机器学习-数据与特征工程
一、前言
1.机器学习与特征工程的关联
2.实际工业界的特征工程那些事儿
特征工程
特征 => 数据中抽取出来的对结果预测有用的信息
特征工程是使用专业背景知识和技巧处理数据,使得 特征能在机器学习算法上发挥更好的作用的过程。
意义
更好的特征意味着更强的灵活度
更好的特征意味着只需用简单模型
更好的特征意味着更好的结果
二、数据与特征处理
1.数据选择/清洗/采样
数据采集
哪些数据对最后的结果预测有帮助?
数据我们能够采集到吗?
线上实时计算的时候获取是否快捷?
举例1:我现在要预测用户对商品的下单情况,或者我要给用户做商品推荐,那我需要采集什么信息呢?
店家的,商品的,用户的(埋点)
大多数情况下,你的工作:思考哪些数据有用
埋点和数据打标存储会有其他的同学做
思考:我们现在就要用机器学习算法做一个模型,去预测同学们听七月算法的课,多有(xiang)兴(shui)趣(jiao),那我应该采集一些什么数据呢?
数据格式化
确定存储格式
a) 时间你用 年月日 or 时间戳 or 第几天 or …
b) 单个动作记录 or 一天行为聚合
c) …
大多数情况下,需要关联非常非常非常多的hive表和hdfs文件夹
数据清洗
garbage in, garbage out
算法大多数时候就是一个加工机器,至于最后的产品(成品)如何,取决于原材料的好坏
实际这个过程会花掉一大部分时间,而且它会使得你对于业务的理解非常透彻。
数据清洗做的事情 => 去掉脏数据
数据清洗示例/思考角度
简单的impossible
(1)身高3米+的人?
(2)一个月买脸盆墩布买了10w的人
(3)…
组合或统计属性判定
(1)号称在米国却ip一直都是大陆的新闻阅读用户?
(2)你要判定一个人是否会买篮球鞋,样本中女性用户85%?
补齐可对应的缺省值
(1)不可信的样本丢掉,缺省值极多的字段考虑不用
数据采样
很多情况下,正负样本是不均衡的
(1)电商的用户点/买过的商品和没有行为的商品
(2)某些疾病的患者 与 健康人
(3)…
大多数模型对正负样本比是敏感的(比如LR)
随机采样 和 分层抽样
正负样本不平衡处理办法
正样本 >> 负样本,且量都挺大 => downsampling(下采样)
正样本 >> 负样本,量不大 =>
1)采集更多的数据
2)上采样/oversampling(比如图像识别中的镜像和旋转)
3)修改损失函数/loss function
2.数值型/类别型/日期型/文本型特征处理
特征处理:
数值型
类别型
时间类
文本型
统计型
组合特征
特征处理之数值型
幅度调整/归一化
统计值max, min, mean, std
离散化
Hash分桶
每个类别下对应的变量统计值histogram(分布状况)
试试 数值型 => 类别型
统计量
import numpy as np
import pandas as pd
series = pd.Series(np.random.randn(500))
series_out = series.describe(percentiles=[.05, .25, .75, .95])
print(series_out)
count 500.000000
mean 0.016198
std 0.965494
min -2.809131
5% -1.651990
25% -0.557565
50% 0.007514
75% 0.681062
95% 1.585359
max 2.754240
离散化
import numpy as np
import pandas as pd
arr = np.random.randn(20)
factor = pd.cut(arr, 4)
print(factor)
factor = pd.cut(arr, [-5, -1, 0, 1 ,5])
print(factor)
[(-2.147, -1.308], (0.364, 1.2], (-1.308, -0.472], (-0.472, 0.364], (-1.308, -0.472], ..., (0.364, 1.2], (-1.308, -0.472], (0.364, 1.2], (-1.308, -0.472], (-2.147, -1.308]]
Length: 20
Categories (4, object): [(-2.147, -1.308] < (-1.308, -0.472] < (-0.472, 0.364] < (0.364, 1.2]]
[(-5, -1], (0, 1], (-1, 0], (0, 1], (-1, 0], ..., (0, 1], (-5, -1], (0, 1], (-1, 0], (-5, -1]]
Length: 20
Categories (4, object): [(-5, -1] < (-1, 0] < (0, 1] < (1, 5]]
柱状分布(比列)
import numpy as np
import pandas as pd
from sklearn import datasets
data = np.random.randint(0, 7, size=50)
print("data:",data)
s = pd.Series(data)
print(s.value_counts())
print(pd.value_counts(data))
data: [2 5 5 2 3 3 6 1 6 5 3 0 2 5 2 5 4 4 4 4 1 6 3 1 4 6 5 2 2 4 6 2 1 0 3 2 2
1 3 6 2 2 1 5 2 3 5 3 0 3]
2 12
3 9
5 8
6 6
4 6
1 6
0 3
dtype: int64
2 12
3 9
5 8
6 6
4 6
1 6
0 3
幅度调整到[0,1]范围
# -*- coding:utf-8 -*-
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn import preprocessing
X_train = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmx = min_max_scaler.fit_transform(X_train)
print("X_train_minmx:")
print(X_train_minmx)
X_test = np.array([[-3., -1., 4.]])
X_test_minmax = min_max_scaler.transform(X_test)
print("X_test_minmax:")
print(X_test_minmax)
X_train_minmx:
[[ 0.5 0. 1. ]
[ 1. 0.5 0.33333333]
[ 0. 1. 0. ]]
X_test_minmax:
[[-1.5 0. 1.66666667]]
归一化
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn import preprocessing
x = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
x_scaled = preprocessing.scale(x)
print("x_scaled:")
print(x_scaled)
print("x_scaled.mean(axis = 0):")
print(x_scaled.mean(axis = 0))
print("x_scaled.std(axis= =0):")
print(x_scaled.std(axis = 0))
x_scaled:
[[ 0. -1.22474487 1.33630621]
[ 1.22474487 0. -0.26726124]
[-1.22474487 1.22474487 -1.06904497]]
x_scaled.mean(axis = 0):
[ 0. 0. 0.]
x_scaled.std(axis= =0):
[ 1. 1. 1.]
特征处理之类别型
one-hot编码,编码完的称为哑变量
Hash与聚类处理
小技巧:统计每个类别变量下各个target比例,转成数值型
One-hot编码/哑变量
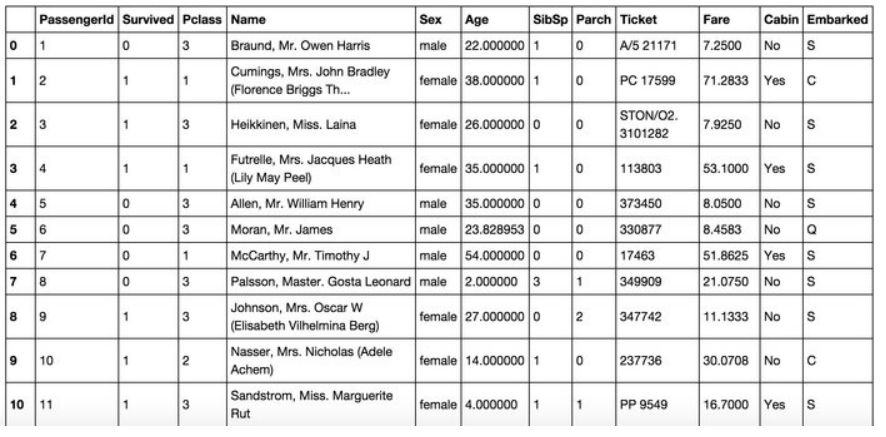

类别型特征Hash技巧处理

类别型特征Histogram映射处理
特征处理之时间型
既可以看做连续值,也可以看做离散值
连续值
a) 持续时间(单页浏览时长)
b) 间隔时间(上次购买/点击离现在的时间)
离散值
a) 一天中哪个时间段(hour_0-23)
b) 一周中星期几(week_monday...)
