windows下在idea用maven导入spark2.3.1源码并编译并运行示例
一、前提
1.配置好maven:intellij idea maven配置及maven项目创建
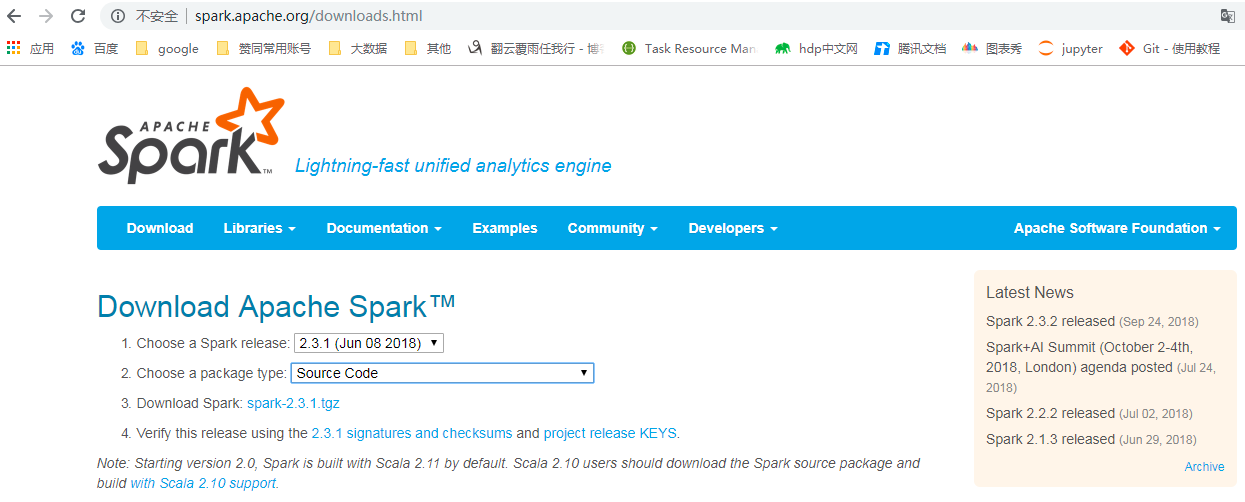
2.下载好spark源码:
二、导入源码:
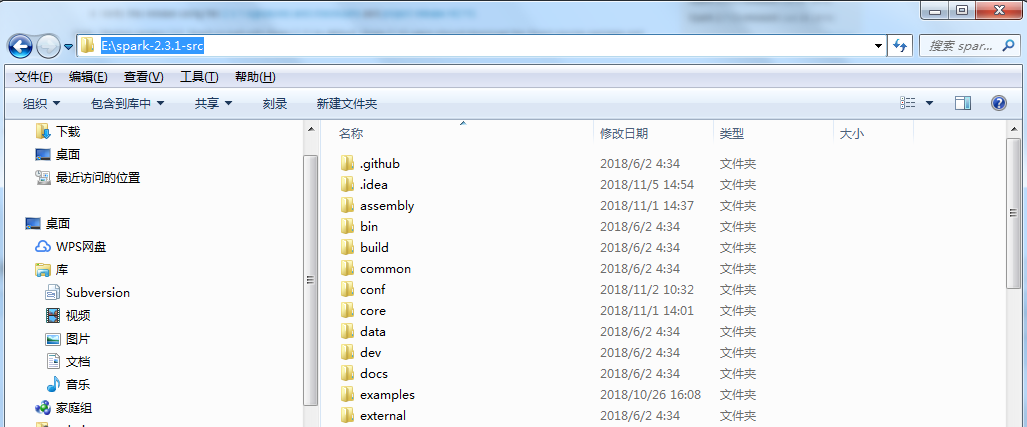
