python线程实现异步任务
了解异步编程
楼主在工作中遇到了以下问题,开发接口爬取数据代码完成之后要写入redis缓存,但是在写入缓存的过程花费2-3s,进行这样就大大影响了接口的性能,于是想到了使用异步存储。
传统的同步编程是一种请求响应模型,调用一个方法,等待其响应返回.
异步编程就是要重新考虑是否需要响应的问题,也就是缩小需要响应的地方。因为越快获得响应,就是越同步化,顺序化,事务化,性能差化。
线程实现异步
思路:通过线程调用的方式,来达到异步非阻塞的效果,也就是说主程序无需等待线程执行完毕,仍然可以继续向下执行。
1.threading模块和thread模块
Python通过两个标准库thread和threading提供对线程的支持。thread提供了低级别的、原始的线程以及一个简单的锁。
threading 模块提供的其他方法:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
同步阻塞:
1 import threading,time 2 3 def thead(num): 4 time.sleep(1) 5 print("阻塞程序%s开始执行"%num) 6 time.sleep(3) 7 print("阻塞程序%s执行完毕"%num) 8 9 def main(): 10 print("主方法开始执行") 11 12 for i in range(1,3): 13 thead(i) 14 15 print("主方法执行完毕") 16 return 17 18 if __name__ == '__main__': 19 print(time.ctime()) 20 num = main() 21 print("返回结果为%s"%num) 22 print(time.ctime())
Wed Nov 21 09:22:56 2018
主方法开始执行
阻塞程序1开始执行
阻塞程序1执行完毕
阻塞程序2开始执行
阻塞程序2执行完毕
主方法执行完毕
返回结果为None
Wed Nov 21 09:23:04 2018
异步,无需等待线程执行
import threading,time
