
深度学习随机梯度下降法
1.SGD
更新策略: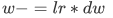
def sgd(w,dw,config=None): if config is None: config = {} config.setdefault('learning_rate',1e-2) w -= config['learning_rate'] * dw return w,config
2.SGD+Momentum
更新策略:

此外,还有一种等价的迭代法,如下:
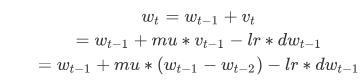
引入中间变量 , 并令其满足: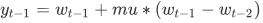
故而得到新的迭代形式:
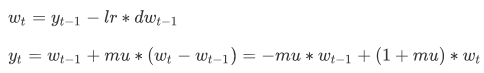
def sgd_moment(w,dw,config=None): if not config: config = {} config.setdefault('learning_rate',1e-1) config.setdefault('momentum',0.9) v = config.get('velocity',np.zeros_like(w)) v = config['momentum'] * v - config['learning_rate'] * dw w = w + v config['velocity'] = v return w,config
3. Nesterov动量
SGD + Momentum的一种变种,理论研究表明,对于凸函数能更快收敛,相比于普通动量。
核心思想:当参数向量位于某个位置 x 时,动量部分会通过mu * v 稍微改变 x 的位置,因此应该在 x + mu * v的位置 处计算梯度。与普通动量写为同样的形式:
x_head = x + mu * v v = mu * v - lr * dx_head x += v
如果实际存储的参数向量总是向前一步的,将x_head写成x,则可以写成:(其实得到是的x_head)
v_prev = v v = mu * v - lr * dx x += -mu * v_prev + (1+mu)*v
代码:
def nesterov(w,dw,config=None): if not config: config = {} config.setdefault('learning_rate',1e-1) config.setdefault('momentum',0.9) v = config.get('velocity',np.zeros_like(w)) v_next = config.get("momentum") * v - config.get("learning_rate") * dw netx_w = w -config.get("momentum") * v + (1 + config.get("momentum")) * v_next config["velocity"] = v_next return next_w,config
小结
上述3种方法,对学习率进行全局地操作,对于每个参数而言学习率一样。调参比较费时。因此,有很多工作在研究怎么适应性地调节学习率,甚至是逐个参数适应学习率调参(即每个参数可能学习率都不一样)。
是一种适应性学习率算法,根据累计梯度来决定每一步每个参数的学习率的大小:
cache += dx ** 2
x += -learning_rate * dx / (np.sqrt(cache)+eps)
缺点:实践中发现单调的学习率通常过于激进且过早停止学习。
5. RMSProp
是对Adagrad进行调整,使用了滑动平均的方法:
cache = decay_rate * cache + (1-decay_rate)*(dx ** 2)
x += -learning_rate * dx / (np.sqrt(cache)+eps)
def rmsprop(w,dw,config=None): if not config: config = {} config.setdefault("learning_rate",1e-2) config.setdefault("decay_rate",0.9) config.setdefault("epsilon",1e-8) config.setdefault("cache",np.zeros_like(w)) cache = config["cache"] cache = config["decay_rate"] * cache + (1-config["decay_rate"])*(dw**2) lr = config["learning_rate"] / (np.sqrt(cache)+config["epsilon"]) next_w = w - lr * dw config["cache"] = cache return next_w,config
decay_rate常用值[0.9,0.99,0.999],与Adagrad相比,learning_rate不会一直单调下降。
6.Adam
可以理解为RMSProp的动量版本
m = beta1 * m + (1-beta1) * dx # 梯度平滑 v = beta2 * v + (1-beta2) * (dx**2) mt = m / (1-beta1**t) vt = v / (1-beta2**t) x += -learning_rate * mt / (np.sqrt(vt)+eps) t += 1
eps=1e-8, beta1 =0.9, beta2=0.999
实际上,实现可能考虑到迭代次数
deft adam(w,dw,config=None): if not config: config = {} config.setdefault("learning_rate",1e-2) config.setdefault("beta1",0.9) config.setdefault("beta2",0.999) config.setdefault("epsilon",1e-8) config.setdefault("m",np.zeros_like(w)) config.setdefault("v",np.zeros_like(w)) config.setdefault("t",0) m,v,t = config["w"],config["v"],config["t"]+1 m = config["beta1"]*m + (1-config["beta1"])*dw v = config["beta2"]*v + (1-config["beta2"])*(dw**2) mt = m / (1 - config["beta1"]**t) #vt = v / (1 - config["beta2"]**t) lr = config["learning_rate"]*np.sqrt(1-config["beta2"]**t)/(np.sqrt(v)+config["epsilon"]) next_w = w - config["learning_rate"]*mt config["m"] = m config["v"] = v config["t"] = t return next_w, t
从效果来看, Adam, RMSProp逐参数适应学习率的算法,与SGD,SGD+ Momentum,Nesterous学习算法相比,更快收敛。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号