1.将下载的源码包spark-2.3.1.tgz解压(E:\spark-2.3.1.tgz\spark-2.3.1.tar)至E:\spark-2.3.1-src
2.在ideal导入源码:
a.选择解压的源代码文件夹
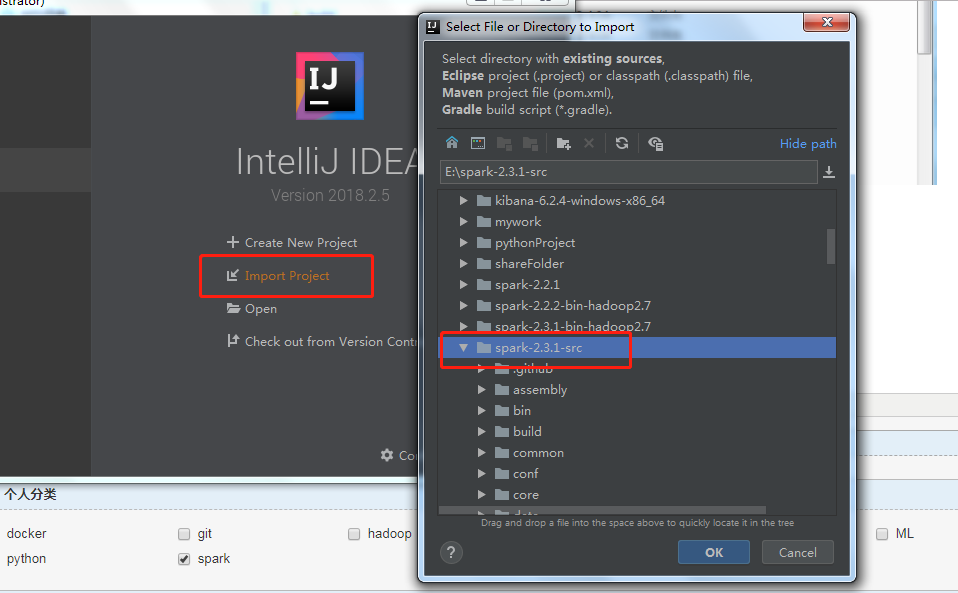
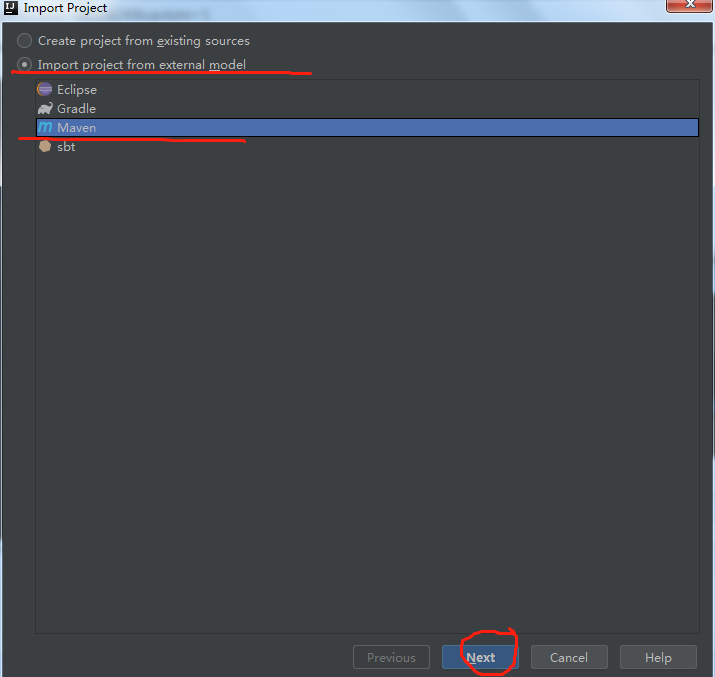
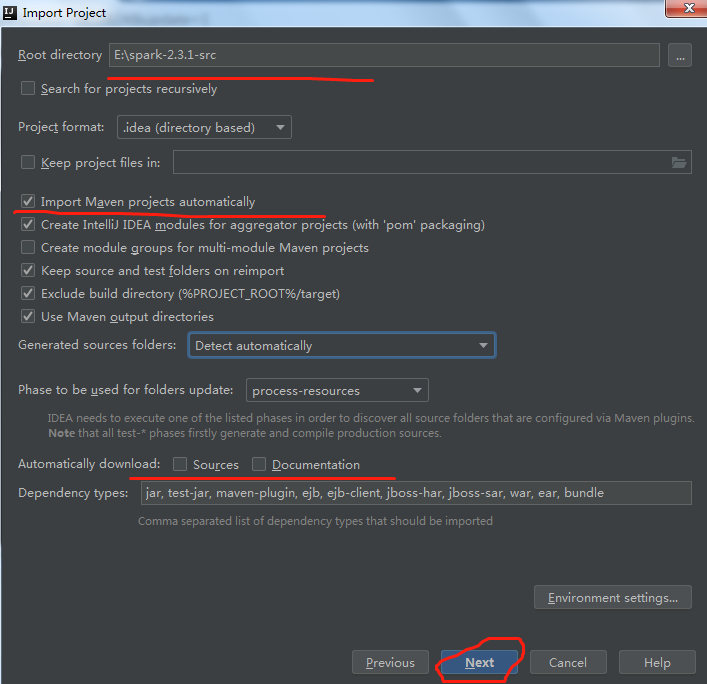