def thead(num):
# time.sleep(1)
print("线程%s开始执行"%num)
time.sleep(3)
print("线程%s执行完毕"%num)
def main():
print("主方法开始执行")
#创建2个线程
poll = []#线程池
for i in range(1,3):
thead_one = threading.Thread(target=thead, args=(i,))
poll.append(thead_one) #线程池添加线程
for n in poll:
n.start() #准备就绪,等待cpu执行
print("主方法执行完毕")
return
if __name__ == '__main__':
print(time.ctime())
num = main()
print("返回结果为%s"%num)
print(time.ctime())
Wed Nov 21 09:48:00 2018
主方法开始执行
主方法执行完毕
返回结果为None
Wed Nov 21 09:48:00 2018
线程1开始执行
线程2开始执行
线程1执行完毕
线程2执行完毕
2.concurrent.futures模块
concurrent.futures模块实现了对threading(线程)和multiprocessing(进程)的更高级的抽象,对编写线程池/进程池提供了直接的支持。
从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,ThreadPoolExecutor和ProcessPoolExecutor继承了Executor,分别被用来创建线程池和进程池的代码。(暂时只介绍线程池的使用)
concurrent.futures模块的基础是Exectuor,Executor是一个抽象类,它不能被直接使用。但是它提供的两个子类ThreadPoolExecutor和ProcessPoolExecutor却是非常有用,顾名思义两者分别被用来创建线程池和进程池的代码。我们可以将相应的tasks直接放入线程池/进程池,不需要维护Queue来操心死锁的问题,线程池/进程池会自动帮我们调度。
