
C++ 11 STL unordered_map容器
unordered_map 容器,直译过来就是"无序 map 容器"的意思。所谓“无序”,指的是 unordered_map 容器不会像 map 容器那样对存储的数据进行排序。换句话说,unordered_map 容器和 map 容器仅有一点不同,即 map 容器中存储的数据是有序的,而 unordered_map 容器中是无序的。
具体来讲,unordered_map 容器和 map 容器一样,以键值对(pair类型)的形式存储数据,存储的各个键值对的键互不相同且不允许被修改。但由于 unordered_map 容器底层采用的是哈希表存储结构,该结构本身不具有对数据的排序功能,所以此容器内部不会自行对存储的键值对进行排序。
值得一提的是,unordered_map 容器在<unordered_map>头文件中,并位于 std 命名空间中。
创建unordered_map容器
unordered_map 容器模板的定义如下所示:
template < class Key, //键值对中键的类型
class T, //键值对中值的类型
class Hash = hash<Key>, //容器内部存储键值对所用的哈希函数
class Pred = equal_to<Key>, //判断各个键值对键相同的规则
class Alloc = allocator< pair<const Key,T> > // 指定分配器对象的类型
> class unordered_map;
以上 5 个参数中,必须显式给前 2 个参数传值,并且除特殊情况外,最多只需要使用前 4 个参数,各自的含义和功能如表 1 所示。
| 参数 | 含义 |
|---|---|
| <key,T> | 前 2 个参数分别用于确定键值对中键和值的类型,也就是存储键值对的类型。 |
| Hash = hash<Key> | 用于指明容器在存储各个键值对时要使用的哈希函数,默认使用 STL 标准库提供的 hash<key> 哈希函数。注意,默认哈希函数只适用于基本数据类型(包括 string 类型),而不适用于自定义的结构体或者类。 |
| Pred = equal_to<Key> | 要知道,unordered_map 容器中存储的各个键值对的键是不能相等的,而判断是否相等的规则,就由此参数指定。默认情况下,使用 STL 标准库中提供的 equal_to<key> 规则,该规则仅支持可直接用 == 运算符做比较的数据类型。 |
当无序容器中存储键值对的键为自定义类型时,默认的哈希函数 hash 以及比较函数 equal_to 将不再适用,只能自己设计适用该类型的哈希函数和比较函数,并显式传递给 Hash 参数和 Pred 参数。
1) 通过调用 unordered_map 模板类的默认构造函数,可以创建空的 unordered_map 容器。比如:
std::unordered_map<std::string, std::string> umap;
2) 当然,在创建 unordered_map 容器的同时,可以完成初始化操作。比如:
std::unordered_map<std::string, std::string> umap{
{"Python教程","http://c.biancheng.net/python/"},
{"Java教程","http://c.biancheng.net/java/"},
{"Linux教程","http://c.biancheng.net/linux/"} };
通过此方法创建的 umap 容器中,就包含有 3 个键值对元素。
3) 另外,还可以调用 unordered_map 模板中提供的复制(拷贝)构造函数,将现有 unordered_map 容器中存储的键值对,复制给新建 unordered_map 容器。
例如,在第二种方式创建好 umap 容器的基础上,再创建并初始化一个 umap2 容器:
std::unordered_map<std::string, std::string> umap2(umap);
由此,umap2 容器中就包含有 umap 容器中所有的键值对。
除此之外,C++ 11 标准中还向 unordered_map 模板类增加了移动构造函数,即以右值引用的方式将临时 unordered_map 容器中存储的所有键值对,全部复制给新建容器。例如:
//返回临时 unordered_map 容器的函数
std::unordered_map <std::string, std::string > retUmap(){
std::unordered_map<std::string, std::string>tempUmap{
{"Python教程","http://c.biancheng.net/python/"},
{"Java教程","http://c.biancheng.net/java/"},
{"Linux教程","http://c.biancheng.net/linux/"} };
return tempUmap;
}
//调用移动构造函数,创建 umap2 容器
std::unordered_map<std::string, std::string> umap2(retUmap());
注意,无论是调用复制构造函数还是拷贝构造函数,必须保证 2 个容器的类型完全相同。
4) 当然,如果不想全部拷贝,可以使用 unordered_map 类模板提供的迭代器,在现有 unordered_map 容器中选择部分区域内的键值对,为新建 unordered_map 容器初始化。例如:
//传入 2 个迭代器, std::unordered_map<std::string, std::string> umap2(++umap.begin(),umap.end());