c) 一年中哪个星期
d) 一年中哪个季度
e) 工作日/周末
import time
day_of_week = lambda x: time.strptime(x, "%Y-%m-%d %H:%M:%S").weekday()
month = lambda x: time.strptime(x, "%Y-%m-%d %H:%M:%S").month
week_number = lambda x: time.strptime(x, "%Y-%m-%d %H:%M:%S").strftime('%V')
seasons = [0,0,0,1,1,1,2,2,2,3,3,3]
season = lambda x: seasons[(time.strptime(x, "%Y-%m-%d %H:%M:%S").month - 1)]
times_of_day = [0,0,0,0,0,1,1,1,1,2,2,2,2,3,3,3,4,4,4,4,5,5,5]
time_of_day = lambda x: time_of_day[time.strptime(x, "%Y-%m-%d %H:%M:%S").hour]
特征处理之文本型
词袋
文本数据预处理后,去掉停用词,剩下的词组成的list, 在词库中的映射稀疏向量。

词袋:
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df = 1)
print("vectorizer",vectorizer)
'''
vectorizer CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None)
'''
corpus = [
'This is the first document.',
'This is the second document.',
'Is this the first document?',
]
x = vectorizer.fit_transform(corpus)
print("x:",x)
'''
x: (0, 5) 1
(0, 2) 1
(0, 4) 1
(0, 1) 1
(0, 0) 1
(1, 5) 1
(1, 2) 1
(1, 4) 1
(1, 0) 1
(1, 3) 1
(2, 5) 1
(2, 2) 1
(2, 4) 1
(2, 1) 1
(2, 0) 1
'''
词袋中的词扩充到n-gram
from sklearn.feature_extraction.text import CountVectorizer
bigram_vectorizer = CountVectorizer(ngram_range=(1, 2))
analyze = bigram_vectorizer.build_analyzer()
print(analyze('bi-grams are cool') == (['bi','grams','are','cool','bi grams','grams are','are cool']))
#True
corpus = [
'This is the first document.',
'This is the second document.',
'Is this the first document?',
]
x_2 = bigram_vectorizer.fit_transform(corpus).toarray(0)
# print("x_2:",x_2)
'''
x_2: [[1 1 1 1 1 0 0 0 1 1 0 1 1 0]
[1 0 0 1 1 0 1 1 1 0 1 1 1 0]
[1 1 1 1 0 1 0 0 1 1 0 1 0 1]]
'''
feature_index = bigram_vectorizer.vocabulary_.get('is this')
print(x_2[:,feature_index])
#[0 0 1]
特征处理之文本型
使用Tf–idf 特征
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成 反比下降。
TF: Term Frequency
TF(t) = (词t在当前文中出现次数) / (t在全部文档中出现次数)
IDF:
IDF(t) = ln(总文档数/ 含t的文档数)
TF-IDF权重 = TF(t) * IDF(t)
特征处理之文本型
词袋 => word2vec

词袋 => word2vec
工具:google word2vec
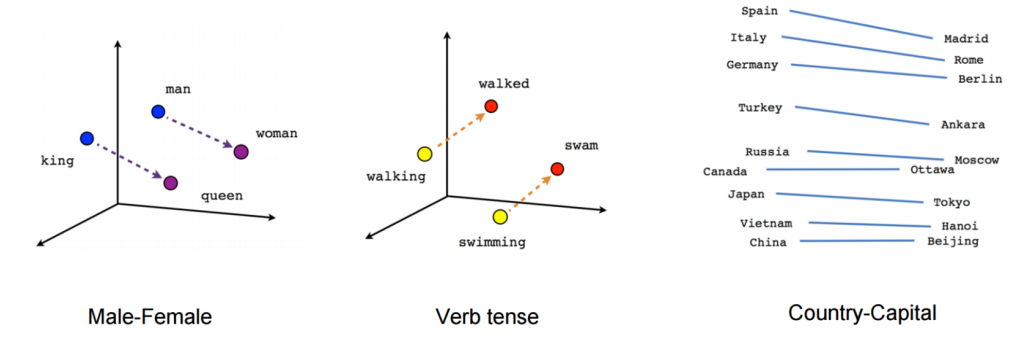
特征处理之统计特征
历届的Kaggle/天池比赛,天猫/京东排序和推荐业务线里模型用到的特征
加减平均:商品价格高于平均价格多少,用户在某个品 类下消费超过平均用户多少,用户连续登录天数超过平 均多少...
分位线:商品属于售出商品价格的多少分位线处
次序型:排在第几位
比例类:电商中,好/中/差评比例 你已超过全国百分之…的同学
事例:天池大数据之移动推荐算法大赛

(1) 前一天的购物车商品很有可能第二天就被购买 =>规则
(2) 剔除掉在30天里从来不买东西的人 => 数据清洗
(3) 加车N件,只买了一件的,剩余的不会买 => 规则
(4) 购物车购买转化率 =>用户维度统计特征
(5) 商品热度 =>商品维度统计特征
(6) 对不同item点击/收藏/购物车/购买的总计 =>商品维度统计特征
(7) 对不同item点击/收藏/购物车/购买平均每个user的计数 =>用户维度统计特征
(8) 变热门的品牌/商品 =>商品维度统计特征(差值型)
(9) 最近第1/2/3/7天的行为数与平均行为数的比值 =>用户维度统计特征(比例型)
(10)商品在类别中的排序 =>商品维度统计特征(次序型)
(11) 商品交互的总人数 =>商品维度统计特征(求和型)
(12)商品的购买转化率及转化率与类别平均转化率的比值=>商品维度统计特征(比例型)
(13)商品行为/同类同行为均值=>商品维度统计特征(比例型)
(14) 最近1/2/3天的行为(按4类统计)=>时间型+用户维度统计特征
(15)最近的交互离现在的时间=>时间型
(16)总交互的天数=>时间型
(17)用户A对品牌B的总购买数/收藏数/购物车数=>用户维度统计特征
(18)用户A对品牌B的点击数的平方 =>用户维度统计特征
(19)用户A对品牌B的购买数的平方=>用户维度统计特征
(20)用户A对品牌B的点击购买比=>用户维度统计特征(比例型)
(21)用户交互本商品前/后,交互的商品数=>时间型+用户维度统计特征
(22)用户前一天最晚的交互行为时间=>时间型
(23)用户购买商品的时间(平均,最早,最晚)=>时间型
特征处理之组合特征
简单组合特征:拼接型
user_id&&category: 10001&&女裙 10002&&男士牛仔
user_id&&style: 10001&&蕾丝 10002&&全棉
实际电商点击率预估中:
正负权重,喜欢&&不喜欢某种类型
模型特征组合
用GBDT产出特征组合路径
组合特征和原始特征一起放进LR训练
最早Facebook使用的方式,多家互联网公司在用
三、特征选择
原因:
冗余:部分特征的相关度太高了,消耗计算性能。
噪声:部分特征是对预测结果有负影响
特征选择 VS 降维
前者只踢掉原本特征里和结果预测关系不大的,后者做特征的计算组合构成新特征
SVD或者PCA确实也能解决一定的高维度问题
常见特征选择方式之 过滤型 (Filter)
评估单个特征和结果值之间的相关程度,排序留下Top 相关的特征部分。
评价指标:Pearson相关系数,互信息,距离相关度
缺点:没有考虑到特征之间的关联作用,可能把有用的关联特征误踢掉。(工业界很少用)
import numpy as np
from scipy.stats import pearsonr
np.random.seed(0)
size = 300
x = np.random.normal(0, 1, size)#正态分布
print("Lower noise", pearsonr(x, x + np.random.normal(0, 1, size)))#增加扰动
print("Higher noise", pearsonr(x, x + np.random.normal(0, 10, size)))
'''
Lower noise (0.71824836862138408, 7.3240173129983507e-49)
Higher noise (0.057964292079338155, 0.31700993885324752)
'''
过滤型特征选择Python包

from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
iris = load_iris()
x, y = iris.data, iris.target
print("x.shape:")
print(x.shape)
x_new = SelectKBest(chi2, k = 2).fit_transform(x, y)
print("x_new.shape:")
print(x_new.shape)
'''
x.shape:
(150, 4)
x_new.shape:
(150, 2)
'''
常见特征选择方式之 包裹型(Wrapper)
把特征选择看做一个特征子集搜索问题,筛选各种特 征子集,用模型评估效果。
典型的包裹型算法为 “递归特征删除算法”(recursive feature elimination algorithm) RFE
比如用逻辑回归,怎么做这个事情呢?