b.使用maven导入工程
c.选择对应组件的版本
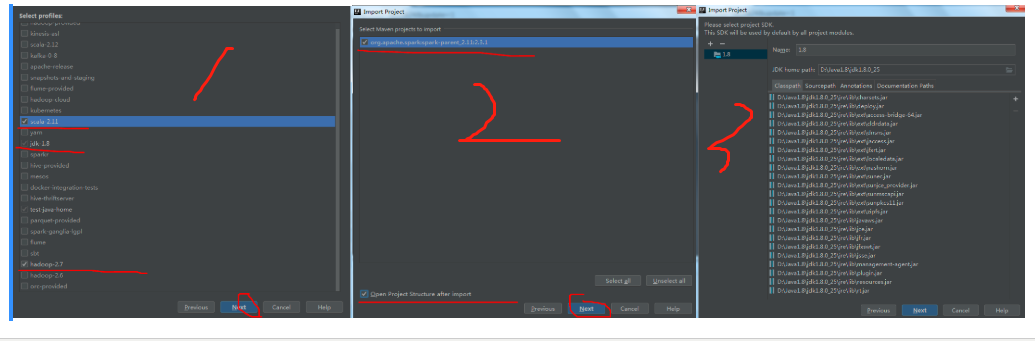
然后点击下一步:
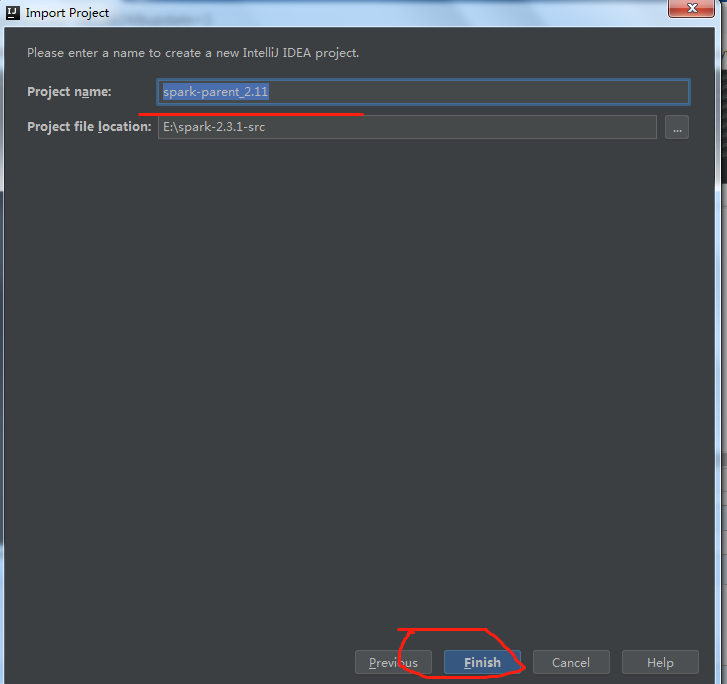 点击finish后,等待maven下载相关的依赖包,之后工程界面如下:
点击finish后,等待maven下载相关的依赖包,之后工程界面如下:
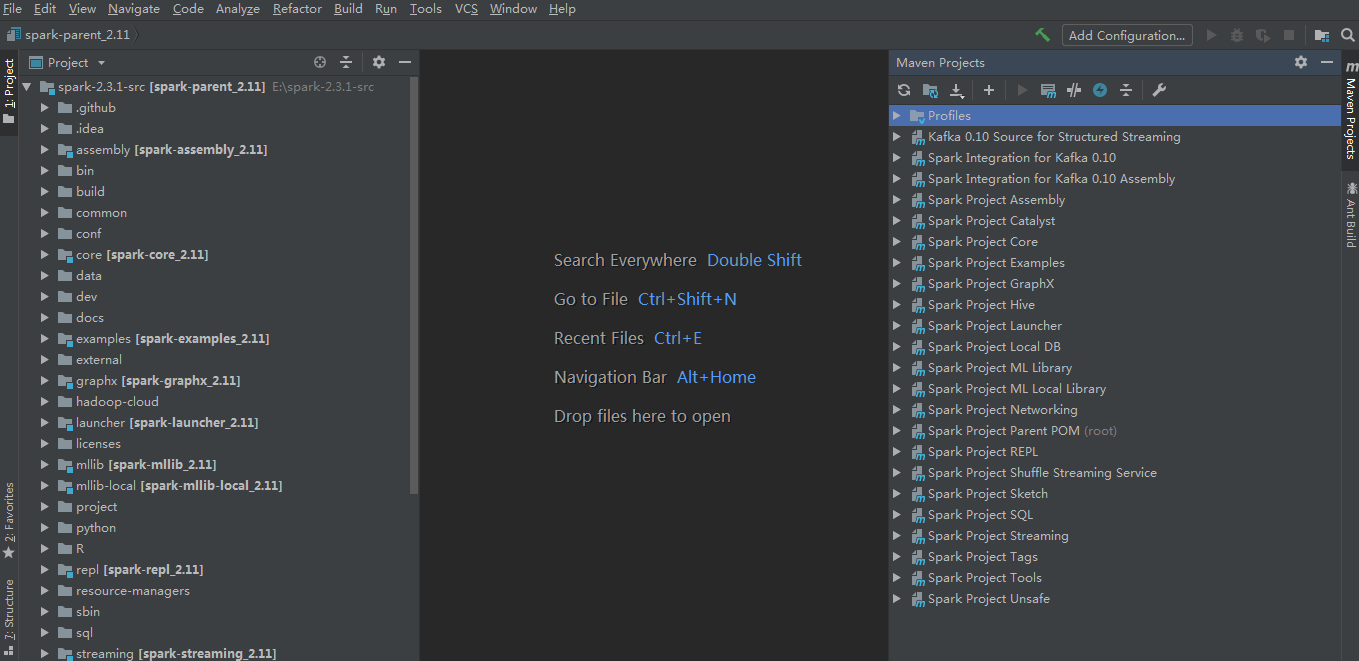