通过此方式创建的 umap2 容器,其内部就包含 umap 容器中除第 1 个键值对外的所有其它键值对。
unordered_map的成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个键值对的正向迭代器。 |
| end() | 返回指向容器中最后一个键值对之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有键值对的个数。 |
| max_size() | 返回容器所能容纳键值对的最大个数,不同的操作系统,其返回值亦不相同。 |
| operator[key] | 该模板类中重载了 [] 运算符,其功能是可以向访问数组中元素那样,只要给定某个键值对的键 key,就可以获取该键对应的值。注意,如果当前容器中没有以 key 为键的键值对,则其会使用该键向当前容器中插入一个新键值对。 |
| at(key) | 返回容器中存储的键 key 对应的值,如果 key 不存在,则会抛出 out_of_range 异常。 |
| find(key) | 查找以 key 为键的键值对,如果找到,则返回一个指向该键值对的正向迭代器;反之,则返回一个指向容器中最后一个键值对之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找以 key 键的键值对的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中键为 key 的键值对所在的范围。 |
| emplace() | 向容器中添加新键值对,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新键值对,效率比 insert() 方法高。 |
| insert() | 向容器中添加新键值对。 |
| erase() | 删除指定键值对。 |
| clear() | 清空容器,即删除容器中存储的所有键值对。 |
| swap() | 交换 2 个 unordered_map 容器存储的键值对,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储键值对时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_map 容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储键值对的数量。 |
| bucket(key) | 返回以 key 为键的键值对所在桶的编号。 |
| load_factor() | 返回 unordered_map 容器中当前的负载因子。负载因子,指的是的当前容器中存储键值对的数量(size())和使用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳count个元(不超过最大负载因子)所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
C++ STL 标准库中,unordered_map 容器迭代器的类型为前向迭代器(又称正向迭代器)。这意味着,假设 p 是一个前向迭代器,则其只能进行 *p、p++、++p 操作,且 2 个前向迭代器之间只能用 == 和 != 运算符做比较。
需要注意的是,在操作 unordered_map 容器过程(尤其是向容器中添加新键值对)中,一旦当前容器的负载因子超过最大负载因子(默认值为 1.0),该容器就会适当增加桶的数量(通常是翻一倍),并自动执行 rehash() 成员方法,重新调整各个键值对的存储位置(此过程又称“重哈希”),此过程很可能导致之前创建的迭代器失效。
所谓迭代器失效,针对的是那些用于表示容器内某个范围的迭代器,由于重哈希会重新调整每个键值对的存储位置,所以容器重哈希之后,之前表示特定范围的迭代器很可能无法再正确表示该范围。但是,重哈希并不会影响那些指向单个键值对元素的迭代器。
unordered_map容器的大部分成员方法与map容器基本一致,可以参考C++ STL map容器 - 默行于世 - 博客园 (cnblogs.com)
无序关联式容器底层实现机制
C++ STL 标准库中,不仅是 unordered_map 容器,所有无序容器的底层实现都采用的是哈希表存储结构。更准确地说,是用“链地址法”(又称“开链法”)解决数据存储位置发生冲突的哈希表。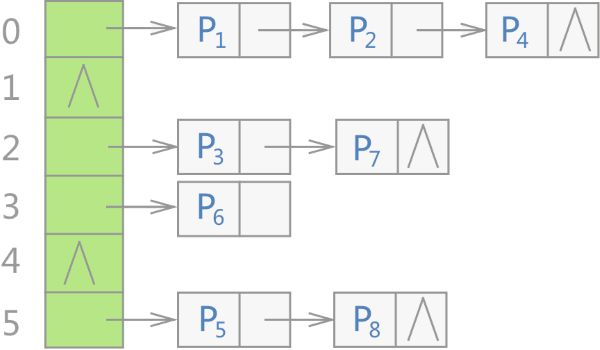
其中,Pi 表示存储的各个键值对。
可以看到,当使用无序容器存储键值对时,会先申请一整块连续的存储空间,但此空间并不用来直接存储键值对,而是存储各个链表的头指针,各键值对真正的存储位置是各个链表的节点。
注意,STL 标准库通常选用 vector 容器存储各个链表的头指针。
不仅如此,在 C++ STL 标准库中,将图 1 中的各个链表称为桶(bucket),每个桶都有自己的编号(从 0 开始)。当有新键值对存储到无序容器中时,整个存储过程分为如下几步:
- 将该键值对中键的值带入设计好的哈希函数,会得到一个哈希值(一个整数,用 H 表示);
- 将 H 和无序容器拥有桶的数量 n 做整除运算(即 H % n),该结果即表示应将此键值对存储到的桶的编号;
- 建立一个新节点存储此键值对,同时将该节点链接到相应编号的桶上。
另外值得一提的是,哈希表存储结构还有一个重要的属性,称为负载因子(load factor)。该属性同样适用于无序容器,用于衡量容器存储键值对的空/满程序,即负载因子越大,意味着容器越满,即各链表中挂载着越多的键值对,这无疑会降低容器查找目标键值对的效率;反之,负载因子越小,容器肯定越空,但并不一定各个链表中挂载的键值对就越少。