① 用全量特征跑一个模型
② 根据线性模型的系数(体现相关性),删掉5-10%的弱特征,观察准确率/auc的变化
③ 逐步进行,直至准确率/auc出现大的下滑停止
包裹型特征选择Python包:

from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
boston = load_boston()#波士顿房价数据集
x = boston["data"]
y = boston["target"]
names = boston["feature_names"]
#使用线性回归作为模型
lr = LinearRegression()
#rank all features, continue the elimination until the last one
rfe = RFE(lr, n_features_to_select=1)
rfe.fit(x, y)
print("Features sorted by their rank:")
print(sorted(zip(map(lambda x: round(x, 4), rfe.ranking_), names)))
'''
Features sorted by their rank:
[(1, 'NOX'), (2, 'RM'), (3, 'CHAS'), (4, 'PTRATIO'), (5, 'DIS'), (6, 'LSTAT'),
(7, 'RAD'), (8, 'CRIM'), (9, 'INDUS'), (10, 'ZN'),
(11, 'TAX'), (12, 'B'), (13, 'AGE')]
'''
常见特征选择方式之 嵌入型
根据模型来分析特征的重要性(有别于上面的方式, 是从生产的模型权重等)。
最常见的方式为用正则化方式来做特征选择。
举个例子,最早在电商用LR做CTR预估,在3-5亿维的系数 特征上用L1正则化的LR模型。剩余2-3千万的feature,意味着其他的feature重要度不够。
嵌入型特征选择Python包 :

from sklearn.svm import LinearSVC
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectFromModel
iris = load_iris()
x, y = iris.data, iris.target
print("x.shape:")
print(x.shape)
lsvc = LinearSVC(c = 0.01, penalty="11", dual=False).fit(x, y)
model = SelectFromModel(lsvc, prefit = True)
x_new = model.transform(x)
print("x_new.shape:")
x_new.shape
'''
x.shape:
(150,4)
x_new.shape:
(150,3)
'''
四、特征工程案例
数据集:
链接:https://pan.baidu.com/s/1Fyq79oHiWpINiDSvlVUh0g
提取码:fhpz
特征工程小案例
Kaggle上有这样一个比赛:城市自行车共享系统使用状况。
提供的数据为2年内按小时做的自行车租赁数据,其中训练集由每个月的前19天组成,测试集由20号之后的时间组成。
In [3]:
#先把数据读进来
import pandas as pd
data = pd.read_csv('kaggle_bike_competition_train.csv', header = 0, error_bad_lines=False)
In [30]:
前5行
#看一眼数据长什么样 前5行
data.head()
Out[30]:
datetime season holiday workingday weather temp atemp humidity windspeed casual registered count
0 2011-01-01 00:00:00 1 0 0 1 9.84 14.395 81 0.0 3 13 16
1 2011-01-01 01:00:00 1 0 0 1 9.02 13.635 80 0.0 8 32 40
2 2011-01-01 02:00:00 1 0 0 1 9.02 13.635 80 0.0 5 27 32
3 2011-01-01 03:00:00 1 0 0 1 9.84 14.395 75 0.0 3 10 13
4 2011-01-01 04:00:00 1 0 0 1 9.84 14.395 75 0.0 0 1 1
把datetime域切成 日期 和 时间 两部分。
In [32]:
# 处理时间字段
temp = pd.DatetimeIndex(data['datetime'])
data['date'] = temp.date
data['time'] = temp.time
data.head()
Out[32]:
datetime season holiday workingday weather temp atemp humidity windspeed casual registered count date time
0 2011-01-01 00:00:00 1 0 0 1 9.84 14.395 81 0.0 3 13 16 2011-01-01 00:00:00
1 2011-01-01 01:00:00 1 0 0 1 9.02 13.635 80 0.0 8 32 40 2011-01-01 01:00:00
2 2011-01-01 02:00:00 1 0 0 1 9.02 13.635 80 0.0 5 27 32 2011-01-01 02:00:00
3 2011-01-01 03:00:00 1 0 0 1 9.84 14.395 75 0.0 3 10 13 2011-01-01 03:00:00
4 2011-01-01 04:00:00 1 0 0 1 9.84 14.395 75 0.0 0 1 1 2011-01-01 04:00:00
时间那部分,好像最细的粒度也只到小时,所以我们干脆把小时字段拿出来作为更简洁的特征。
In [33]:
# 设定hour这个小时字段
data['hour'] = pd.to_datetime(data.time, format="%H:%M:%S")
data['hour'] = pd.Index(data['hour']).hour
data
Out[33]:
datetime season holiday workingday weather temp atemp humidity windspeed casual registered count date time hour
0 2011-01-01 00:00:00 1 0 0 1 9.84 14.395 81 0.0000 3 13 16 2011-01-01 00:00:00 0
1 2011-01-01 01:00:00 1 0 0 1 9.02 13.635 80 0.0000 8 32 40 2011-01-01 01:00:00 1
2 2011-01-01 02:00:00 1 0 0 1 9.02 13.635 80 0.0000 5 27 32 2011-01-01 02:00:00 2
3 2011-01-01 03:00:00 1 0 0 1 9.84 14.395 75 0.0000 3 10 13 2011-01-01 03:00:00 3
4 2011-01-01 04:00:00 1 0 0 1 9.84 14.395 75 0.0000 0 1 1 2011-01-01 04:00:00 4
5 2011-01-01 05:00:00 1 0 0 2 9.84 12.880 75 6.0032 0 1 1 2011-01-01 05:00:00 5
6 2011-01-01 06:00:00 1 0 0 1 9.02 13.635 80 0.0000 2 0 2 2011-01-01 06:00:00 6
7 2011-01-01 07:00:00 1 0 0 1 8.20 12.880 86 0.0000 1 2 3 2011-01-01 07:00:00 7
8 2011-01-01 08:00:00 1 0 0 1 9.84 14.395 75 0.0000 1 7 8 2011-01-01 08:00:00 8
9 2011-01-01 09:00:00 1 0 0 1 13.12 17.425 76 0.0000 8 6 14 2011-01-01 09:00:00 9
10 2011-01-01 10:00:00 1 0 0 1 15.58 19.695 76 16.9979 12 24 36 2011-01-01 10:00:00 10
11 2011-01-01 11:00:00 1 0 0 1 14.76 16.665 81 19.0012 26 30 56 2011-01-01 11:00:00 11
12 2011-01-01 12:00:00 1 0 0 1 17.22 21.210 77 19.0012 29 55 84 2011-01-01 12:00:00 12
13 2011-01-01 13:00:00 1 0 0 2 18.86 22.725 72 19.9995 47 47 94 2011-01-01 13:00:00 13
14 2011-01-01 14:00:00 1 0 0 2 18.86 22.725 72 19.0012 35 71 106 2011-01-01 14:00:00 14
15 2011-01-01 15:00:00 1 0 0 2 18.04 21.970 77 19.9995 40 70 110 2011-01-01 15:00:00 15
