
异常点检测
异常点检测算法(一)
1.基于正态分布的一元离群点检测方法
在正态分布的假设下,区域 包含了99.7% 的数据,如果某个值距离分布的均值
超过了
,那么这个值就可以被简单的标记为一个异常点(outlier)。
2. 多元离群点的检测方法
(1)基于一元正态分布的离群点检测方法
在正态分布的假设下,如果有一个新的数据 ,可以计算概率
如下:
根据概率值的大小就可以判断 x 是否属于异常值。
(2)多元高斯分布的异常点检测
(3)使用 Mahalanobis 距离检测多元离群点
(4)使用  统计量检测多元离群点
统计量检测多元离群点
异常值检测算法(二)
(一)主成分分析(Principle Component Analysis)
在主成分分析(PCA)这种降维方法中,数据从原来的坐标系转换到新的坐标系,新坐标系的选择是由数据集本身所决定的。第一个新坐标轴的方向选择的是原始数据集中方差最大的方向,第二个新坐标轴的选择是和第一个坐标轴正交并且具有最大方差的方向。该过程一直重复,重复的次数就是原始数据中特征的数目。如此操作下去,将会发现,大部分方差都包含在最前面的几个新坐标轴之中。因此,我们可以忽略余下的坐标轴,也就是对数据进行了降维的处理。
(二)基于矩阵分解的异常点检测方法
基于矩阵分解的异常点检测方法的关键思想是利用主成分分析去寻找那些违背了数据之间相关性的异常点。为了发现这些异常点,基于主成分分析(PCA)的算法会把原始数据从原始的空间投影到主成分空间,然后再把投影拉回到原始的空间。如果只使用第一主成分来进行投影和重构,对于大多数的数据而言,重构之后的误差是小的;但是对于异常点而言,重构之后的误差依然相对大。这是因为第一主成分反映了正常值的方差,最后一个主成分反映了异常点的方差。
异常点检测算法(三)
RNN 算法( Replicator Neural Networks)
又叫自编码器,是一个多层前馈的神经网络 (multi-layer feed-forward neural networks)。在 Replicator Neural Networks 中,输入的变量也是输出的变量,模型中间层节点的个数少于输入层和输出层节点的个数。这样的话,模型就起到了压缩数据和恢复数据的作用。
训练的目标就是使得整体的输出误差足够小,整体的误差是由所有的样本误差之和除以样本的个数得到的。
如果使用已经训练好的 RNN 模型,异常值的分数就可以定义为重构误差(reconstruction error)。
BP 算法的目的是最小化训练集上的累计误差 其中 m 是训练集合中样本的个数。不过,标准的 BP 算法每次仅针对一个训练样例更新连接权重和阈值,也就是说,标准 BP 算法的更新规则是基于单个的
推导而得到的。通过类似的计算方法可以推导出累计误差的最小化更新规则,那就得到了累计误差逆传播(accumulate error backpropagation)算法。标准 BP 算法需要进行更多次的迭代,并且参数的更新速度快,累积 BP 算法必须扫描一次训练集合才会进行一次参数的更新,而且累计误差下降到一定的程度以后 ,进一步下降就会明显变慢,此时标准 BP 算法往往会更快的得到较好的解,尤其是训练集合大的时候。
训练方法:
(1)把数据集合的每一列都进行归一化;
(2)选择 70% 的数据集合作为训练集合,30% 的数据集合作为验证集合。或者 训练集合 : 验证集合 = 8 : 2,这个需要根据情况而定。
(3)随机生成一个三层的神经网络结构,里面的权重都是随机生成,范围在 [0,1] 内。输入层的数据和输出层的数据保持一致,并且神经网络中间层的节点个数是输入层的一半。
