被委派给gevent。其他测试工具的脆弱性是开发者创建蝗虫的原因。
3、 locust产生是因为开发者厌倦了现有的解决办法。他们都没有解决正确的问题,没有抓住要点,他们之前尝试了Apache JMeter和Tsung。这两种工具都可以使用,我们在工作中多次使用过前者。JMeter有一个UI,你可能会认为它是一件好事。但是,您很快就会意识到,通过一些点单击界面“编码”测试场景是一个PITA。其次,JMeter是线装书。这意味着对于您想要模拟的每个用户,您都需要一个单独的线程。不用说,在一台机器上对成千上万的用户进行基准测试是不可行的。另一方面,Tsung并没有这些线程问题,因为它是用Erlang编写的。它可以利用光束本身提供的重量轻的过程,并愉快地放大。但是在定义测试场景时,Tsung和JMeter一样有限。它提供了一个基于xml的DSL来定义用户在测试时的行为。完成时显示任何类型的图形或报告都需要我们对测试生成的日志文件进行后期处理。只有这样,你才能了解测试是如何进行的。不管怎样,他们在创造蝗虫的时候已经试图解决这些问题。
一、安装:
1、Locust在PyPI上可用,可以通过pip或easy_install安装:pip install locustio
2、查看Locust可用选项:locust --help
3、在Windows上安装蝗虫在Windows上,运行pip安装locustio应该可以工作。但是,如果没有,很有可能可以通过首先为pyzmq、gevent和greenlet安装预构建的二进制包来修复它。下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/,当你下载了.whl文件后,你 可以通过以下命令安装:pip install name-of-file.whl
补充知识点:增加打开文件的最大数量限制机器上的每个HTTP连接都打开一个新文件(技术上是一个文件描述符)。操作系统可以为可打开的文件的最大数量设置一个低限制。如果限制小于测试中模拟用户的数量,就会发生故障。将操作系统的默认最大文件数量限制增加到 比您希望运行的模拟用户数量更高的数量。如何做到这一点取决于正在使用的操作系统。