16 2011-01-01 16:00:00 1 0 0 2 17.22 21.210 82 19.9995 41 52 93 2011-01-01 16:00:00 16
17 2011-01-01 17:00:00 1 0 0 2 18.04 21.970 82 19.0012 15 52 67 2011-01-01 17:00:00 17
18 2011-01-01 18:00:00 1 0 0 3 17.22 21.210 88 16.9979 9 26 35 2011-01-01 18:00:00 18
19 2011-01-01 19:00:00 1 0 0 3 17.22 21.210 88 16.9979 6 31 37 2011-01-01 19:00:00 19
20 2011-01-01 20:00:00 1 0 0 2 16.40 20.455 87 16.9979 11 25 36 2011-01-01 20:00:00 20
21 2011-01-01 21:00:00 1 0 0 2 16.40 20.455 87 12.9980 3 31 34 2011-01-01 21:00:00 21
22 2011-01-01 22:00:00 1 0 0 2 16.40 20.455 94 15.0013 11 17 28 2011-01-01 22:00:00 22
23 2011-01-01 23:00:00 1 0 0 2 18.86 22.725 88 19.9995 15 24 39 2011-01-01 23:00:00 23
24 2011-01-02 00:00:00 1 0 0 2 18.86 22.725 88 19.9995 4 13 17 2011-01-02 00:00:00 0
25 2011-01-02 01:00:00 1 0 0 2 18.04 21.970 94 16.9979 1 16 17 2011-01-02 01:00:00 1
26 2011-01-02 02:00:00 1 0 0 2 17.22 21.210 100 19.0012 1 8 9 2011-01-02 02:00:00 2
27 2011-01-02 03:00:00 1 0 0 2 18.86 22.725 94 12.9980 2 4 6 2011-01-02 03:00:00 3
28 2011-01-02 04:00:00 1 0 0 2 18.86 22.725 94 12.9980 2 1 3 2011-01-02 04:00:00 4
29 2011-01-02 06:00:00 1 0 0 3 17.22 21.210 77 19.9995 0 2 2 2011-01-02 06:00:00 6
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
10856 2012-12-18 18:00:00 4 0 1 1 15.58 19.695 46 22.0028 13 512 525 2012-12-18 18:00:00 18
10857 2012-12-18 19:00:00 4 0 1 1 15.58 19.695 46 26.0027 19 334 353 2012-12-18 19:00:00 19
10858 2012-12-18 20:00:00 4 0 1 1 14.76 16.665 50 16.9979 4 264 268 2012-12-18 20:00:00 20
10859 2012-12-18 21:00:00 4 0 1 1 14.76 17.425 50 15.0013 9 159 168 2012-12-18 21:00:00 21
10860 2012-12-18 22:00:00 4 0 1 1 13.94 16.665 49 0.0000 5 127 132 2012-12-18 22:00:00 22
10861 2012-12-18 23:00:00 4 0 1 1 13.94 17.425 49 6.0032 1 80 81 2012-12-18 23:00:00 23
10862 2012-12-19 00:00:00 4 0 1 1 12.30 15.910 61 0.0000 6 35 41 2012-12-19 00:00:00 0
10863 2012-12-19 01:00:00 4 0 1 1 12.30 15.910 65 6.0032 1 14 15 2012-12-19 01:00:00 1
10864 2012-12-19 02:00:00 4 0 1 1 11.48 15.150 65 6.0032 1 2 3 2012-12-19 02:00:00 2
10865 2012-12-19 03:00:00 4 0 1 1 10.66 13.635 75 8.9981 0 5 5 2012-12-19 03:00:00 3
10866 2012-12-19 04:00:00 4 0 1 1 9.84 12.120 75 8.9981 1 6 7 2012-12-19 04:00:00 4
10867 2012-12-19 05:00:00 4 0 1 1 10.66 14.395 75 6.0032 2 29 31 2012-12-19 05:00:00 5
10868 2012-12-19 06:00:00 4 0 1 1 9.84 12.880 75 6.0032 3 109 112 2012-12-19 06:00:00 6
10869 2012-12-19 07:00:00 4 0 1 1 10.66 13.635 75 8.9981 3 360 363 2012-12-19 07:00:00 7
10870 2012-12-19 08:00:00 4 0 1 1 9.84 12.880 87 7.0015 13 665 678 2012-12-19 08:00:00 8
10871 2012-12-19 09:00:00 4 0 1 1 11.48 14.395 75 7.0015 8 309 317 2012-12-19 09:00:00 9
10872 2012-12-19 10:00:00 4 0 1 1 13.12 16.665 70 7.0015 17 147 164 2012-12-19 10:00:00 10
10873 2012-12-19 11:00:00 4 0 1 1 16.40 20.455 54 15.0013 31 169 200 2012-12-19 11:00:00 11
10874 2012-12-19 12:00:00 4 0 1 1 16.40 20.455 54 19.0012 33 203 236 2012-12-19 12:00:00 12
10875 2012-12-19 13:00:00 4 0 1 1 17.22 21.210 50 12.9980 30 183 213 2012-12-19 13:00:00 13
10876 2012-12-19 14:00:00 4 0 1 1 17.22 21.210 50 12.9980 33 185 218 2012-12-19 14:00:00 14
10877 2012-12-19 15:00:00 4 0 1 1 17.22 21.210 50 19.0012 28 209 237 2012-12-19 15:00:00 15
10878 2012-12-19 16:00:00 4 0 1 1 17.22 21.210 50 23.9994 37 297 334 2012-12-19 16:00:00 16
10879 2012-12-19 17:00:00 4 0 1 1 16.40 20.455 50 26.0027 26 536 562 2012-12-19 17:00:00 17
10880 2012-12-19 18:00:00 4 0 1 1 15.58 19.695 50 23.9994 23 546 569 2012-12-19 18:00:00 18
10881 2012-12-19 19:00:00 4 0 1 1 15.58 19.695 50 26.0027 7 329 336 2012-12-19 19:00:00 19
10882 2012-12-19 20:00:00 4 0 1 1 14.76 17.425 57 15.0013 10 231 241 2012-12-19 20:00:00 20
10883 2012-12-19 21:00:00 4 0 1 1 13.94 15.910 61 15.0013 4 164 168 2012-12-19 21:00:00 21
10884 2012-12-19 22:00:00 4 0 1 1 13.94 17.425 61 6.0032 12 117 129 2012-12-19 22:00:00 22
10885 2012-12-19 23:00:00 4 0 1 1 13.12 16.665 66 8.9981 4 84 88 2012-12-19 23:00:00 23
10886 rows × 15 columns
仔细想想,数据只告诉我们是哪天了,按照一般逻辑,应该周末和工作日出去的人数量不同吧。我们设定一个新的字段dayofweek表示是一周中的第几天。再设定一个字段dateDays表示离第一天开始租车多久了(猜测在欧美国家,这种绿色环保的出行方式,会迅速蔓延吧)
In [35]:
# 我们对时间类的特征做处理,产出一个星期几的类别型变量
data['dayofweek'] = pd.DatetimeIndex(data.date).dayofweek
# 对时间类特征处理,产出一个时间长度变量
data['dateDays'] = (data.date - data.date[0]).astype('timedelta64[D]')
