
Storm分布式集群搭建
一、storm版本
选用storm0.9.6

二、本地模式
用于对storm业务逻辑的调试和测试,可以直接在本地运行。
三、分布式模式
生产环境,需要对应的zookeeper、nimbus、supervisor和storm UI
四、主节点Nimbus。
nimbus作为storm的核心,肩负着对topology的调度和分配,接受storm客户端的命令以及storm UI的请求等任务。
master节点上部署nimbus
下载地址:http://storm.apache.org/2015/11/05/storm096-released.html
master 节点上 上传 解压
配置nimbus
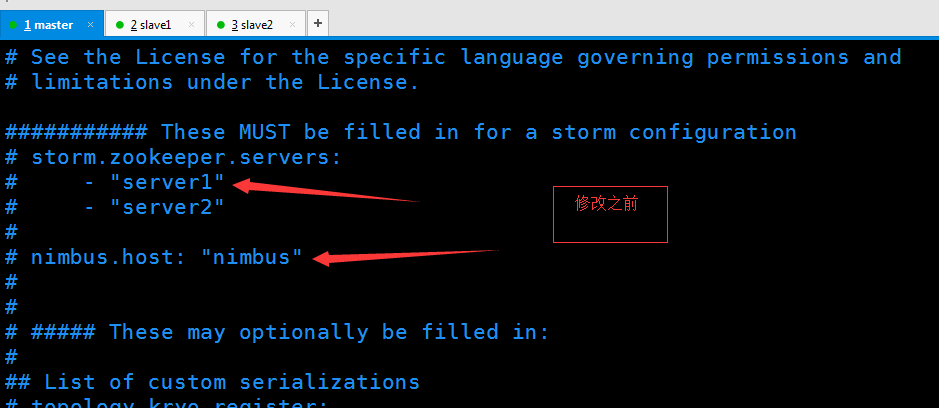
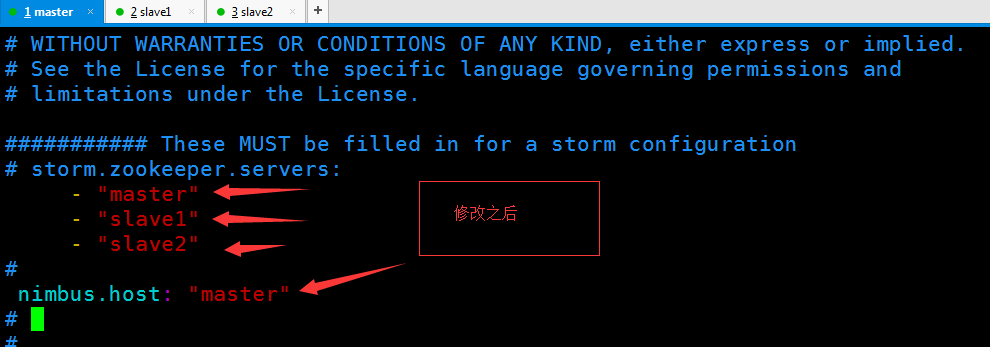
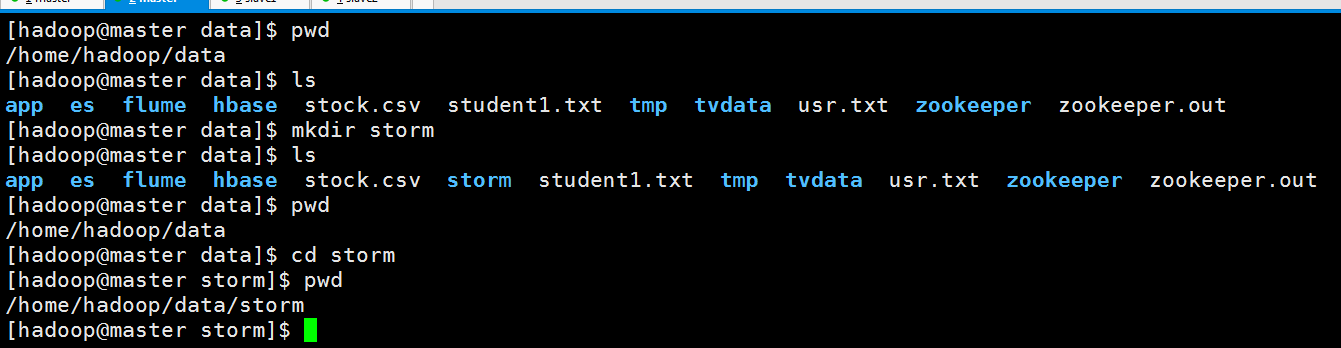
找到zookeeper存在的目录 创建storm
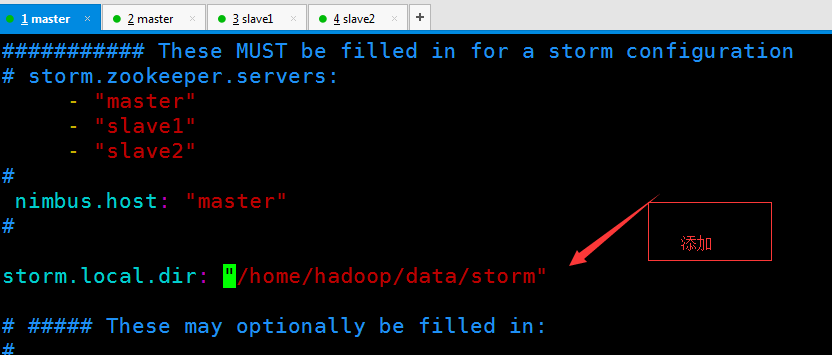
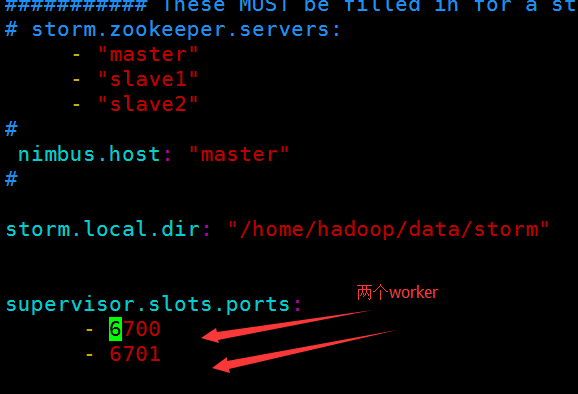
注意:
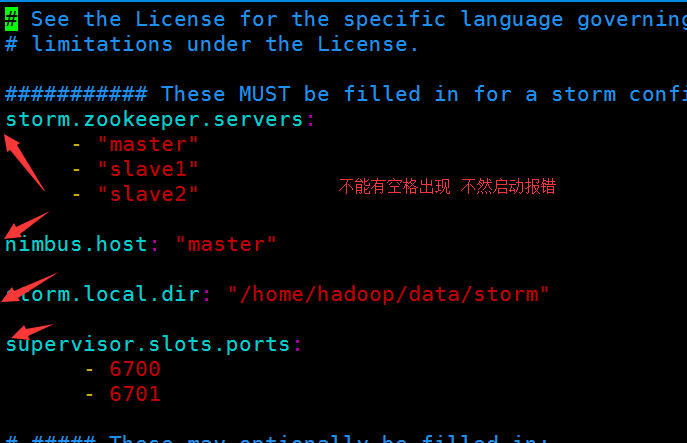
下面的配置可以更加方面 不用去目录下运行了

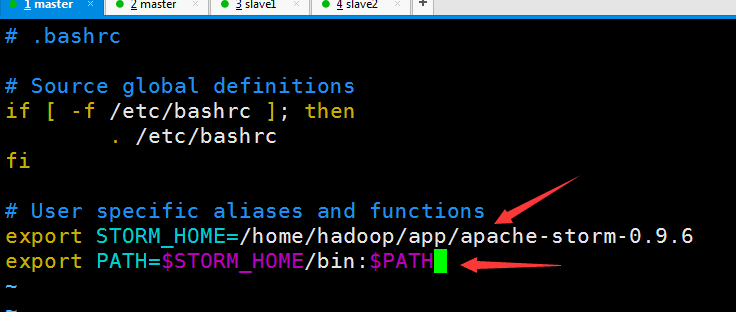