(4)使用后向传播算法(back-propagation)来训练模型。为了防止神经网络的过拟合,通常有两种策略来防止这个问题。(i)第一种策略是“早停”(early stopping):当训练集合的误差降低,但是验证集合的误差增加时,则停止训练,同时返回具有最小验证集合误差的神经网络;(ii)第二种策略是“正则化”(regularization):基本思想是在误差目标函数中增加一个用于描述网络复杂度的部分,例如链接权和阀值的平方和。
参考文献:
[1] Anomaly Detection Using Replicator Neural Networks Trained on Examples of One Class, Hoang Anh Dau, Vic Ciesielski, Andy Song
[2] Replicator Neural Networks for Outlier Modeling in Segmental Speech Recognition, Laszlo Toth and Gabor Gosztolya
[3] Outlier Detection Using Replicator Neural Networks, Simon Hawkins, Honxing He, Graham Williams and Rohan Baxter
异常点检测算法综述
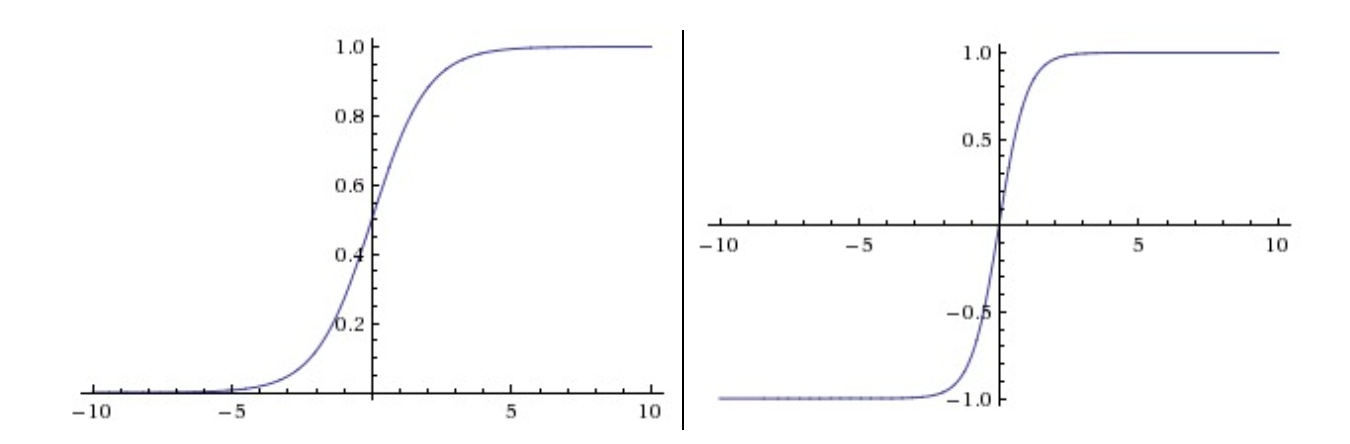
每个激活函数(或非线性函数)的输入都是一个数字,然后对其进行某种固定的数学操作。下面是在实践中可能遇到的几种激活函数:左边是Sigmoid非线性函数,将实数压缩到[0,1]之间。右边是tanh函数,将实数压缩到[-1,1]。
Sigmoid非线性函数 的公式为: 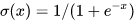
tanh函数的输出是零中心的。因此,在实际操作中,tanh非线性函数比sigmoid非线性函数更受欢迎。注意tanh神经元是一个简单放大的sigmoid神经元,具体说来就是:。
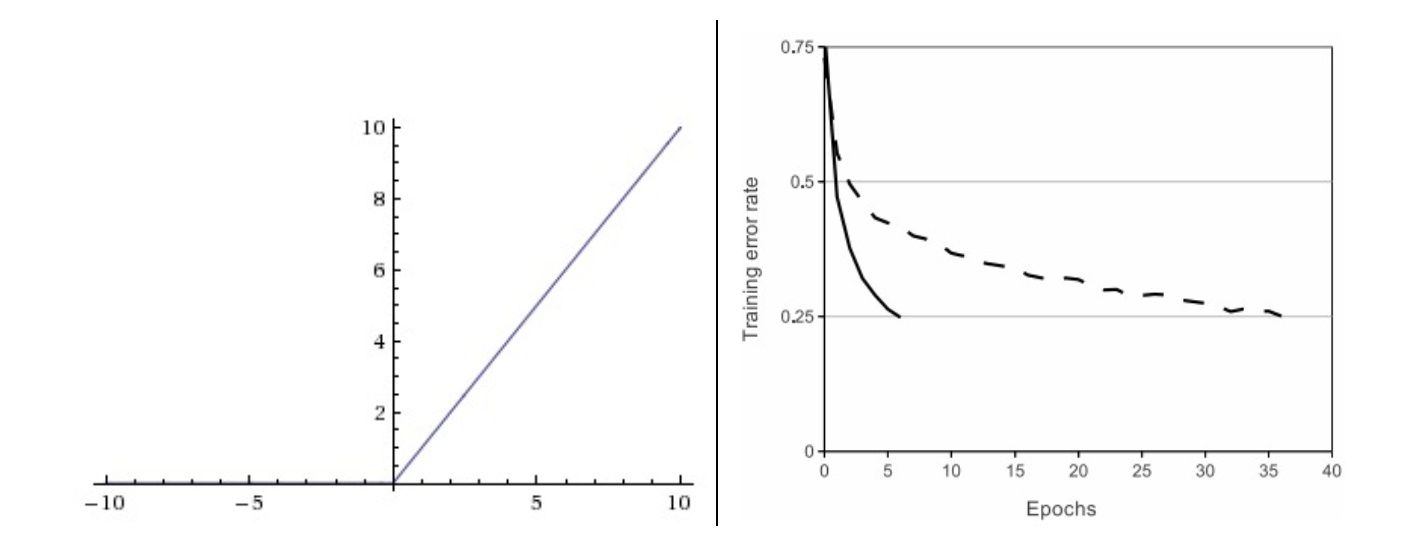
左边是ReLU(校正线性单元:Rectified Linear Unit)激活函数,当时函数值为0。当
函数的斜率为1。右边是从 Krizhevsky等的论文中截取的图表,指明使用ReLU比使用tanh的收敛快6倍。
ReLU。在近些年ReLU变得非常流行。它的函数公式是。换句话说,这个激活函数就是一个关于0的阈值(如上图左侧)。使用ReLU有以下一些优缺点:
- 优点:相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用(Krizhevsky 等的论文指出有6倍之多)。据称这是由它的线性,非饱和的公式导致的。
- 优点:sigmoid和tanh神经元含有指数运算等耗费计算资源的操作,而ReLU可以简单地通过对一个矩阵进行阈值计算得到。
- 缺点:在训练的时候,ReLU单元比较脆弱并且可能“死掉”。举例来说,当一个很大的梯度流过ReLU的神经元的时候,可能会导致梯度更新到一种特别的状态,在这种状态下神经元将无法被其他任何数据点再次激活。如果这种情况发生,那么从此所以流过这个神经元的梯度将都变成0。也就是说,这个ReLU单元在训练中将不可逆转的死亡,因为这导致了数据多样化的丢失。例如,如果学习率设置得太高,可能会发现网络中40%的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。通过合理设置学习率,这种情况的发生概率会降低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号