data
Out[35]:
datetime season holiday workingday weather temp atemp humidity windspeed casual registered count date time hour dayofweek dateDays
0 2011-01-01 00:00:00 1 0 0 1 9.84 14.395 81 0.0000 3 13 16 2011-01-01 00:00:00 0 5 0.0
1 2011-01-01 01:00:00 1 0 0 1 9.02 13.635 80 0.0000 8 32 40 2011-01-01 01:00:00 1 5 0.0
2 2011-01-01 02:00:00 1 0 0 1 9.02 13.635 80 0.0000 5 27 32 2011-01-01 02:00:00 2 5 0.0
3 2011-01-01 03:00:00 1 0 0 1 9.84 14.395 75 0.0000 3 10 13 2011-01-01 03:00:00 3 5 0.0
4 2011-01-01 04:00:00 1 0 0 1 9.84 14.395 75 0.0000 0 1 1 2011-01-01 04:00:00 4 5 0.0
5 2011-01-01 05:00:00 1 0 0 2 9.84 12.880 75 6.0032 0 1 1 2011-01-01 05:00:00 5 5 0.0
6 2011-01-01 06:00:00 1 0 0 1 9.02 13.635 80 0.0000 2 0 2 2011-01-01 06:00:00 6 5 0.0
7 2011-01-01 07:00:00 1 0 0 1 8.20 12.880 86 0.0000 1 2 3 2011-01-01 07:00:00 7 5 0.0
8 2011-01-01 08:00:00 1 0 0 1 9.84 14.395 75 0.0000 1 7 8 2011-01-01 08:00:00 8 5 0.0
9 2011-01-01 09:00:00 1 0 0 1 13.12 17.425 76 0.0000 8 6 14 2011-01-01 09:00:00 9 5 0.0
10 2011-01-01 10:00:00 1 0 0 1 15.58 19.695 76 16.9979 12 24 36 2011-01-01 10:00:00 10 5 0.0
11 2011-01-01 11:00:00 1 0 0 1 14.76 16.665 81 19.0012 26 30 56 2011-01-01 11:00:00 11 5 0.0
12 2011-01-01 12:00:00 1 0 0 1 17.22 21.210 77 19.0012 29 55 84 2011-01-01 12:00:00 12 5 0.0
13 2011-01-01 13:00:00 1 0 0 2 18.86 22.725 72 19.9995 47 47 94 2011-01-01 13:00:00 13 5 0.0
14 2011-01-01 14:00:00 1 0 0 2 18.86 22.725 72 19.0012 35 71 106 2011-01-01 14:00:00 14 5 0.0
15 2011-01-01 15:00:00 1 0 0 2 18.04 21.970 77 19.9995 40 70 110 2011-01-01 15:00:00 15 5 0.0
16 2011-01-01 16:00:00 1 0 0 2 17.22 21.210 82 19.9995 41 52 93 2011-01-01 16:00:00 16 5 0.0
17 2011-01-01 17:00:00 1 0 0 2 18.04 21.970 82 19.0012 15 52 67 2011-01-01 17:00:00 17 5 0.0
18 2011-01-01 18:00:00 1 0 0 3 17.22 21.210 88 16.9979 9 26 35 2011-01-01 18:00:00 18 5 0.0
19 2011-01-01 19:00:00 1 0 0 3 17.22 21.210 88 16.9979 6 31 37 2011-01-01 19:00:00 19 5 0.0
20 2011-01-01 20:00:00 1 0 0 2 16.40 20.455 87 16.9979 11 25 36 2011-01-01 20:00:00 20 5 0.0
21 2011-01-01 21:00:00 1 0 0 2 16.40 20.455 87 12.9980 3 31 34 2011-01-01 21:00:00 21 5 0.0
22 2011-01-01 22:00:00 1 0 0 2 16.40 20.455 94 15.0013 11 17 28 2011-01-01 22:00:00 22 5 0.0
23 2011-01-01 23:00:00 1 0 0 2 18.86 22.725 88 19.9995 15 24 39 2011-01-01 23:00:00 23 5 0.0
24 2011-01-02 00:00:00 1 0 0 2 18.86 22.725 88 19.9995 4 13 17 2011-01-02 00:00:00 0 6 1.0
25 2011-01-02 01:00:00 1 0 0 2 18.04 21.970 94 16.9979 1 16 17 2011-01-02 01:00:00 1 6 1.0
26 2011-01-02 02:00:00 1 0 0 2 17.22 21.210 100 19.0012 1 8 9 2011-01-02 02:00:00 2 6 1.0
27 2011-01-02 03:00:00 1 0 0 2 18.86 22.725 94 12.9980 2 4 6 2011-01-02 03:00:00 3 6 1.0
28 2011-01-02 04:00:00 1 0 0 2 18.86 22.725 94 12.9980 2 1 3 2011-01-02 04:00:00 4 6 1.0
29 2011-01-02 06:00:00 1 0 0 3 17.22 21.210 77 19.9995 0 2 2 2011-01-02 06:00:00 6 6 1.0
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
10856 2012-12-18 18:00:00 4 0 1 1 15.58 19.695 46 22.0028 13 512 525 2012-12-18 18:00:00 18 1 717.0
10857 2012-12-18 19:00:00 4 0 1 1 15.58 19.695 46 26.0027 19 334 353 2012-12-18 19:00:00 19 1 717.0
10858 2012-12-18 20:00:00 4 0 1 1 14.76 16.665 50 16.9979 4 264 268 2012-12-18 20:00:00 20 1 717.0
10859 2012-12-18 21:00:00 4 0 1 1 14.76 17.425 50 15.0013 9 159 168 2012-12-18 21:00:00 21 1 717.0
10860 2012-12-18 22:00:00 4 0 1 1 13.94 16.665 49 0.0000 5 127 132 2012-12-18 22:00:00 22 1 717.0
10861 2012-12-18 23:00:00 4 0 1 1 13.94 17.425 49 6.0032 1 80 81 2012-12-18 23:00:00 23 1 717.0
10862 2012-12-19 00:00:00 4 0 1 1 12.30 15.910 61 0.0000 6 35 41 2012-12-19 00:00:00 0 2 718.0
10863 2012-12-19 01:00:00 4 0 1 1 12.30 15.910 65 6.0032 1 14 15 2012-12-19 01:00:00 1 2 718.0
10864 2012-12-19 02:00:00 4 0 1 1 11.48 15.150 65 6.0032 1 2 3 2012-12-19 02:00:00 2 2 718.0
10865 2012-12-19 03:00:00 4 0 1 1 10.66 13.635 75 8.9981 0 5 5 2012-12-19 03:00:00 3 2 718.0
10866 2012-12-19 04:00:00 4 0 1 1 9.84 12.120 75 8.9981 1 6 7 2012-12-19 04:00:00 4 2 718.0
10867 2012-12-19 05:00:00 4 0 1 1 10.66 14.395 75 6.0032 2 29 31 2012-12-19 05:00:00 5 2 718.0
10868 2012-12-19 06:00:00 4 0 1 1 9.84 12.880 75 6.0032 3 109 112 2012-12-19 06:00:00 6 2 718.0
10869 2012-12-19 07:00:00 4 0 1 1 10.66 13.635 75 8.9981 3 360 363 2012-12-19 07:00:00 7 2 718.0