使其生效

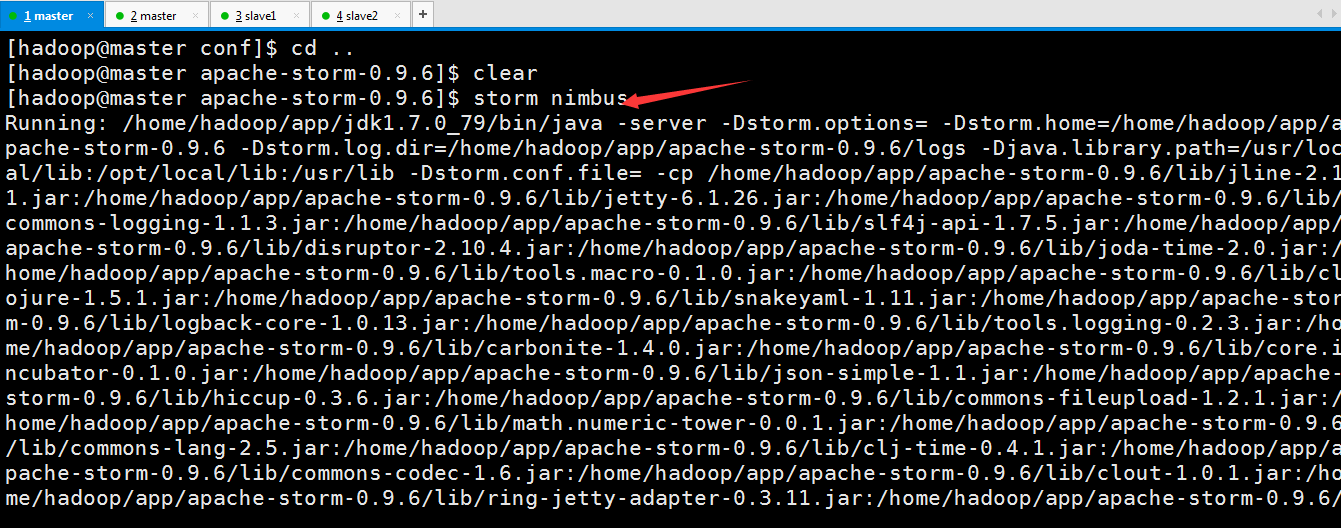
启动nimbus
五、工作节点Supervisor
Supervisor监听Nimbus的任务分配,启动worker来对相应的任务进行处理。通时Supervisor会对本地的worker进程进行监控,如果发现状态不正常会重启worker。如果任务多次失败,则将该任务交还给Nimbus进行再次重新分配。
将master节点的包发送至其他节点:scp apache-storm-0.9.6.tar.gz slave1:/home/hadoop/app
scp apache-storm-0.9.6.tar.gz slave2:/home/hadoop/app

