

Kappa 统计量
行代表真实类别
列代表预测类别
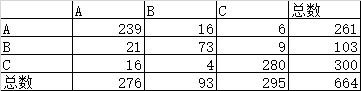
精确率 = 对角线的和 / 总数
p0 = (239 + 73 + 280) / 664 = 0.891566265060241
基于随机的分类
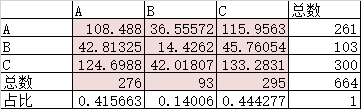
占比为预测为A\B\C类占总数的比例
预测为A 类的可能 = 276 / 664 = 0.415663
预测为B 类的可能 = 93 / 664 = 0.14006
预测为C 类的可能 = 295 / 664 = 0.444277
使用这个比例将红色区域填满:
第一行:随机分类器将会把0.415663的人分为A类,261的0.415663为108.488,
该分类器将会把0.14006的人分为B类,261的0.415663为36.55572
改分类器会把会有0.444277分为C类,261的0.444277为115.95
以此类推,第二行
随机分类器将会把0.415663的人分为A类,103的0.415663为42.81,
该分类器将会把0.14006的人分为B类,103的0.415663为14.42
改分类器会把会有0.444277分为C类,103的0.444277为45.76
因此pr = (108.488 + 14.4262 + 133.2831) / 644 = 0.385839290898534
Kappar k = (p0 - pr) / (1 - pr) = 0.823444037801766
如何解释这个结果,下面给出一个帮助我们理解该统计量大小的对照表:
<0: 比随机方法的性能还差(less than chance performance)
0.01-0.20: 轻微一致
0.21-0.40: 一般一致
0.41-0.60:中度一致
0.61-0.80:高度一致
0.81-1.00:接近完美
posted on 2018-01-24 14:02 Mrs.Totoro 阅读(990) 评论(0) 编辑 收藏 举报