10870 2012-12-19 08:00:00 4 0 1 1 9.84 12.880 87 7.0015 13 665 678 2012-12-19 08:00:00 8 2 718.0
10871 2012-12-19 09:00:00 4 0 1 1 11.48 14.395 75 7.0015 8 309 317 2012-12-19 09:00:00 9 2 718.0
10872 2012-12-19 10:00:00 4 0 1 1 13.12 16.665 70 7.0015 17 147 164 2012-12-19 10:00:00 10 2 718.0
10873 2012-12-19 11:00:00 4 0 1 1 16.40 20.455 54 15.0013 31 169 200 2012-12-19 11:00:00 11 2 718.0
10874 2012-12-19 12:00:00 4 0 1 1 16.40 20.455 54 19.0012 33 203 236 2012-12-19 12:00:00 12 2 718.0
10875 2012-12-19 13:00:00 4 0 1 1 17.22 21.210 50 12.9980 30 183 213 2012-12-19 13:00:00 13 2 718.0
10876 2012-12-19 14:00:00 4 0 1 1 17.22 21.210 50 12.9980 33 185 218 2012-12-19 14:00:00 14 2 718.0
10877 2012-12-19 15:00:00 4 0 1 1 17.22 21.210 50 19.0012 28 209 237 2012-12-19 15:00:00 15 2 718.0
10878 2012-12-19 16:00:00 4 0 1 1 17.22 21.210 50 23.9994 37 297 334 2012-12-19 16:00:00 16 2 718.0
10879 2012-12-19 17:00:00 4 0 1 1 16.40 20.455 50 26.0027 26 536 562 2012-12-19 17:00:00 17 2 718.0
10880 2012-12-19 18:00:00 4 0 1 1 15.58 19.695 50 23.9994 23 546 569 2012-12-19 18:00:00 18 2 718.0
10881 2012-12-19 19:00:00 4 0 1 1 15.58 19.695 50 26.0027 7 329 336 2012-12-19 19:00:00 19 2 718.0
10882 2012-12-19 20:00:00 4 0 1 1 14.76 17.425 57 15.0013 10 231 241 2012-12-19 20:00:00 20 2 718.0
10883 2012-12-19 21:00:00 4 0 1 1 13.94 15.910 61 15.0013 4 164 168 2012-12-19 21:00:00 21 2 718.0
10884 2012-12-19 22:00:00 4 0 1 1 13.94 17.425 61 6.0032 12 117 129 2012-12-19 22:00:00 22 2 718.0
10885 2012-12-19 23:00:00 4 0 1 1 13.12 16.665 66 8.9981 4 84 88 2012-12-19 23:00:00 23 2 718.0
10886 rows × 17 columns
其实我们刚才一直都在猜测,并不知道真实的日期相关的数据分布对吧,所以我们要做一个小小的统计来看看真实的数据分布,我们统计一下一周各天的自行车租赁情况(分注册的人和没注册的人)
In [36]:
byday = data.groupby('dayofweek')
# 统计下没注册的用户租赁情况
byday['casual'].sum().reset_index()
Out[36]:
dayofweek casual
0 0 46288
1 1 35365
2 2 34931
3 3 37283
4 4 47402
5 5 100782
6 6 90084
In [37]:
# 统计下注册的用户的租赁情况
byday['registered'].sum().reset_index()
Out[37]:
dayofweek registered
0 0 249008
1 1 256620
2 2 257295
3 3 269118
4 4 255102
5 5 210736
6 6 195462
周末既然有不同,就单独拿一列出来给星期六,再单独拿一列出来给星期日
In [38]:
data['Saturday']=0
data.Saturday[data.dayofweek==5]=1
data['Sunday']=0
data.Sunday[data.dayofweek==6]=1
data
/opt/conda/envs/python2/lib/python2.7/site-packages/ipykernel/__main__.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
from ipykernel import kernelapp as app
/opt/conda/envs/python2/lib/python2.7/site-packages/ipykernel/__main__.py:5: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
Out[38]:
datetime season holiday workingday weather temp atemp humidity windspeed casual registered count date time hour dayofweek dateDays Saturday Sunday
0 2011-01-01 00:00:00 1 0 0 1 9.84 14.395 81 0.0000 3 13 16 2011-01-01 00:00:00 0 5 0.0 1 0
1 2011-01-01 01:00:00 1 0 0 1 9.02 13.635 80 0.0000 8 32 40 2011-01-01 01:00:00 1 5 0.0 1 0
2 2011-01-01 02:00:00 1 0 0 1 9.02 13.635 80 0.0000 5 27 32 2011-01-01 02:00:00 2 5 0.0 1 0
3 2011-01-01 03:00:00 1 0 0 1 9.84 14.395 75 0.0000 3 10 13 2011-01-01 03:00:00 3 5 0.0 1 0
4 2011-01-01 04:00:00 1 0 0 1 9.84 14.395 75 0.0000 0 1 1 2011-01-01 04:00:00 4 5 0.0 1 0
5 2011-01-01 05:00:00 1 0 0 2 9.84 12.880 75 6.0032 0 1 1 2011-01-01 05:00:00 5 5 0.0 1 0
6 2011-01-01 06:00:00 1 0 0 1 9.02 13.635 80 0.0000 2 0 2 2011-01-01 06:00:00 6 5 0.0 1 0
7 2011-01-01 07:00:00 1 0 0 1 8.20 12.880 86 0.0000 1 2 3 2011-01-01 07:00:00 7 5 0.0 1 0
8 2011-01-01 08:00:00 1 0 0 1 9.84 14.395 75 0.0000 1 7 8 2011-01-01 08:00:00 8 5 0.0 1 0
9 2011-01-01 09:00:00 1 0 0 1 13.12 17.425 76 0.0000 8 6 14 2011-01-01 09:00:00 9 5 0.0 1 0
10 2011-01-01 10:00:00 1 0 0 1 15.58 19.695 76 16.9979 12 24 36 2011-01-01 10:00:00 10 5 0.0 1 0
11 2011-01-01 11:00:00 1 0 0 1 14.76 16.665 81 19.0012 26 30 56 2011-01-01 11:00:00 11 5 0.0 1 0
12 2011-01-01 12:00:00 1 0 0 1 17.22 21.210 77 19.0012 29 55 84 2011-01-01 12:00:00 12 5 0.0 1 0
13 2011-01-01 13:00:00 1 0 0 2 18.86 22.725 72 19.9995 47 47 94 2011-01-01 13:00:00 13 5 0.0 1 0
14 2011-01-01 14:00:00 1 0 0 2 18.86 22.725 72 19.0012 35 71 106 2011-01-01 14:00:00 14 5 0.0 1 0
15 2011-01-01 15:00:00 1 0 0 2 18.04 21.970 77 19.9995 40 70 110 2011-01-01 15:00:00 15 5 0.0 1 0
16 2011-01-01 16:00:00 1 0 0 2 17.22 21.210 82 19.9995 41 52 93 2011-01-01 16:00:00 16 5 0.0 1 0