解压:[hadoop@slave1 app]$ tar -zxvf apache-storm-0.9.6.tar.gz
[hadoop@slave2 app]$ tar -zxvf apache-storm-0.9.6.tar.gz
将master节点的配置文件拷贝到slave1 slave2

后台启动

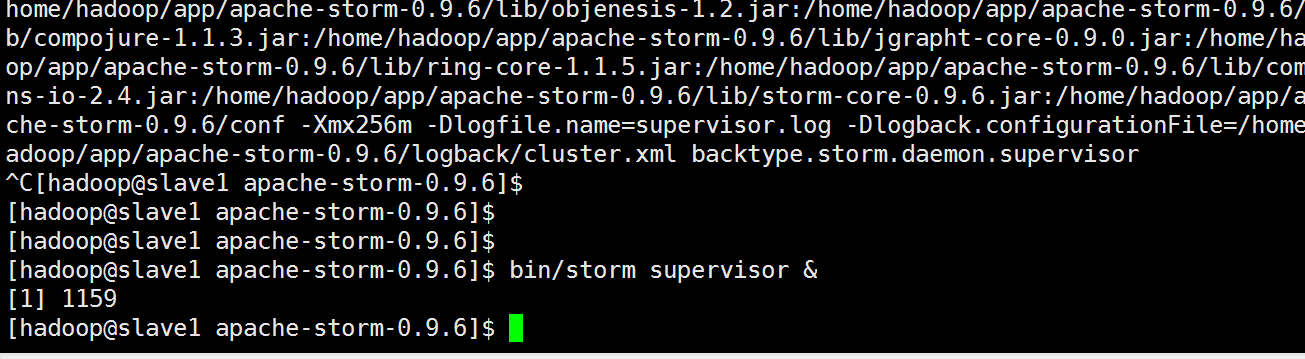
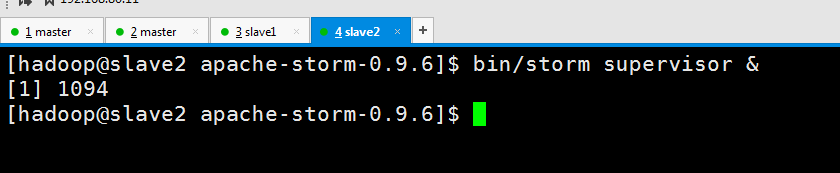
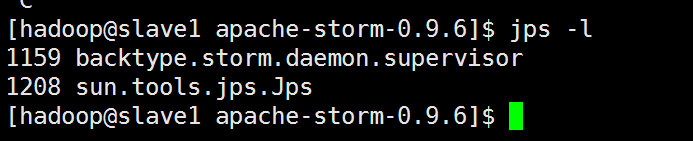
查看进程


六、storm UI
