
Python序列
2020-03-01 18:26 鲁尧尧 阅读(1055) 评论(0) 编辑 收藏 举报所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的索引访问它们。为了更形象的认识序列,可以将它看做是一家旅店,那么店中的每个房间就如同序列存储数据的一个个内存空间,每个房间所特有的房间号就相当于索引值。也就是说,通过房间号(索引)我们可以找到这家旅店(序列)中的每个房间(内存空间)。在Python 中,序列类型包括字符串、列表、元组、集合和字典。
(1)通用操作
Python提供了几个内置函数,可用于实现与序列相关的一些常用操作。如表所示
|
函 数 |
作 用 |
|
len() |
计算序列的长度,即返回序列中包含多少个元素。 |
|
max() |
找出序列中的最大元素。 |
|
min() |
找出序列中的最小元素。 |
|
list() |
将序列转换为列表。 |
|
str() |
将序列转换为字符串。 |
|
sum() |
计算元素和。 |
|
sorted() |
对元素进行排序。 |
|
reversed() |
反向序列中的元素。 |
注意:max()、min()与sum()都需要序列内元素为数字类型,若出现字符串等类型将提示错误。通用操作示例如下:
#列表a a=[1,2,3,6,5,4] #输出列表a的数据类型 #输出结果<class 'list'> print(type(a)) #输出列表a的长度 #输出结果6 print(len(a)) #输出列表a的最大值 #输出结果6 print(max(a)) #输出列表a的最小值 #输出结果1 print(min(a)) #输出列表a的所有元素和 #输出结果21 print(sum(a)) #输出列表a #输出结果[1, 2, 3, 6, 5, 4] print(a) #输出列表a排序结果 #输出结果[1, 2, 3, 4, 5, 6] print(sorted(a)) #输出列表a转化成字符串类型 #输出结果<class 'str'> print(type(str(a)))
(1)列表(list)
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。列表的数据项不需要具有相同的类型创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
#空数据 list_a=[] #以数字为元素 list_b=[1,2,3] #以字符为元素 list_c=["a","b","c"] #多种数据类型混合 list_d=[1,2,"a","b",{},list_a] #通过list函数来创建列表 list_e=list()
集合常见的访问方式一为通过下标(索引)访问,列表的元素以0开始按顺序排放安置,可直接通过下标来访问列表,格式为:list_name[i]。另一方法为切片方式访问,方法为:list_name[start : end : step],其中start为起始下标、end为终止下标、step为步长。
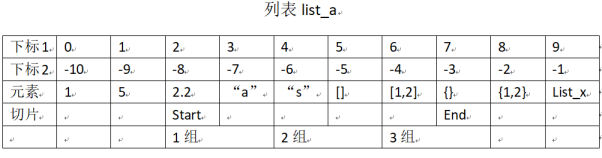
举例说明如下图所示:

上图所示为列表随意创建列表list_a的示意图,访问下标有两种情况,一种为正序访问,此时下标为从零开始到列表结束,另一种为倒序访问,以列表最后一个元素为-1开始,到列表第一个元素为止。良好总下标访问结果是等效的,比如说访问元素“a”,可以采用list_[3]与list_a[-7]是等效的。另外由于列表元素可以为其他序列,比如[1,2]就是以一个列表作为元素,若访问元素列表中的元素就需要在原有的基础上再次访问,格式为:list_name[i][j]。
列表另一种方法切片访问,原理为选取从开头下标到结尾下标中步长为单位的元素作为一个整体来提取。以从元素2到元素7步长为2来简单理解这一过程,首先找到下标为2的元素,然后开始截取直到下标7的元素截止,步长为2则以两个元素作为一组,然后以每一组元素的第一个为整体输出。例子中下标2为2.2、下标7为元素{}期间共有6个元素,以2个元素为一组的方式可以分为三组,然后每一组的第一个作为一个整体,访问如下所示:
list_x=[] list_a=[1,5,2.2,"a","s",[],[1,2],{},{1,2},list_x] print(list_a[2:7:2]) #运行结果: [2.2, 's', [1, 2]]
示意图如下图2.5所示:
列表的操作函数如下表所示:
|
功能 |
函数 |
描述 |
|
添加元素 |
list_name.append(obj) |
obj表示添加到列表末尾的数据,它可以是单个元素,也可以是列表、元组等。 |
|
list_name.extend(obj) |
obj表示添加到列表末尾的数据, |
|
|
list_name.insert(index,obj) |