17 2011-01-01 17:00:00 1 0 0 2 18.04 21.970 82 19.0012 15 52 67 2011-01-01 17:00:00 17 5 0.0 1 0
18 2011-01-01 18:00:00 1 0 0 3 17.22 21.210 88 16.9979 9 26 35 2011-01-01 18:00:00 18 5 0.0 1 0
19 2011-01-01 19:00:00 1 0 0 3 17.22 21.210 88 16.9979 6 31 37 2011-01-01 19:00:00 19 5 0.0 1 0
20 2011-01-01 20:00:00 1 0 0 2 16.40 20.455 87 16.9979 11 25 36 2011-01-01 20:00:00 20 5 0.0 1 0
21 2011-01-01 21:00:00 1 0 0 2 16.40 20.455 87 12.9980 3 31 34 2011-01-01 21:00:00 21 5 0.0 1 0
22 2011-01-01 22:00:00 1 0 0 2 16.40 20.455 94 15.0013 11 17 28 2011-01-01 22:00:00 22 5 0.0 1 0
23 2011-01-01 23:00:00 1 0 0 2 18.86 22.725 88 19.9995 15 24 39 2011-01-01 23:00:00 23 5 0.0 1 0
24 2011-01-02 00:00:00 1 0 0 2 18.86 22.725 88 19.9995 4 13 17 2011-01-02 00:00:00 0 6 1.0 0 1
25 2011-01-02 01:00:00 1 0 0 2 18.04 21.970 94 16.9979 1 16 17 2011-01-02 01:00:00 1 6 1.0 0 1
26 2011-01-02 02:00:00 1 0 0 2 17.22 21.210 100 19.0012 1 8 9 2011-01-02 02:00:00 2 6 1.0 0 1
27 2011-01-02 03:00:00 1 0 0 2 18.86 22.725 94 12.9980 2 4 6 2011-01-02 03:00:00 3 6 1.0 0 1
28 2011-01-02 04:00:00 1 0 0 2 18.86 22.725 94 12.9980 2 1 3 2011-01-02 04:00:00 4 6 1.0 0 1
29 2011-01-02 06:00:00 1 0 0 3 17.22 21.210 77 19.9995 0 2 2 2011-01-02 06:00:00 6 6 1.0 0 1
... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ...
10856 2012-12-18 18:00:00 4 0 1 1 15.58 19.695 46 22.0028 13 512 525 2012-12-18 18:00:00 18 1 717.0 0 0
10857 2012-12-18 19:00:00 4 0 1 1 15.58 19.695 46 26.0027 19 334 353 2012-12-18 19:00:00 19 1 717.0 0 0
10858 2012-12-18 20:00:00 4 0 1 1 14.76 16.665 50 16.9979 4 264 268 2012-12-18 20:00:00 20 1 717.0 0 0
10859 2012-12-18 21:00:00 4 0 1 1 14.76 17.425 50 15.0013 9 159 168 2012-12-18 21:00:00 21 1 717.0 0 0
10860 2012-12-18 22:00:00 4 0 1 1 13.94 16.665 49 0.0000 5 127 132 2012-12-18 22:00:00 22 1 717.0 0 0
10861 2012-12-18 23:00:00 4 0 1 1 13.94 17.425 49 6.0032 1 80 81 2012-12-18 23:00:00 23 1 717.0 0 0
10862 2012-12-19 00:00:00 4 0 1 1 12.30 15.910 61 0.0000 6 35 41 2012-12-19 00:00:00 0 2 718.0 0 0
10863 2012-12-19 01:00:00 4 0 1 1 12.30 15.910 65 6.0032 1 14 15 2012-12-19 01:00:00 1 2 718.0 0 0
10864 2012-12-19 02:00:00 4 0 1 1 11.48 15.150 65 6.0032 1 2 3 2012-12-19 02:00:00 2 2 718.0 0 0
10865 2012-12-19 03:00:00 4 0 1 1 10.66 13.635 75 8.9981 0 5 5 2012-12-19 03:00:00 3 2 718.0 0 0
10866 2012-12-19 04:00:00 4 0 1 1 9.84 12.120 75 8.9981 1 6 7 2012-12-19 04:00:00 4 2 718.0 0 0
10867 2012-12-19 05:00:00 4 0 1 1 10.66 14.395 75 6.0032 2 29 31 2012-12-19 05:00:00 5 2 718.0 0 0
10868 2012-12-19 06:00:00 4 0 1 1 9.84 12.880 75 6.0032 3 109 112 2012-12-19 06:00:00 6 2 718.0 0 0
10869 2012-12-19 07:00:00 4 0 1 1 10.66 13.635 75 8.9981 3 360 363 2012-12-19 07:00:00 7 2 718.0 0 0
10870 2012-12-19 08:00:00 4 0 1 1 9.84 12.880 87 7.0015 13 665 678 2012-12-19 08:00:00 8 2 718.0 0 0
10871 2012-12-19 09:00:00 4 0 1 1 11.48 14.395 75 7.0015 8 309 317 2012-12-19 09:00:00 9 2 718.0 0 0
10872 2012-12-19 10:00:00 4 0 1 1 13.12 16.665 70 7.0015 17 147 164 2012-12-19 10:00:00 10 2 718.0 0 0
10873 2012-12-19 11:00:00 4 0 1 1 16.40 20.455 54 15.0013 31 169 200 2012-12-19 11:00:00 11 2 718.0 0 0
10874 2012-12-19 12:00:00 4 0 1 1 16.40 20.455 54 19.0012 33 203 236 2012-12-19 12:00:00 12 2 718.0 0 0
10875 2012-12-19 13:00:00 4 0 1 1 17.22 21.210 50 12.9980 30 183 213 2012-12-19 13:00:00 13 2 718.0 0 0
10876 2012-12-19 14:00:00 4 0 1 1 17.22 21.210 50 12.9980 33 185 218 2012-12-19 14:00:00 14 2 718.0 0 0
10877 2012-12-19 15:00:00 4 0 1 1 17.22 21.210 50 19.0012 28 209 237 2012-12-19 15:00:00 15 2 718.0 0 0
10878 2012-12-19 16:00:00 4 0 1 1 17.22 21.210 50 23.9994 37 297 334 2012-12-19 16:00:00 16 2 718.0 0 0
10879 2012-12-19 17:00:00 4 0 1 1 16.40 20.455 50 26.0027 26 536 562 2012-12-19 17:00:00 17 2 718.0 0 0
10880 2012-12-19 18:00:00 4 0 1 1 15.58 19.695 50 23.9994 23 546 569 2012-12-19 18:00:00 18 2 718.0 0 0
10881 2012-12-19 19:00:00 4 0 1 1 15.58 19.695 50 26.0027 7 329 336 2012-12-19 19:00:00 19 2 718.0 0 0
10882 2012-12-19 20:00:00 4 0 1 1 14.76 17.425 57 15.0013 10 231 241 2012-12-19 20:00:00 20 2 718.0 0 0
10883 2012-12-19 21:00:00 4 0 1 1 13.94 15.910 61 15.0013 4 164 168 2012-12-19 21:00:00 21 2 718.0 0 0
10884 2012-12-19 22:00:00 4 0 1 1 13.94 17.425 61 6.0032 12 117 129 2012-12-19 22:00:00 22 2 718.0 0 0
10885 2012-12-19 23:00:00 4 0 1 1 13.12 16.665 66 8.9981 4 84 88 2012-12-19 23:00:00 23 2 718.0 0 0