修改E:\spark-2.3.1-src\pom.xml文件,以避免这俩变量未定义,导致最终在E:\spark-2.3.1-src\assembly\target\scala-2.11\没有jar包

开始使用maven对spark源码进行编译打包成jar:
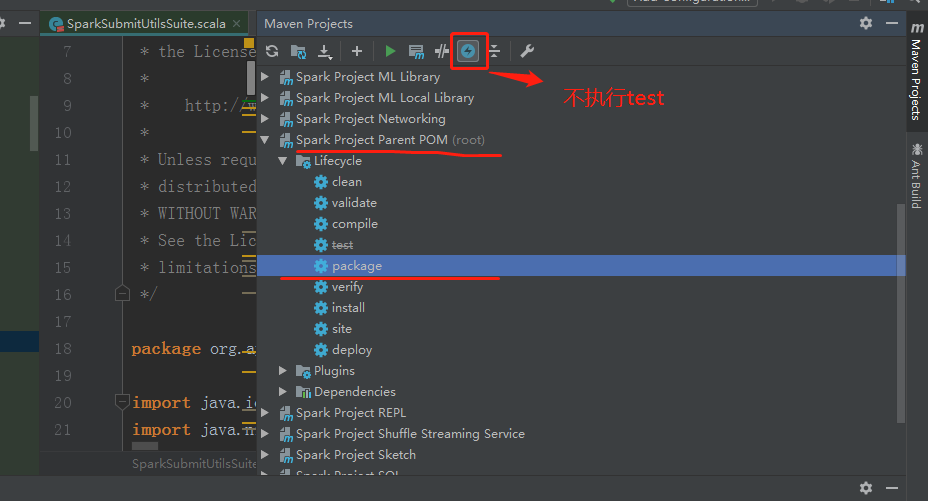
编译结果如下:
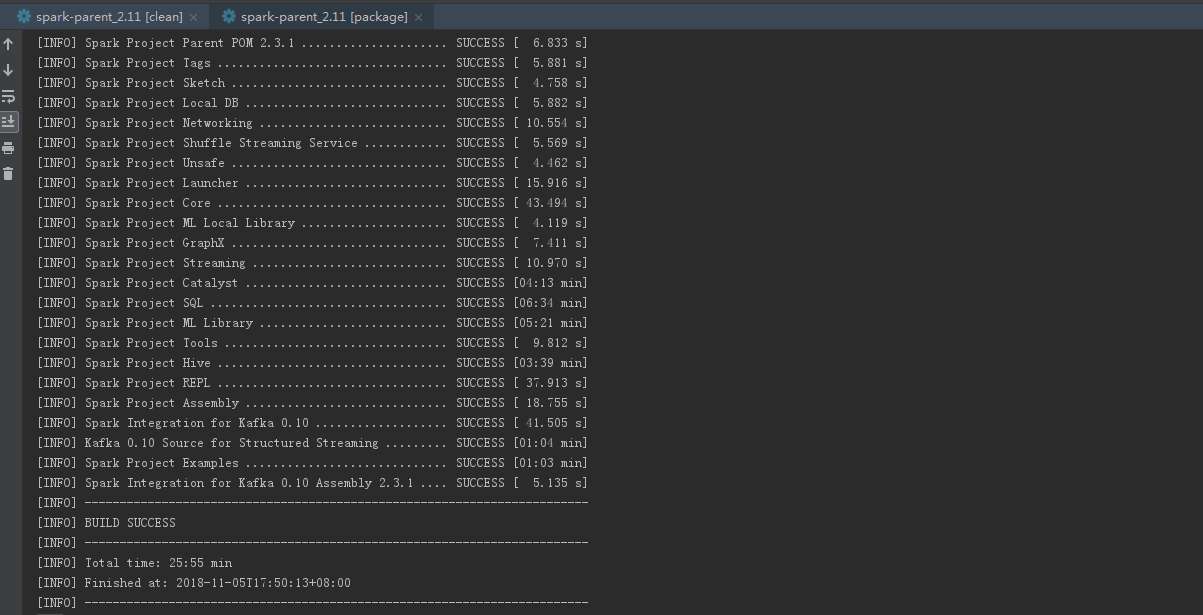
会在每个模块的target目录生成对应的jar,并在assembly\target\scala-2.11\jar下生成spark需要的全部jar包
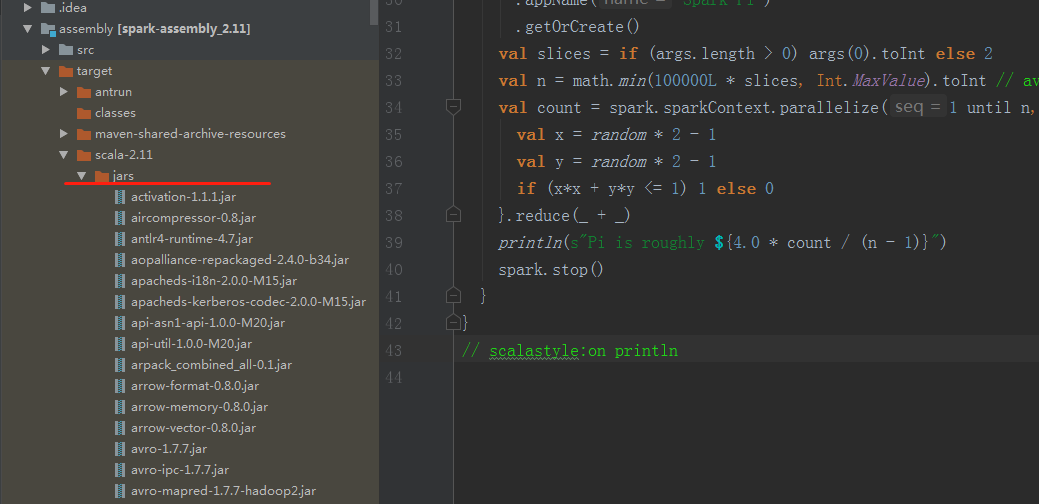

解决办法如下,在E:\spark-2.3.1-src\sql\catalyst\target目录下会出现antlr4相关的类:


三.运行spark自带示例(前提:需要配置spark在windows下的运行环境,参见win7下配置spark)
1.SparkPi
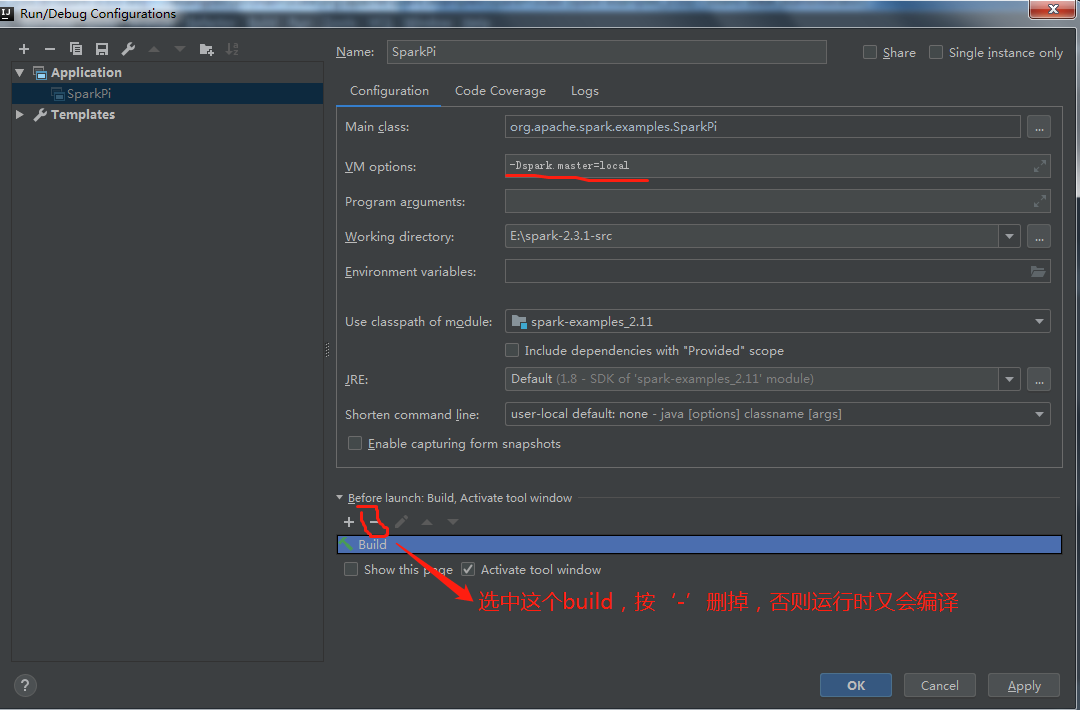
报错如下:
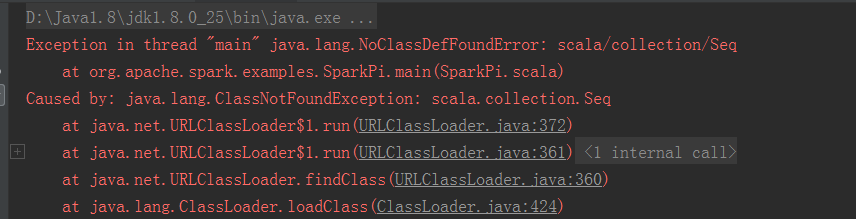
刚才生成的spark相关的依赖包没找到,解决办法如下:
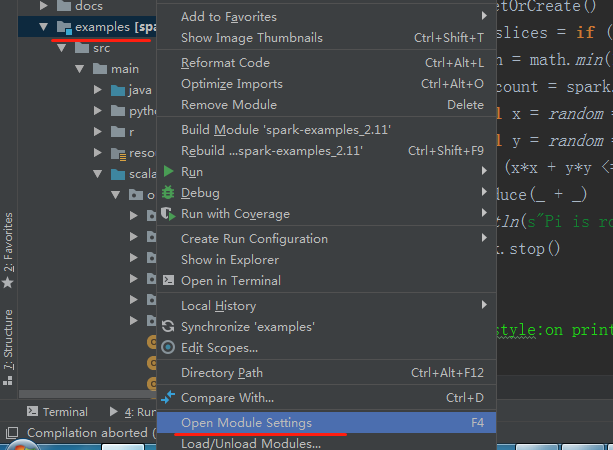