index表示插入位置,obj表示添加元素,可以指定添加位置的函数。 |
|
|
删除元素 |
list_name.pop(index) |
index表示删除元素位置,函数可以删除指定位置的元素,之后的元素将会补充到删除的位置。 |
|
list_name.remove(obj) |
obj表示删除元素的值必须保证该元素是存在的,否则会引发 ValueError 错误。 |
|
|
list_name.clear() |
删除列表的所有元素,也即清空列表, |
|
|
查找元素 |
list_name.index(obj,start, end) |
ndex() 方法用来查找某个元素在列表中出现的位置(也就是索引),如果该元素不存在,则会导致 ValueError 错误。 |
|
list_name.count(obj) |
count()方法用来统计某个元素在列表中出现的次数 |
添加元素就是在指定位置添加指定元素,位置一般默认为最后一位,若需要强调位置则需要使用insert()函数。末尾添加元素的两个函数一定程度上是等效的,两者的区别主要体现在添加元素为序列的时候,append()函数添加序列是将序列作为一整个元素添加到列表末尾,而extend()函数则是将序列拆开,将序列的元素拼接进去,3种添加方式实例如下:
list_add=[1,2,3] #显示结果:[1, 2, 3] print(list_add) list_add.append([1,2]) #显示结果:[1, 2, 3, [1, 2]] print(list_add) list_add.extend([1,2]) #显示结果:[1, 2, 3, [1, 2], 1, 2] print(list_add) list_add.insert(2,"a") #显示结果:[1, 2, 'a', 3, [1, 2], 1, 2] print(list_add)
删除元素除了列表中的3中函数外还可以使用关键词del,使用方法为:del list_name[i],而且通过关键字删除可以和访问一样,可以通过切片方式删除实例如下所示:
list_delate=[0,1,2,3,4,5,6] #操作为:显示列表 #输出结果:[0, 1, 2, 3, 4, 5, 6] print(list_delate) #操作为:删除列表中下标为1的元素 #输出结果:[0, 2, 3, 4, 5, 6] del list_delate[1] print(list_delate) #操作为:删除下标为0到2的元素 #输出结果:[3, 4, 5, 6] del list_delate[0:2] print(list_delate) #操作为:删除下标为3的元素 #输出结果:[3, 4, 5] list_delate.pop(3) print(list_delate) #操作为:删除值等于3的元素 #输出结果:[4, 5] list_delate.remove(3) print(list_delate) #操作为:清空列表 #输出结果:[] list_delate.clear() print(list_delate)
修改列表操作为对原有列表进行再赋值操作,先访问数据然后再重新赋值即可,示例如下:
list_change=[0,1,2,3,4] #显示结果:[0, 1, 2, 3, 4] print(list_change) #修改下标为3的元素,值为5 list_change[3]=5 #显示结果:[0, 1, 2, 5, 4] print(list_change)
查找列表元素方法,index()为查找指定内容的索引,也就是提供该元素的下标,当一个列表中出现多个相同的元素,则只返回第一个元素的下标,若未有指定元素则报错。而count()函数则是查询指定元素在列表中出现次数。所以一般两个函数一起用。示例如下:
list_find=[1,2,3,4,1] #列表中有2个元素1,返回结果 print(list_find.count(1)) #列表中第一个元素1在下标为0的位置上,返回结果为0 print(list_find.index(1))
(2)元组(typle)
元组(tuple)是 Python 中另一个重要的序列结构,和列表类似,元组也是由一系列按特定顺序排序的元素组成。元组和列表的不同之处在于操作上,列表是可变的、可以进行添加修改等操作的,而元组元组是不可变序列,一旦被创建元素就不可更改了。从存储内容上看,元组可以存储整数、实数、字符串、列表、元组等任何类型的数据,并且在同一个元组中,元素的类型可以不同。
元组的创建为小括号(()),元素以逗号(,)作为分隔。也可以使用函数tuple()来创建,示例如下:
tuple_a=(1,2,3,4) tuple_b=("a","b,","c") tuple_c=(1,2,"a",[],()) tuple_d=tuple() tuple_e=("abcde") print(type(tuple_e)) tuple_f=("abcde",) print(type(tuple_f)) #运行结果 <class 'str'> <class 'tuple'>
