

分层抽样
Stratified sampling
1. 基本概念
统计学理论中,分层抽样针对的是对一个总体(population)进行抽样的方法。尤其适用于当总体内部,子总体(subpopulations)间差异较大时。每一个 subpopulation,也称为层(stratum)。
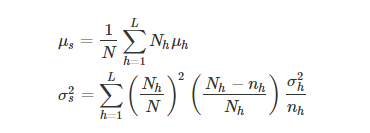
LL 表示层的数量,其中 ![]() 分别指的是层 h 的样本数量,采样的数量,采样得到的样本均值和标准差;
分别指的是层 h 的样本数量,采样的数量,采样得到的样本均值和标准差;
分层抽样方法,sampleByKey和sampleByKeyExact,可以在键-值对的RDD上精确执行。
对于分层抽样,可以将键视为一个标签,而值作为一个特定的属性。
例如,密钥可以是男性或女性,也可以是文档id,而相应的值可以是人口中人口的年龄列表,也可以是文档中的单词列表。
sampleByKey方法会抛硬币来决定一个观察是否被取样,因此需要一个传递数据,并提供一个预期的样本大小。sampleByKeyExact 需要比在sampleByKey中使用的每层简单随机抽样所需的资源多得多,但它将提供精确的采样大小和99.99%的置信度。
// an RDD[(K, V)] of any key value pairs val data = sc.parallelize( Seq((1, 'a'), (1, 'b'), (2, 'c'), (2, 'd'), (2, 'e'), (3, 'f'))) // specify the exact fraction desired from each key val fractions = Map(1 -> 0.1, 2 -> 0.6, 3 -> 0.3) // Get an approximate sample from each stratum val approxSample = data.sampleByKey(withReplacement = false, fractions = fractions) // Get an exact sample from each stratum val exactSample = data.sampleByKeyExact(withReplacement = false, fractions = fractions)