10886 rows × 19 columns
从数据中,把原始的时间字段等踢掉
In [39]:
# remove old data features
dataRel = data.drop(['datetime', 'count','date','time','dayofweek'], axis=1)
dataRel.head()
Out[39]:
season holiday workingday weather temp atemp humidity windspeed casual registered hour dateDays Saturday Sunday
0 1 0 0 1 9.84 14.395 81 0.0 3 13 0 0.0 1 0
1 1 0 0 1 9.02 13.635 80 0.0 8 32 1 0.0 1 0
2 1 0 0 1 9.02 13.635 80 0.0 5 27 2 0.0 1 0
3 1 0 0 1 9.84 14.395 75 0.0 3 10 3 0.0 1 0
4 1 0 0 1 9.84 14.395 75 0.0 0 1 4 0.0 1 0
特征向量化
我们这里打算用scikit-learn来建模。对于pandas的dataframe我们有方法/函数可以直接转成python中的dict。 另外,在这里我们要对离散值和连续值特征区分一下了,以便之后分开做不同的特征处理。
In [40]:
from sklearn.feature_extraction import DictVectorizer
# 我们把连续值的属性放入一个dict中
featureConCols = ['temp','atemp','humidity','windspeed','dateDays','hour']
dataFeatureCon = dataRel[featureConCols]
dataFeatureCon = dataFeatureCon.fillna( 'NA' ) #in case I missed any
X_dictCon = dataFeatureCon.T.to_dict().values()
# 把离散值的属性放到另外一个dict中
featureCatCols = ['season','holiday','workingday','weather','Saturday', 'Sunday']
dataFeatureCat = dataRel[featureCatCols]
dataFeatureCat = dataFeatureCat.fillna( 'NA' ) #in case I missed any
X_dictCat = dataFeatureCat.T.to_dict().values()
# 向量化特征
vec = DictVectorizer(sparse = False)
X_vec_cat = vec.fit_transform(X_dictCat)
X_vec_con = vec.fit_transform(X_dictCon)
In [41]:
dataFeatureCon.head()
Out[41]:
temp atemp humidity windspeed dateDays hour
0 9.84 14.395 81 0.0 0.0 0
1 9.02 13.635 80 0.0 0.0 1
2 9.02 13.635 80 0.0 0.0 2
3 9.84 14.395 75 0.0 0.0 3
4 9.84 14.395 75 0.0 0.0 4
In [42]:
X_vec_con
Out[42]:
array([[ 14.395 , 0. , 0. , 81. , 9.84 , 0. ],
[ 13.635 , 0. , 1. , 80. , 9.02 , 0. ],
[ 13.635 , 0. , 2. , 80. , 9.02 , 0. ],
...,
[ 15.91 , 718. , 21. , 61. , 13.94 , 15.0013],
[ 17.425 , 718. , 22. , 61. , 13.94 , 6.0032],
[ 16.665 , 718. , 23. , 66. , 13.12 , 8.9981]])
In [43]:
dataFeatureCat.head()
Out[43]:
season holiday workingday weather Saturday Sunday
0 1 0 0 1 1 0
1 1 0 0 1 1 0
2 1 0 0 1 1 0
3 1 0 0 1 1 0
4 1 0 0 1 1 0
In [44]:
X_vec_cat
Out[44]:
array([[ 1., 0., 0., 1., 1., 0.],
[ 1., 0., 0., 1., 1., 0.],
[ 1., 0., 0., 1., 1., 0.],
...,
[ 0., 0., 0., 4., 1., 1.],
[ 0., 0., 0., 4., 1., 1.],
[ 0., 0., 0., 4., 1., 1.]])
标准化连续值特征
我们要对连续值属性做一些处理,最基本的当然是标准化,让连续值属性处理过后均值为0,方差为1。 这样的数据放到模型里,对模型训练的收敛和模型的准确性都有好处
In [18]:
from sklearn import preprocessing
# 标准化连续值数据
scaler = preprocessing.StandardScaler().fit(X_vec_con)
X_vec_con = scaler.transform(X_vec_con)
X_vec_con
Out[18]:
array([[-1.09273697, -1.70912256, -1.66894356, 0.99321305, -1.33366069,
-1.56775367],
[-1.18242083, -1.70912256, -1.52434128, 0.94124921, -1.43890721,
-1.56775367],
[-1.18242083, -1.70912256, -1.379739 , 0.94124921, -1.43890721,
-1.56775367],
...,
[-0.91395927, 1.70183906, 1.36770431, -0.04606385, -0.80742813,
0.26970368],
[-0.73518157, 1.70183906, 1.51230659, -0.04606385, -0.80742813,
-0.83244247],
[-0.82486544, 1.70183906, 1.65690887, 0.21375537, -0.91267464,
-0.46560752]])
类别特征编码
最常用的当然是one-hot编码咯,比如颜色 红、蓝、黄 会被编码为[1, 0, 0],[0, 1, 0],[0, 0, 1]
In [20]:
from sklearn import preprocessing
# one-hot编码
enc = preprocessing.OneHotEncoder()
enc.fit(X_vec_cat)
X_vec_cat = enc.transform(X_vec_cat).toarray()
X_vec_cat
Out[20]:
array([[ 1., 0., 0., ..., 1., 1., 0.],
[ 1., 0., 0., ..., 1., 1., 0.],
[ 1., 0., 0., ..., 1., 1., 0.],
...,
[ 0., 1., 1., ..., 0., 0., 1.],
[ 0., 1., 1., ..., 0., 0., 1.],
[ 0., 1., 1., ..., 0., 0., 1.]])
把特征拼一起
把离散和连续的特征都组合在一起
In [22]:
import numpy as np
# combine cat & con features
X_vec = np.concatenate((X_vec_con,X_vec_cat), axis=1)
X_vec
Out[22]:
array([[-1.09273697, -1.70912256, -1.66894356, ..., 1. ,
1. , 0. ],
[-1.18242083, -1.70912256, -1.52434128, ..., 1. ,
1. , 0. ],
[-1.18242083, -1.70912256, -1.379739 , ..., 1. ,
1. , 0. ],
...,
[-0.91395927, 1.70183906, 1.36770431, ..., 0. ,
0. , 1. ],
[-0.73518157, 1.70183906, 1.51230659, ..., 0. ,
0. , 1. ],
[-0.82486544, 1.70183906, 1.65690887, ..., 0. ,
0. , 1. ]])
最后的特征,前6列是标准化过后的连续值特征,后面是编码后的离散值特征
对结果值也处理一下
拿到结果的浮点数值
In [23]:
# 对Y向量化
Y_vec_reg = dataRel['registered'].values.astype(float)
Y_vec_cas = dataRel['casual'].values.astype(float)
In [24]:
Y_vec_reg
Out[24]:
array([ 13., 32., 27., ..., 164., 117., 84.])
In [25]:
Y_vec_cas
Out[25]:
array([ 3., 8., 5., ..., 4., 12., 4.])