这里注意,创建元组tuple_e的时候发现当元组只含有一个元素,而且元素为字符串的时候,创建方式与创建字符串变量时相同,所以为了方便区分,在之后加一个逗号以表元组类型的意思,如tuple_f的形式。
元组的访问同列表所示,通过下标访问和奇瑞片访问,格式:tuple_nam[i]与tuple_nam[start,end,step]。
元组属于不可变序列,所以一旦需要变动,思路就是创建新的元组,接收旧的元组和需要改动的变化。而元组的删除则通过关键词del。
(3)字典(dict)
列表中查找是通过整数的索引(元素在列表中的序号)来实现查找功能。但很多应用程序需要更加灵活的查找方式,即表示索引的键和对应的值组成。比如说:通过“用户名”查找“手机号”,通过“学号”查找“学院班级”等等。通过任意键信息查找一组数据中值信息的过程叫“映射”,在Python语言中,通过字典来实现映射。字典(dict)是一种无序的、可变的序列,它的元素以“键值对(key-value)”的形式存储。简单理解为,字典为处理信息与信息相对应映射关系的组合数据类型。
列表、元组通常会将索引值0对应的元素称为第一个元素,而字典中的元素是无序的。字典中,不支持同一个键出现多次,否则只会保留最后一个键值对。注意字典中的值是不可变的,只能使用数字、字符串或者元组,不能使用列表。
字典类型的创建由于字典中每个元素都包含两部分,分别是键(key)和值(value),因此在创建字典时,键和值之间使用冒号(:)分隔,相邻元素之间使用逗号(,)分隔,所有元素放在大括号{}中。同样也可以使用指定函数fromkeys()来创建,使用方法为:dictname = dict.fromkeys(list,value=None),其中,list 参数表示字典中所有键的列表(list);value 参数表示默认值,如果不写则为空值None。或者采用函数dict()函数创建字典。以下三种创建方式是等效的。创建代码如下所示:
dict_a={"a":1,"b":1}
print(dict_a)
key_b=["a","b"]
dict_b=dict.fromkeys(key_b,1)
print(dict_b)
key_c=["a","b"]
value_c=[1,1]
dict_c=dict(zip(key_c,value_c))
print(dict_c)
字典访问如同其他序列一样,可以通过下标来访问,但是注意下标并非是数字而是键,格式:dict_name[key],dictname 表示字典变量的名字,key 表示键名。注意,键必须是存在的,否则会抛出异常。除了上面这种方式外,Python 更推荐使用dict类型提供的get()方法来获取指定键对应的值。当指定的键不存在时,get() 方法不会抛出异常。get() 方法的语法格式为:dict_name.get(key[,default])其中,key 表示指定的键;default用于指定要查询的键不存在时,此方法返回的默认值,默认会返回None。示例如下:
dict_a={"a":1,"b":1}
print(dict_a["a"])
print(dict_a.get("b"))
字典类型进行添加过程为对元素进行赋值,格式:dict_name[key] = value,实例如下:
d={"中国":"北京","美国":"华盛顿"}
d["法国"]="巴黎"
print(d)
#结果:{'中国': '北京', '美国': '华盛顿', '法国': '巴黎'}
这里需要注意一点,字典和集合都具有无序性,所以返回结果可能和输入顺序有所差别,字典类型主要结构为 :键对应值,所以只要做到键值对一一对应即可。
字典的修改与添加操作无异,访问对象直接修改。列举字典常见操作如表所示:
|
函 数 |
作 用 |
|
keys() |
函数作用为返回所有“键”信息 |
|
values() |
与keys()函数作用相似,作用为返回字典的值信息 |
|
items() |
作用为返回字典所有的键值对 |
|
get(<key>,<default>) |
返回指定键或者值 |
|
pop(<key>,<default>) |
判断键是否有对应的值,有则删除 |
|
popitem() |
随机从字典中选取一个键值对,删除 |
|
clear() |
作用为删除所有的键值对,也就是清空字典内部所有数据 |
|
del<d>[<key>] |
操作为传入键,删除对应的键值对. |
|
<key>in<d> |
属于判断函数,若键在字典中为则返回true 否则返回false |
|
copy() |
返回一个字典的拷贝,也即返回一个具有相同键值对的新字典 |
|
update() |
可以使用一个字典所包含的键值对来更新己有的字典 |