举个例子,如果设计的哈希函数不合理,使得各个键值对的键带入该函数得到的哈希值始终相同(所有键值对始终存储在同一链表上)。这种情况下,即便增加桶数是的负载因子减小,该容器的查找效率依旧很差。
无序容器中,负载因子的计算方法为: 负载因子 = 容器存储的总键值对 / 桶数
默认情况下,无序容器的最大负载因子为 1.0。如果操作无序容器过程中,使得最大复杂因子超过了默认值,则容器会自动增加桶数,并重新进行哈希,以此来减小负载因子的值。需要注意的是,此过程会导致容器迭代器失效,但指向单个键值对的引用或者指针仍然有效。
这也就解释了,为什么我们在操作无序容器过程中,键值对的存储顺序有时会“莫名”的发生变动。
C++ STL 标准库为了方便用户更好地管控无序容器底层使用的哈希表存储结构,各个无序容器的模板类中都提供下表所示的成员方法。
| 成员方法 | 功能 |
|---|---|
| bucket_count() | 返回当前容器底层存储键值对时,使用桶的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_map 容器底层最多可以使用多少个桶。 |
| bucket_size(n) | 返回第 n 个桶中存储键值对的数量。 |
| bucket(key) | 返回以 key 为键的键值对所在桶的编号。 |
| load_factor() | 返回 unordered_map 容器中当前的负载因子。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的最大负载因子。 |
| rehash(n) | 尝试重新调整桶的数量为等于或大于 n 的值。如果 n 大于当前容器使用的桶数,则该方法会是容器重新哈希,该容器新的桶数将等于或大于 n。反之,如果 n 的值小于当前容器使用的桶数,则调用此方法可能没有任何作用。 |
| reserve(n) | 将容器使用的桶数(bucket_count() 方法的返回值)设置为最适合存储 n 个元素的桶数。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
下面的程序以学过的 unordered_map 容器为例,演示了表 2 中部分成员方法的用法:
#include <iostream> #include <string> #include <unordered_map> using namespace std;
int main(){ //创建空 umap 容器 unordered_map<string, string> umap; cout << "umap 初始桶数: " << umap.bucket_count() << endl; cout << "umap 初始负载因子: " << umap.load_factor() << endl; cout << "umap 最大负载因子: " << umap.max_load_factor() << endl;
//设置 umap 使用最适合存储 9 个键值对的桶数 umap.reserve(9); cout << "*********************" << endl; cout << "umap 新桶数: " << umap.bucket_count() << endl; cout << "umap 新负载因子: " << umap.load_factor() << endl;
//向 umap 容器添加 3 个键值对 umap["Python教程"] = "http://c.biancheng.net/python/"; umap["Java教程"] = "http://c.biancheng.net/java/"; umap["Linux教程"] = "http://c.biancheng.net/linux/";
//调用 bucket() 获取指定键值对位于桶的编号 cout << "以\"Python教程\"为键的键值对,位于桶的编号为:" << umap.bucket("Python教程") << endl;
//自行计算某键值对位于哪个桶 auto fn = umap.hash_function(); cout << "计算以\"Python教程\"为键的键值对,位于桶的编号为:" << fn("Python教程") % (umap.bucket_count()) << endl; return 0; }
程序执行结果为:
umap 初始桶数: 8 umap 初始负载因子: 0 umap 最大负载因子: 1 ********************* umap 新桶数: 16 umap 新负载因子: 0 以"Python教程"为键的键值对,位于桶的编号为:9 计算以"Python教程"为键的键值对,位于桶的编号为:9
从输出结果可以看出,对于空的 umap 容器,初始状态下会分配 8 个桶,并且默认最大负载因子为 1.0,但由于其为存储任何键值对,因此负载因子值为 0。
与此同时,程序中调用 reverse() 成员方法,是 umap 容器的桶数改为了 16,其最适合存储 9 个键值对。从侧面可以看出,一旦负载因子大于 1.0(9/8 > 1.0),则容器所使用的桶数就会翻倍式(8、16、32、...)的增加。
程序最后还演示了如何手动计算出指定键值对存储的桶的编号,其计算结果和使用 bucket() 成员方法得到的结果是一致的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号