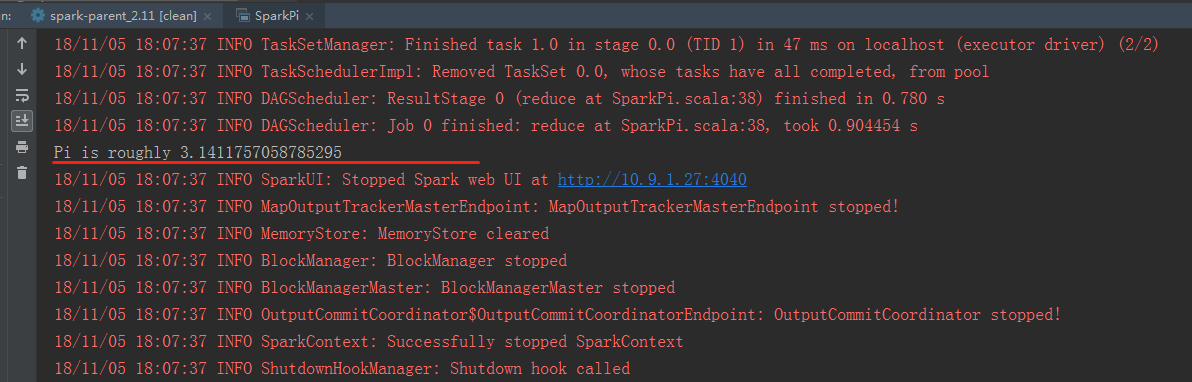
再次运行,结果如下:
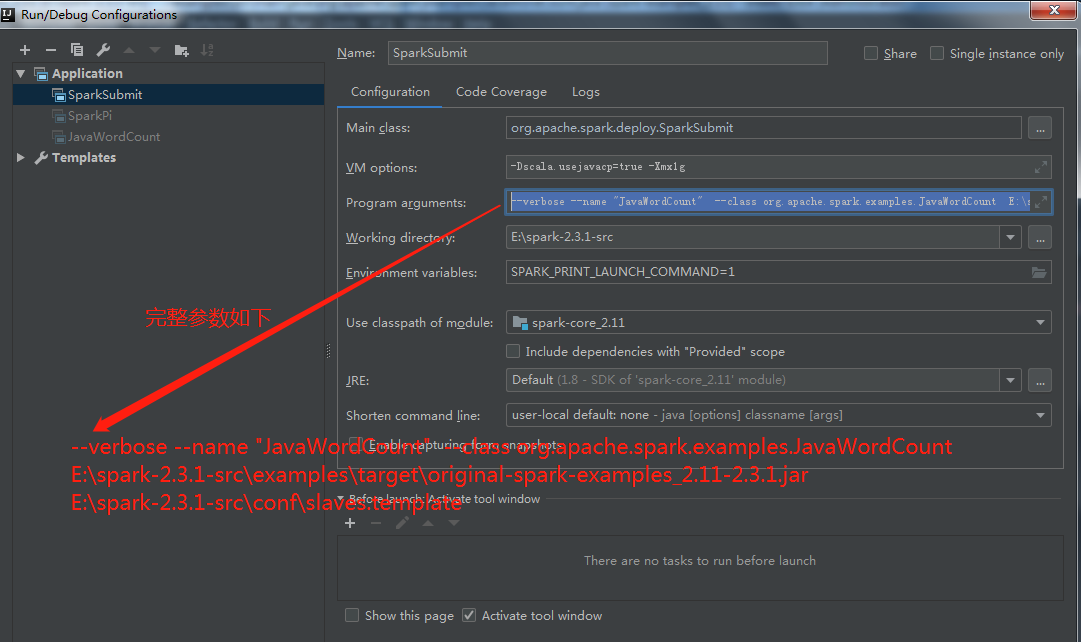
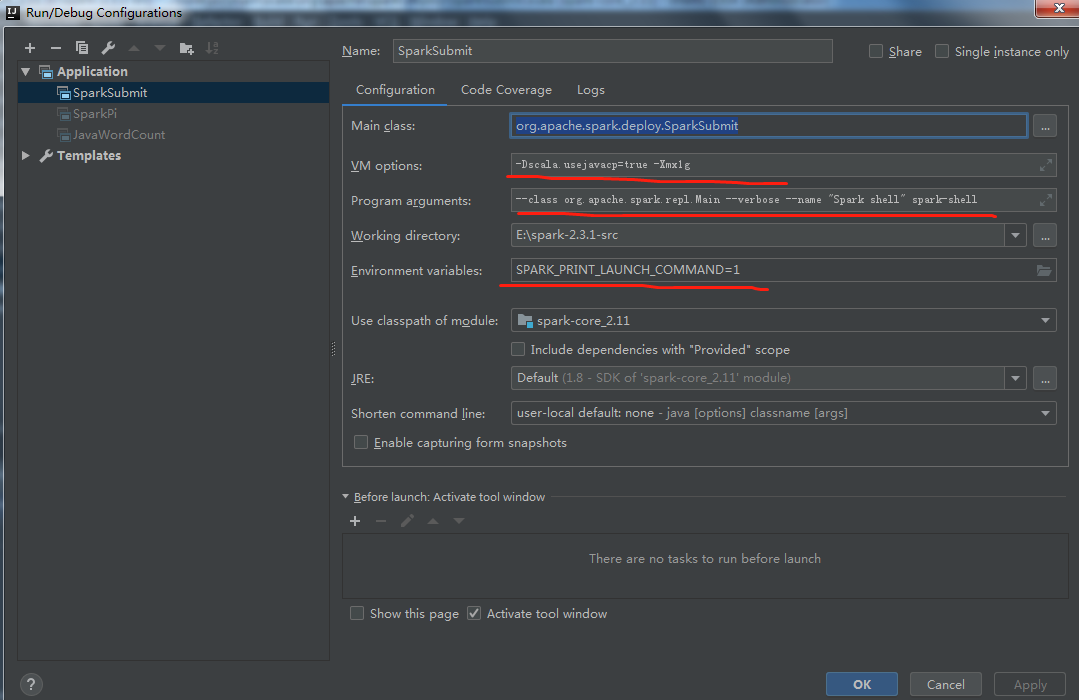
2.通过org.apache.spark.deploy.SparkSubmit提交任务并运行(前提是像运行SparkPi一样,把assembly\target\jars的依赖加进该模块,方法同上):