注意:在Windows上运行蝗虫应该可以很好地开发和测试负载测试脚本。但是,在运行大规模测试时,建议您在Linux机器上这样做,因为gevent在Windows下的性能很差。
二、大家最关心的是如何使用locust去实战,这一节先说一下基础入门的,下面的代码是完成一个查询订单列表接口的性能测试,有俩种编写方式,先说第一种:
# 从locust中导入HttpLocust类(代表用户),TaskSet(任务集类) from locust import HttpLocust, TaskSet # 查询商品列表的接口 def test1(s): s.client.get('http://www.raincard.cn/api/v1/goods/list/admin/query') # 查询订单列表的接口 def test2(s): s.client.get('http://www.raincard.cn/api/v1/order/list/admin/query') class UserBehavior(TaskSet): # 创建一个子类继承TaskSet任务集类(任务集类可以定义事件的各种属性) tasks = {test2:2,test1:1} # 定义test2和test1事件的随机比例,执行时会按照这个比例随机请求这俩个事件 """ 创建一个子类继承HttpLocust类,HttpLocust类它代表一个用户,我们在其中定义一个模拟用户在执行任务之间应该等待多长时间, 以及什么TaskSet类应该定义用户的“行为”。任务集类可以嵌套。HttpLocust类继承自Locust类,并添加了一个客户端属性, 该属性是HttpSession的一个实例,可以用来发出HTTP请求。 """ class WebsiteUser(HttpLocust): host = 'http://www.raincard.cn/management/' # 在此处定义被测系统的地址 task_set = UserBehavior min_wait = 5000 # 执行俩个任务之间的最小等待时间 max_wait = 9000 # 执行俩个任务之间的最大等待时间
第二种方式:
""" 我们可以声明任务的另一种方式(通常更方便)是使用@task """ from locust import HttpLocust, TaskSet, task class UserBehavior(TaskSet): @task(2) # 这个装饰器代表test1这个任务执行的比例2,相对于test2来说是它的俩倍,也就是随机请求时概率更大,因为是模拟用户 #我们也不知道用户操作哪个任务更频繁,所以随机 def test1(self): self.client.get('http://www.raincard.cn/api/v1/goods/list/admin/query') @task(1) def test2(self): self.client.get('http://www.raincard.cn/api/v1/order/list/admin/query') class WebsiteUser(HttpLocust): host = 'http://www.raincard.cn/management/' task_set = UserBehavior min_wait = 5000 max_wait = 9000
二、模拟用户任务场景写好以后,接下来就是运行,我启动第二种方式文件:通过命令端启动
我在window下写的,cmd打开命令端:locust -f D:\Locust\locustfile.py --host=https://example.com (host后面是自己定义的被测系统的地址,用于标识的,在UI界面上等会可以看到,作用不大,如果在代码中已经定义好了,此处host就就不用再定义了)
因为host我已经在代码中已经定义好了,所以换这个启动方式:locust -f D:\Locust\locustfile.py
三、看运行的ui界面,截图如下:
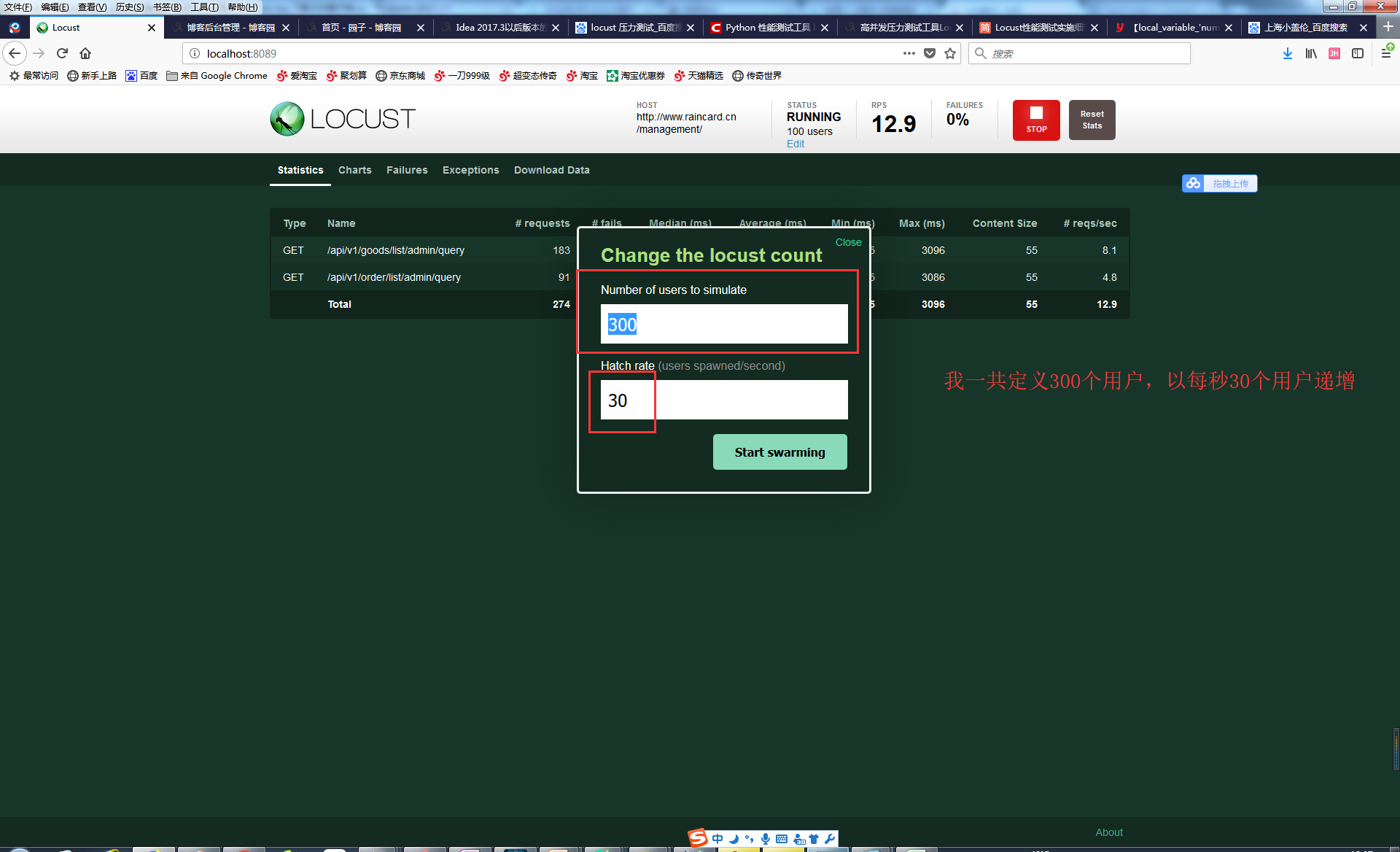
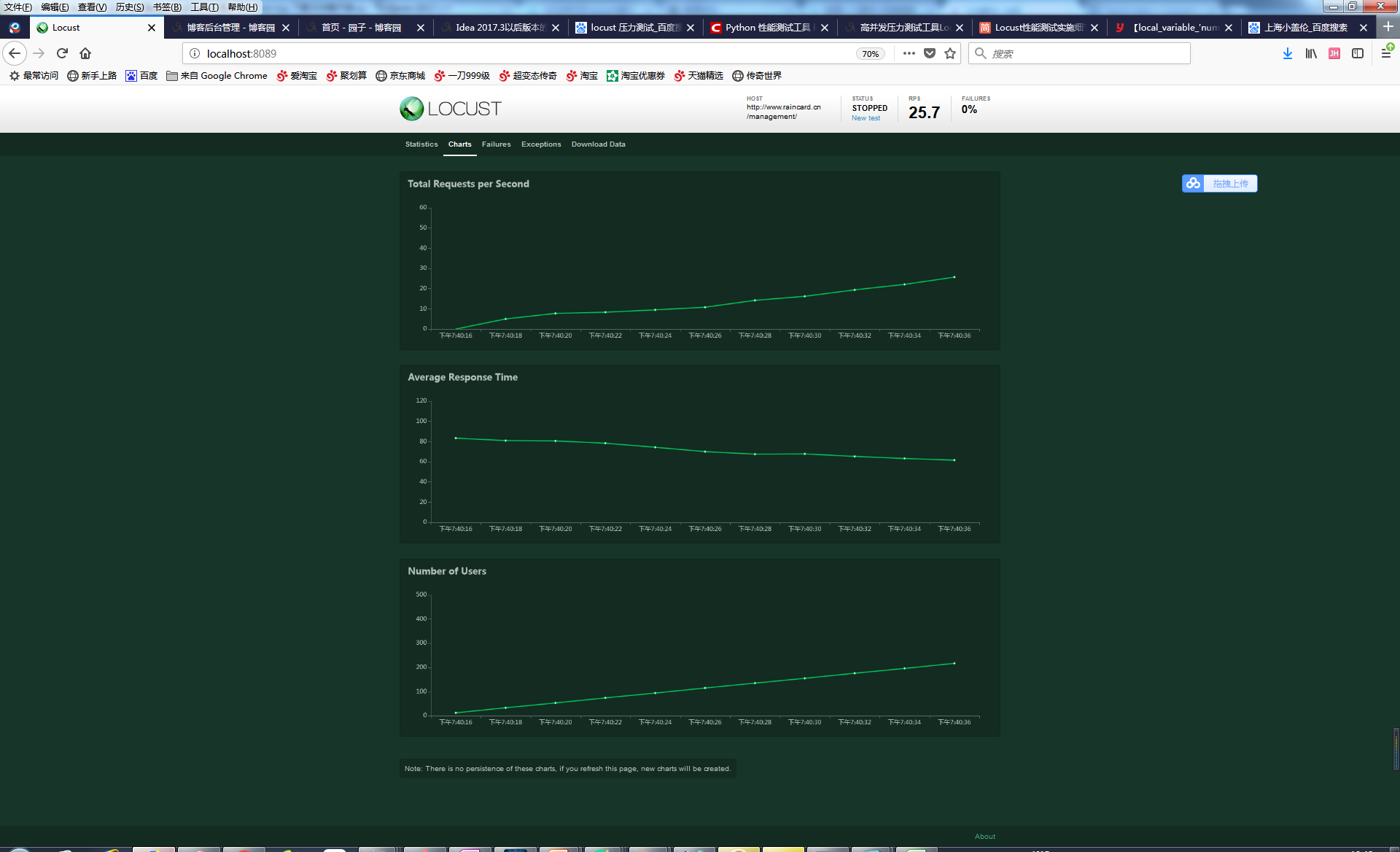
后面我会继续针对代码这部分深入讲解,今天只是入门,有兴趣的可以关注下,最近更新会比较频繁

