Python基础库之jieba库的使用(第三方中文词汇函数库)
2019-10-06 16:52 鲁尧尧 阅读(2791) 评论(1) 收藏 举报各位学python的朋友,是否也曾遇到过这样的问题,举个例子如下:
“I am proud of my motherland”
如果我们需要提取中间的单词要走如何做?
自然是调用string中的split()函数即可

那么将这转换成中文呢,“我为我的祖国感到骄傲”再分词会怎样?
中国词汇并不像是英文文本那样可以通过空格又或是标点符号来区分,
这将会导致比如“骄傲”拆开成“骄”、“傲”,又或者将“为”“我的”组合成“为我的”等等
那如何避免这些问题呢? 这就用到了今天介绍的python基础库——jieba库
一、什么是jieba库?
jieba库是优秀的中文分词第三方库 ,它可以利用一个中文词库,确定汉字之间的关联概率,
将汉字间概率大的组成词组,形成分词结果,将中文文本通过分词获得单个的词语。
jieba分词的三种模式 :精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
二、安装jieba库
安装jieba库还是比较简单的,我介绍几种简单的方法
1.全自动安装
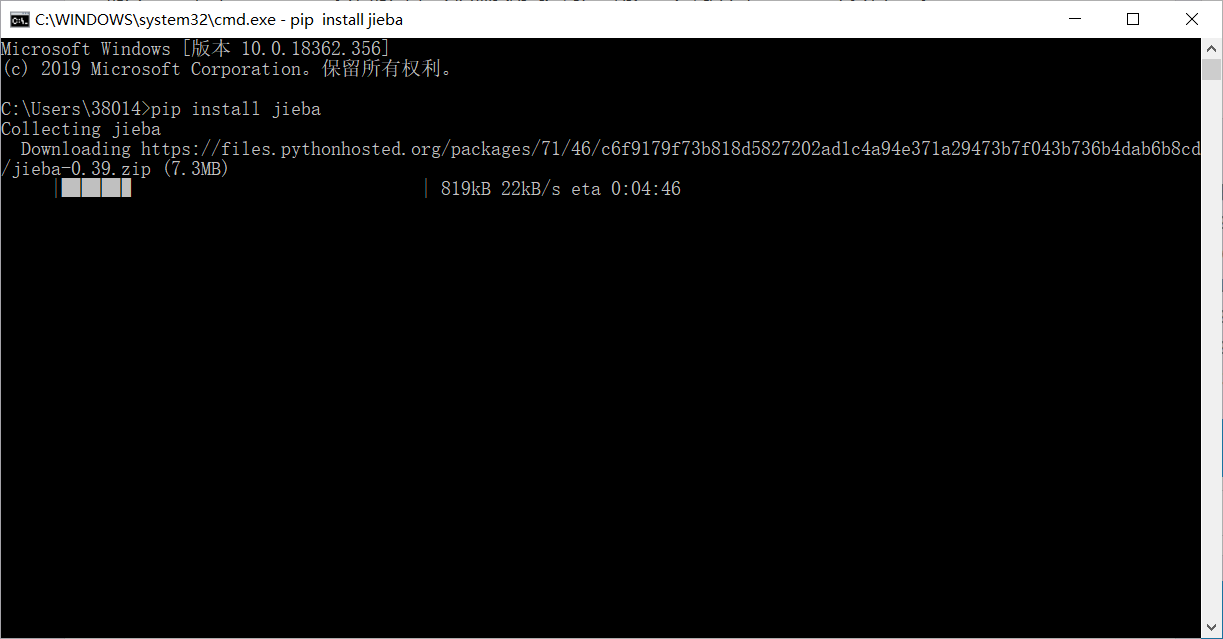
打开cmd命令提示符然后输入代码
easy_install jieba
pip install jieba
pip3 install jieba
三段代码任意一个即可自动下载安装
2.半自动安装
首先打开jieba库网站:http://pypi.python.org/pypi/jieba/
然后下载并运行python setup.py install
最后将 jieba 目录放置于当前目录或者 site-packages 目录

3.软件安装
许多编辑软件都可以在软件内部安装,以pycharm2019为例子
首先打开pycharm,在左上角文件中可以找到设置,然后打开设置
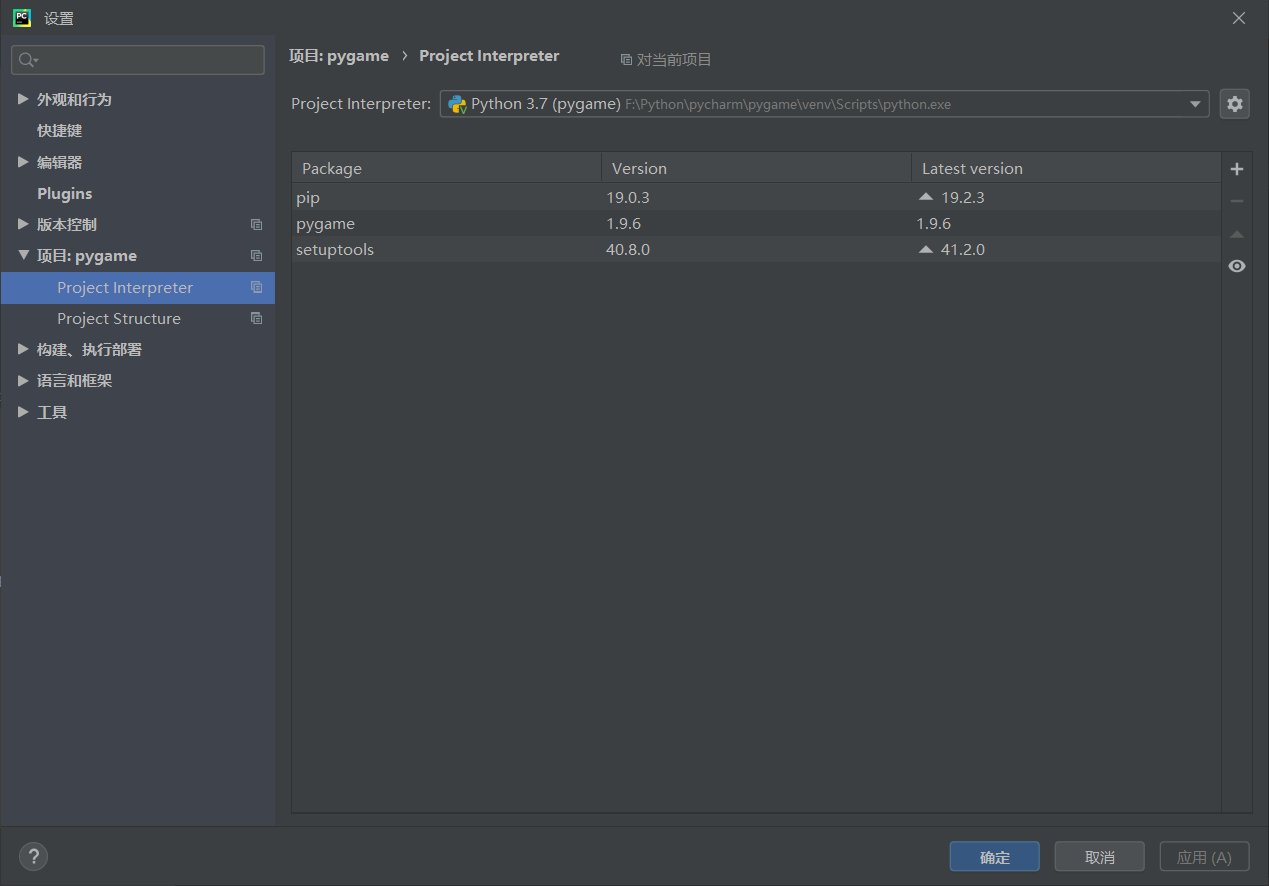
右侧项目相关可以找到 project interpreter,进入可以查看项目引用的模块
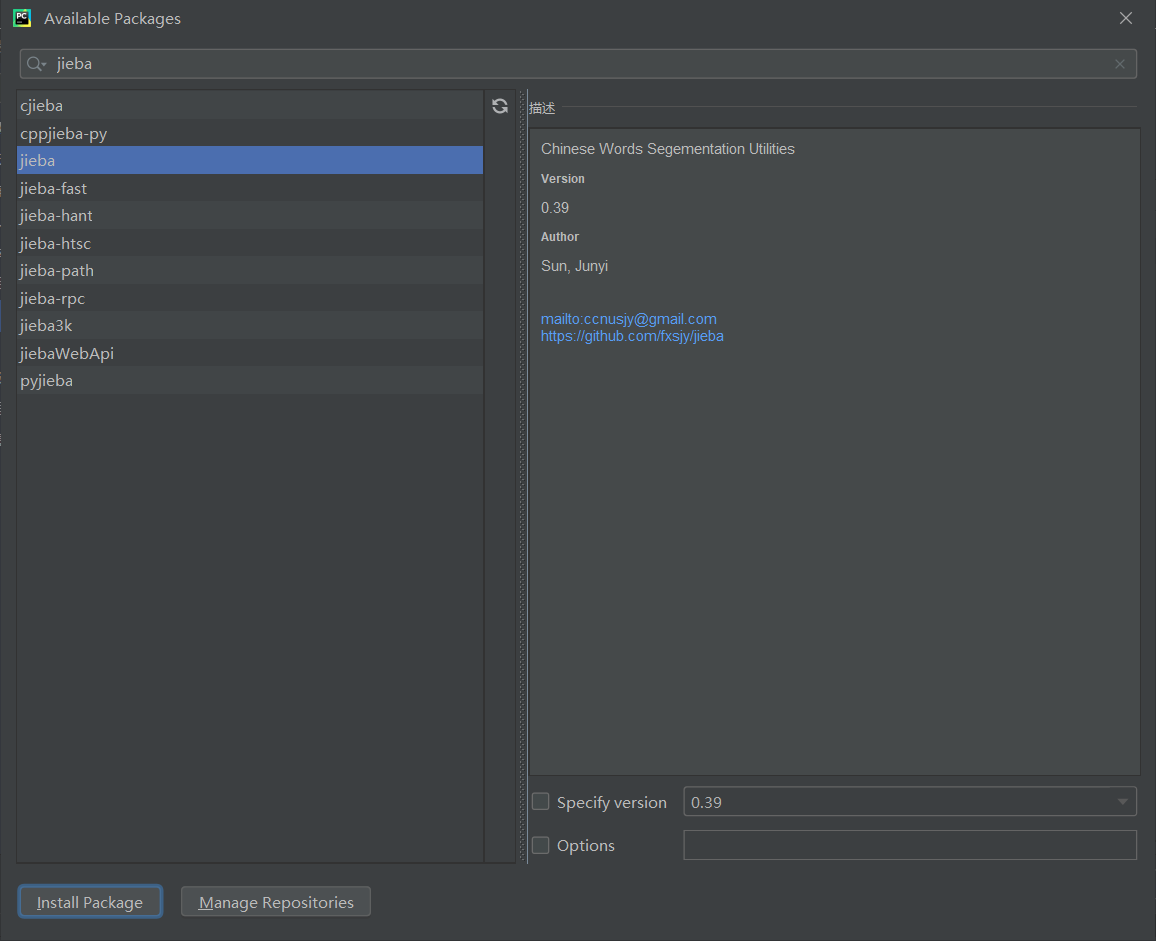
点击右侧的加号,在available packages 中搜索jieba 选中后点击左下角安装即可
4.检测安装
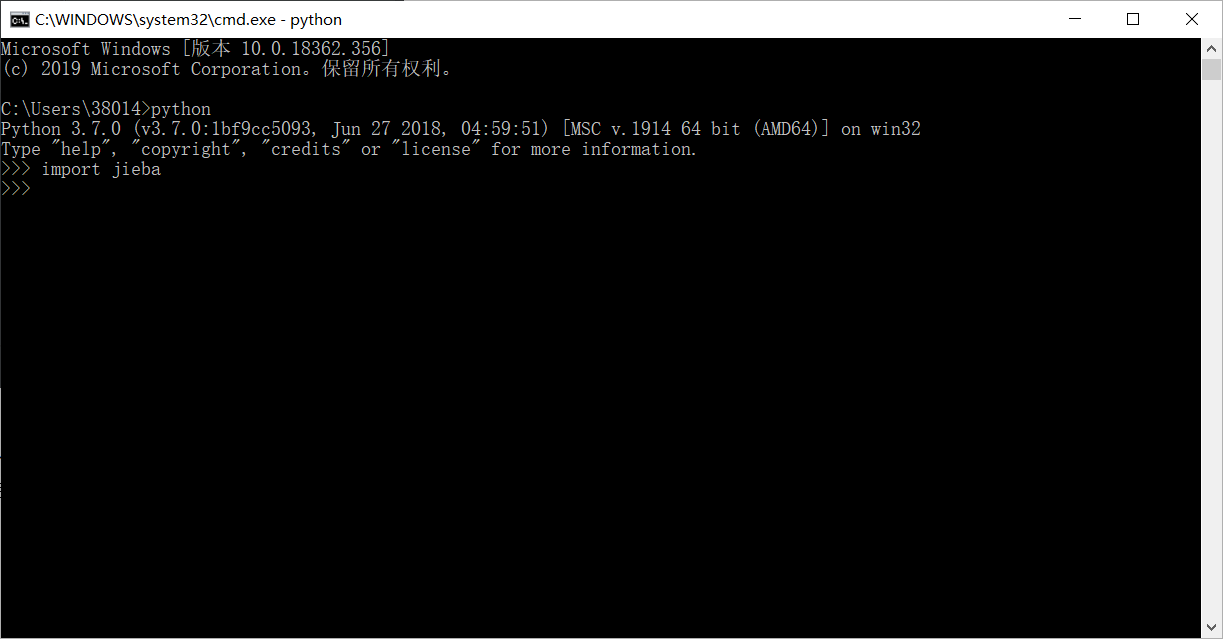