web服务器,在指定端口提供网页服务。可以获取系统配置、作业和各个组件的运行状态;可以暂停和撤销作业。
在nimbus节点(master)上部署storm UI
在nimbus节点启动strom UI

查看进程
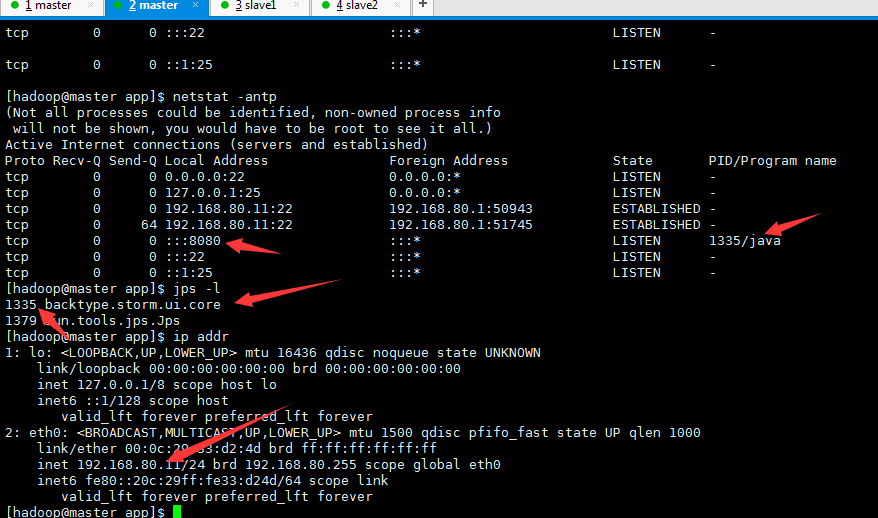
页面访问
192.168.80.11:8080
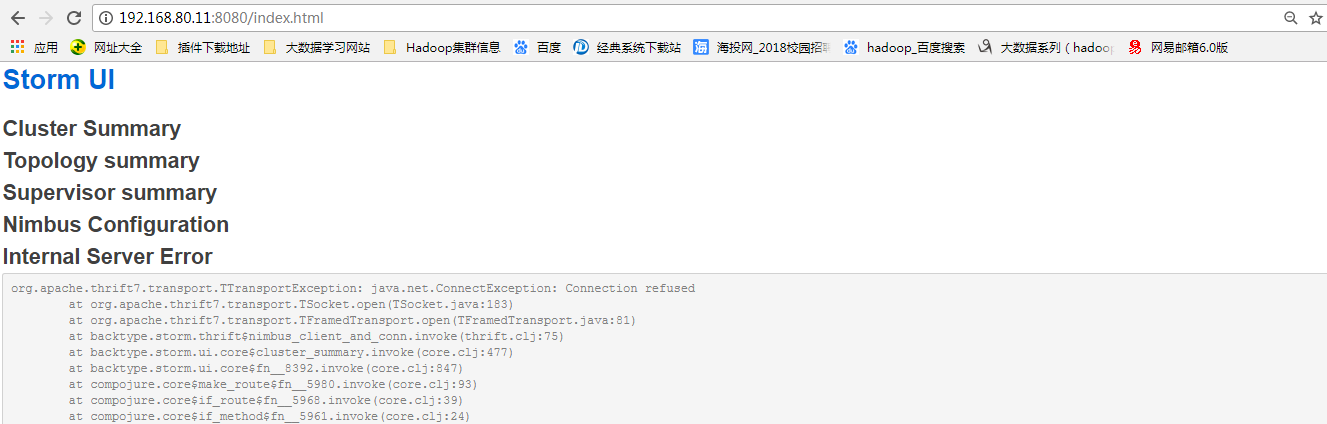
报错
记得启动zookeeper
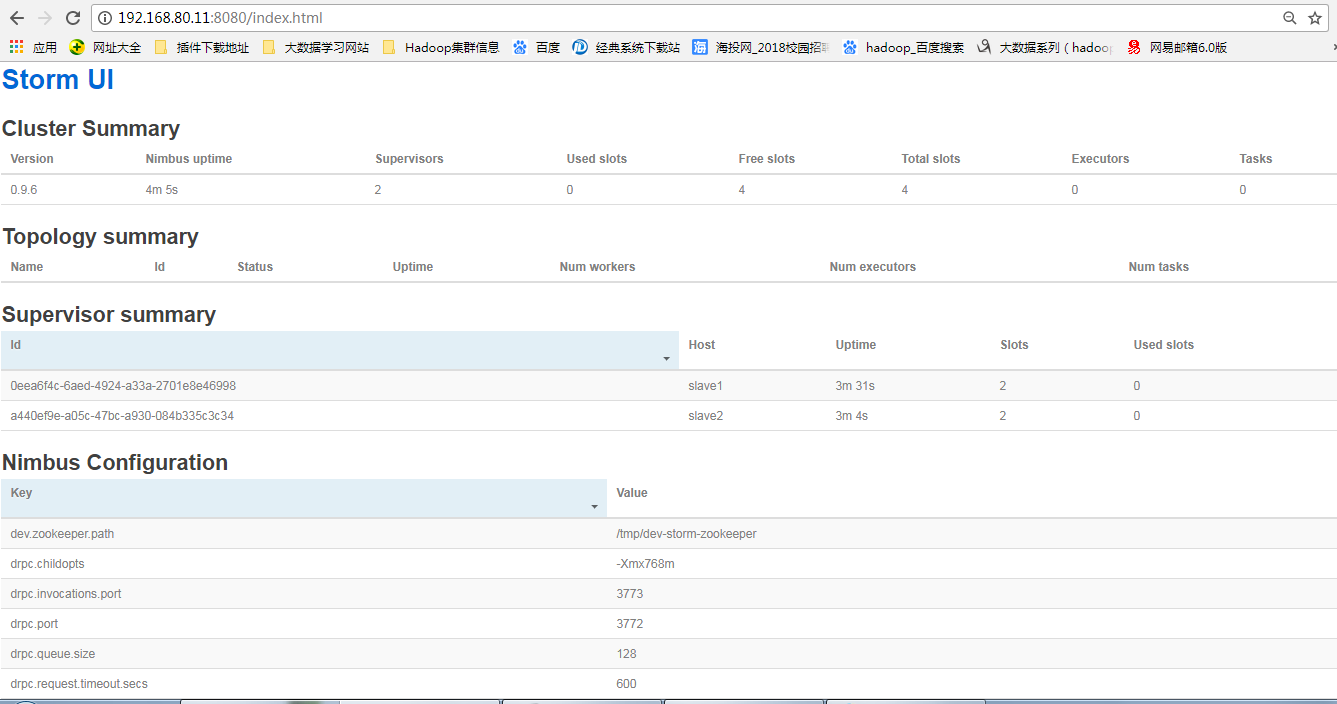
七、storm配置项
https://github.com/apache/storm/blob/master/conf/defaults.yaml