注意:1.items()与直接打印字典有所不同,items()返回以键值对为单位的原则,而字典则为呈现。2.get()与pop()函数不同体现在是否存在键值对,若指定键值对存在get()函数将会返回而pop()函数将会删除,若无对应键值对则报错返回异常。3.注意,copy()方法所遵循的拷贝原理,字典采用深拷贝而列表等所使用的为浅拷贝4.在执行 update() 方法时,如果被更新的字典中己包含对应的键值对,那么原 value 会被覆盖;如果被更新的字典中不包含对应的键值对,则该键值对被添加进去。5.其实,说 popitem() 随机删除字典中的一个键值对是不准确的,虽然字典是一种无须的列表,但键值对在底层也是有存储顺序的,popitem() 总是弹出底层中的最后一个 key-value,这和列表的 pop() 方法类似,都实现了数据结构中“出栈”的操作。
实战演练效果、代码如下所示:
#创建字典a dict_a={"中国":"北京","美国":"华盛顿"} #添加新元素 dict_a["法国"]="巴黎" #操作:显示字典a的键 #显示结果:dict_keys(['中国', '美国', '法国']) print(dict_a.keys()) #操作:显示字典a的值 #显示结果:dict_values(['北京', '华盛顿', '巴黎']) print(dict_a.values()) ##操作:显示字典a的键值对 #显示结果1:dict_items([('中国', '北京'), ('美国', '华盛顿'), ('法国', '巴黎')]) #显示结果2:{'中国': '北京', '美国': '华盛顿', '法国': '巴黎'} print(dict_a.items()) print(dict_a) #操作:显示字典a中法国对应的值 #显示结果1:巴黎 print(dict_a.get("法国")) ##操作:显示字典a中法国对应的值并删除 #显示结果1:巴黎 #显示结果2:{'中国': '北京', '美国': '华盛顿'} print(dict_a.pop("法国")) print(dict_a) ##操作:拷贝字典a #显示结果:{'中国': '北京', '美国': '华盛顿'} dict_b=dict_a.copy() print(dict_b) ##操作:删除美国的键值对 #显示结果:{'中国': '北京'} del dict_a["美国"] print(dict_a) ##操作:清空字典a #显示结果:None print(dict_a.clear())
(4)集合(set)
Python 中的集合,和数学中的集合概念一样,用来保存不重复的元素,即集合中的元素都是唯一的,互不相同。从形式上看和字典类似,从内容上看,同一集合中只能存储不可变的数据类型,包括整形、浮点型、字符串、元组,无法存储列表、字典、集合这些可变的数据类型,否则 Python 解释器会抛出 TypeError 错误。
Python的创建集合方式为将所有元素放在一对大括号({})中,相邻元素之间用(,)分隔。另一种方式则是通过内置函数set(),set()函数为Python的内置函数,其功能是将字符串、列表、元组、range 对象等可迭代对象转换成集合。由于集合与字典均为无序,而集合不像是字典一样有键值对,所以访问只能通过循环来遍历。
集合常见操作如下所示
|
函 数 |
作 用 |
|
setname.add(element) |
向集合中添加元素 |
|
setname.remove(element) |
删除集合中的元素 |
|
& |
交集、取两个集合的共有元素 |
|
| |
并集、取两集合全部的元素 |
|
- |
差、取一个集合中另一集合没有的元素 |
|
^ |
对称差集、取集合 A 和 B 中不属于 A&B 的元素 |
|
setname.copy() |
复制 |
示例如下:
set_1={1,2,3,4}
set_2={1,3,5,7}
#操作:向集合1中添加元素x
#结果:{1, 2, 3, 4, 'x'}
set_1.add("x")
print(set_1)
#操作:向集合2中删除元素7
#结果:{1, 3, 5}
set_2.remove(7)
print(set_2)
#操作:显示集合1与集合2的交集
#结果:{1, 3}
print(set_1&set_2)
#操作:显示集合1与集合2的并集
#结果:{1, 2, 3, 4, 5, 'x'}
print(set_1|set_2)
#操作:显示集合1与集合2的差
#结果:{2, 4, 'x'}
print(set_1-set_2)
#操作:显示集合1与集合2的对称差集
#结果:{2, 4, 5, 'x'}
print(set_1^set_2)
#操作:复制拷贝集合1
#结果:{1, 2, 3, 4, 'x'}
set_3=set_1.copy()
print(set_3)