打开命令提示符(cmd)进入python环境
输入import jieba 如下图所示即为安装成功
三、主要函数
jieba.cut(s)
被运用于精确模式,将会返回一个可迭代的数据类型
jieba.cut(s,cut_all=True)
被运用于全模式,输出文本s中的所有可能单词
jieba.cut_for_search(s)
搜索引擎模式,适合搜索引擎建立索引的分词结果
jieba.lcut(s)
被运用于精确模式,将会返回一个列表类型
jieba.lcut(s,cut_all=True)
被运用于全模式,返回一个列表类型
jieba.lcut_for_search(s)
搜索引擎模式,返回一个列表类型
jieba.add_word(w)
向分词词典加入新词
相信不少同学已经看得有点蒙,那么接下来我将通过代码来实际对比不同点
首先我们对比三个不同的模式 ,之前的介绍可以看出:
精确模式将不会出现冗余,所有词汇都是根据最大可能性而进行组合的出结果
全模式与精确模式最大区别在于,全模式将会把所有可能拼接的词汇全部展现
搜索引擎模式则是在精确模式的前提下对较长词汇进行再一次分割
我们以“我因自己是中华人民共和国的一份子而感到骄傲”为例
*精确模式结果如下 :

['我', '因', '自己', '是', '中华人民共和国', '的', '一份', '子', '而', '感到', '骄傲']
*全模式结果如下:

['我', '因', '自己', '是', '中华', '中华人民', '中华人民共和国', '华人', '人民', '人民共和国', '共和', '共和国', '的', '一份', '份子', '而', '感到', '骄傲']
*搜索引擎模式结果如下:

['我', '因', '自己', '是', '中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '的', '一份', '子', '而', '感到', '骄傲']
可以很明显的对比出来,全模式将所有课能出现的词汇进行罗列,而搜索引擎模式与精确模式十分相似,但对“中华人名共和国“”这一词汇进行分词
至于有的同学发现有些函数十分相似,比如说cut()与lcut()
两者之间其实差距不大,主要不同在于返回类型,加“l”的一般返回为列表类型。
如果觉得有所帮助,还望各位大佬点赞支持谢谢


 浙公网安备 33010602011771号
浙公网安备 33010602011771号