2.1 org.apache.spark.repl.Main
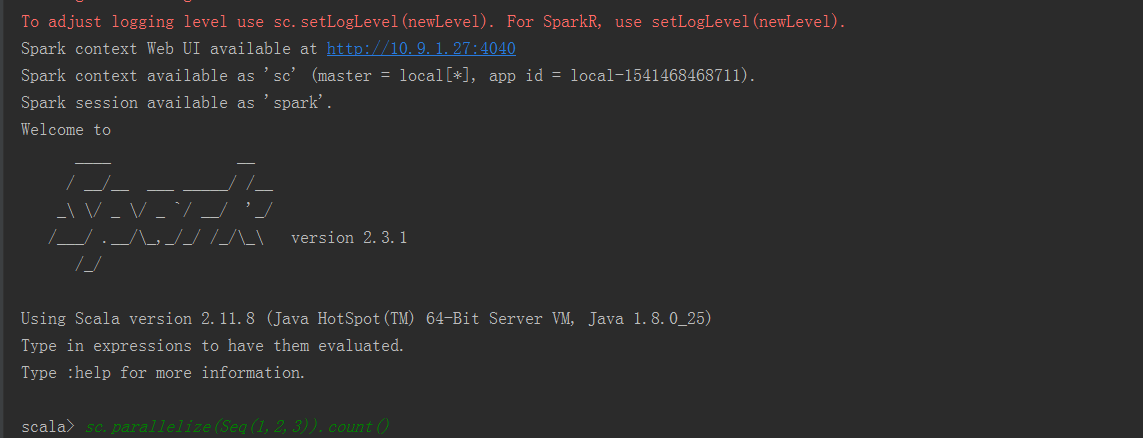
结果:
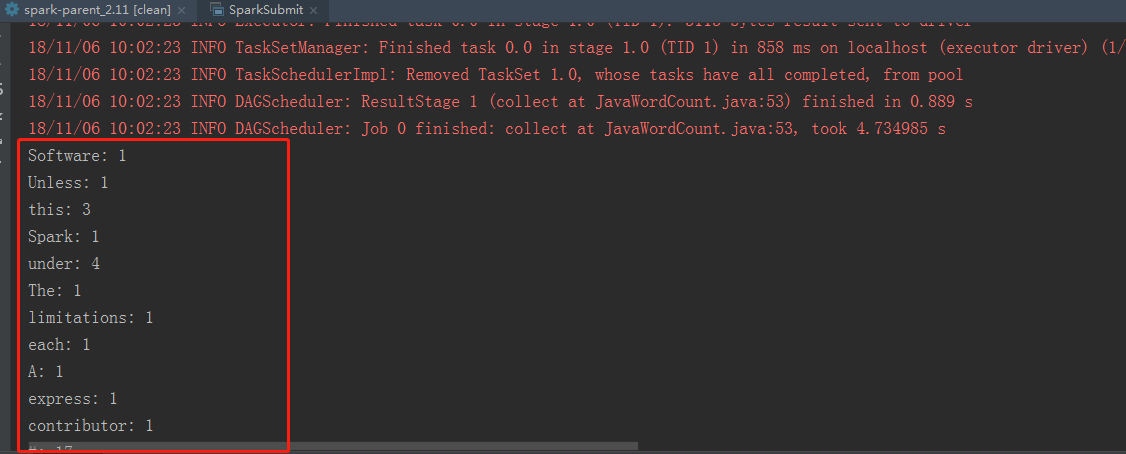
2.2 自定义spark代码类运行(以自带的org.apache.spark.examples.JavaWordCount为例)