

使用maven&&make-distribution.sh编译打包spark源码
1》基础环境准备:
jdk1.8.0_101
maven 3.3.9
scala2.11.8
安装好上述软件,配置好环境变量,并检查是否生效。
2》配置maven:intellij idea maven配置及maven项目创建
3》设置maven编译内存
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
4.》使用maven命令编译源码。
mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.3 -Phive -Phive-thriftserver -DskipTests
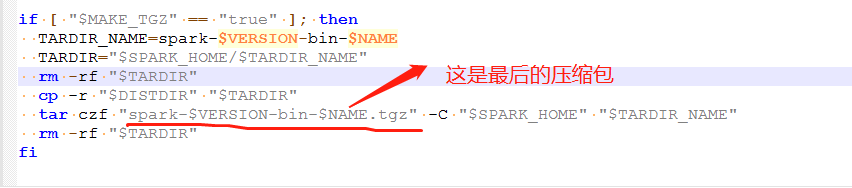
5》使用spark自带打包脚本打包(实际上该脚本调用上述的mvn命令,所以可以直接跳过第4步,当然如果只是调试用,不用打成压缩包,则直接到第4步即可)。
首先修改脚本:在spark源码包根目录下执行如下命令, vi dev/make-distribution.sh 注释掉以下内容:位于文件中的120~136行。 #VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ 2>/dev/null | grep -v "INFO" | tail -n 1) #SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ 2>/dev/null\ # | grep -v "INFO"\ # | tail -n 1) #SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null\ # | grep -v "INFO"\ # | tail -n 1) #SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null\ # | grep -v "INFO"\ # | fgrep --count "<id>hive</id>";\ # # Reset exit status to 0, otherwise the script stops here if the last grep finds nothing\ # # because we use "set -o pipefail" # echo -n) 添加以下内容: VERSION=2.3.0 SCALA_VERSION=2.11 SPARK_HADOOP_VERSION=2.7.3 SPARK_HIVE=1
6》修改后保存退出。在源码包根目录指定以下命令:
./dev/make-distribution.sh –name 2.7.3 –tgz -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.3 -Phadoop-provided -Phive -Phive-thriftserver -DskipTests
如果要编译对应的cdh版本,需要在源码的根目录下的pom文件中添加如下的仓库。
添加 cdh的仓库。
<repository>
<id>clouders</id>
<name>clouders Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
命令解释:
--name 2.7.3 ***指定编译出来的spark名字,name=
--tgz ***压缩成tgz格式
-Pyarn \ ***支持yarn平台
-Phadoop-2.7 \ -Dhadoop.version=2.7.3 \ ***指定hadoop版本为2.7.3
-Phive -Phive-thriftserver \ ***支持hive
-DskipTests clean package ***跳过测试包