Future这个概念你可以把它理解为一个在未来完成的操作,这是异步编程的基础,传统编程模式下比如我们操作queue.get的时候,在等待返回结果之前会产生阻塞,cpu不能让出来做其他事情,而Future的引入帮助我们在等待的这段时间可以完成其他的操作。
-
Future Objects:Future类封装了可调用的异步执行.Future 实例通过 Executor.submit()方法创建。
- submit(fn, *args, **kwargs):调度可调用的fn,作为fn(args kwargs)执行,并返回一个表示可调用的执行的Future对象。
-
ThreadPoolExecutor:ThreadPoolExecutor是一个Executor的子类,它使用线程池来异步执行调用。
-
concurrent.futures.ThreadPoolExecutor(max_workers=None, thread_name_prefix=''):Executor子类,使用max_workers规格的线程池来执行异步调用。
在Flask应用中使用异步redis:
from flask import Flask import time from concurrent.futures import ThreadPoolExecutor executor = ThreadPoolExecutor() app = Flask(__name__) @app.route('/') def update_redis(): executor.submit(do_update) return 'ok' def do_update(): time.sleep(3) print('start update cache') time.sleep(1) print("end") if __name__ == '__main__': app.run(debug=True)
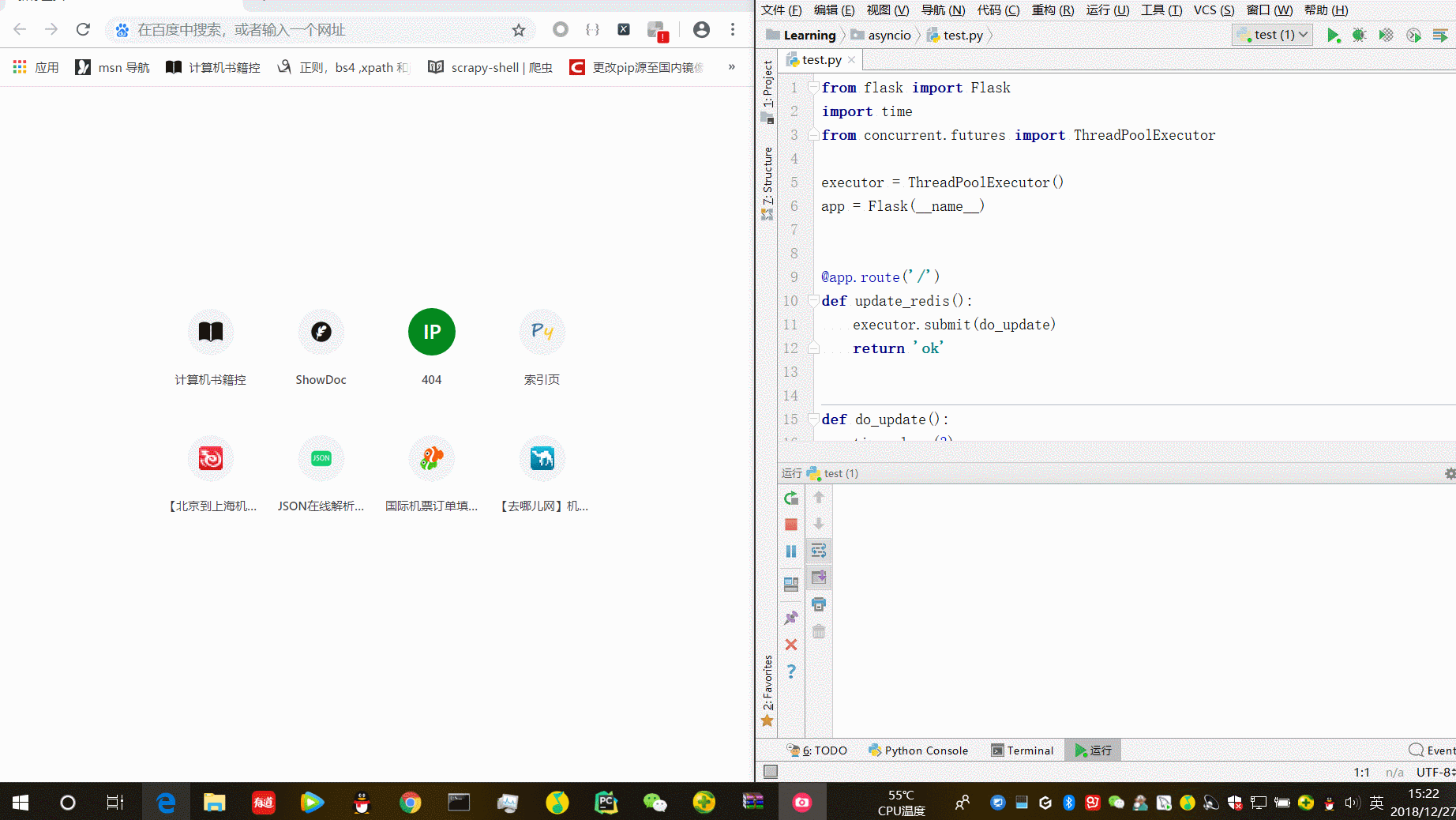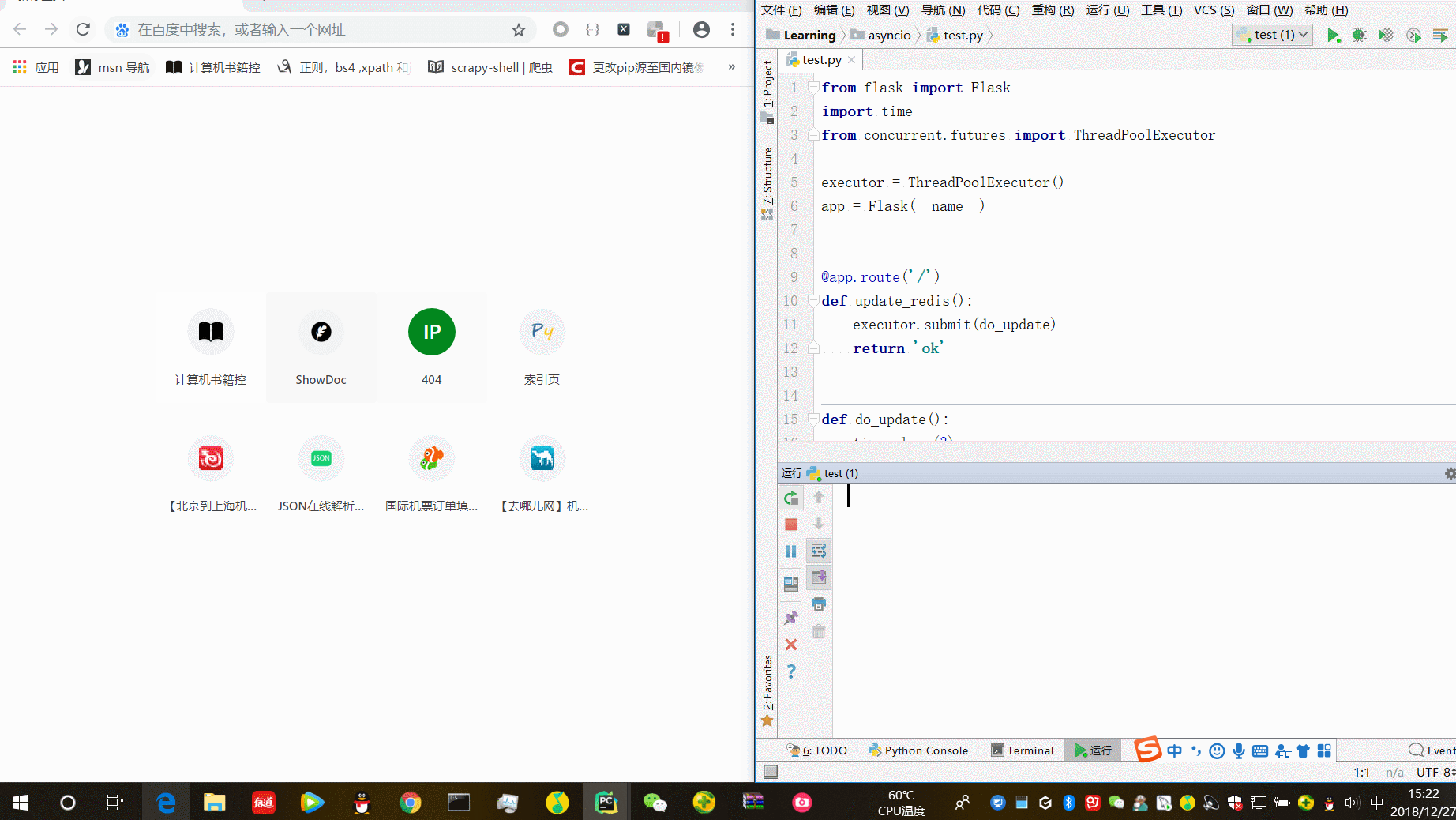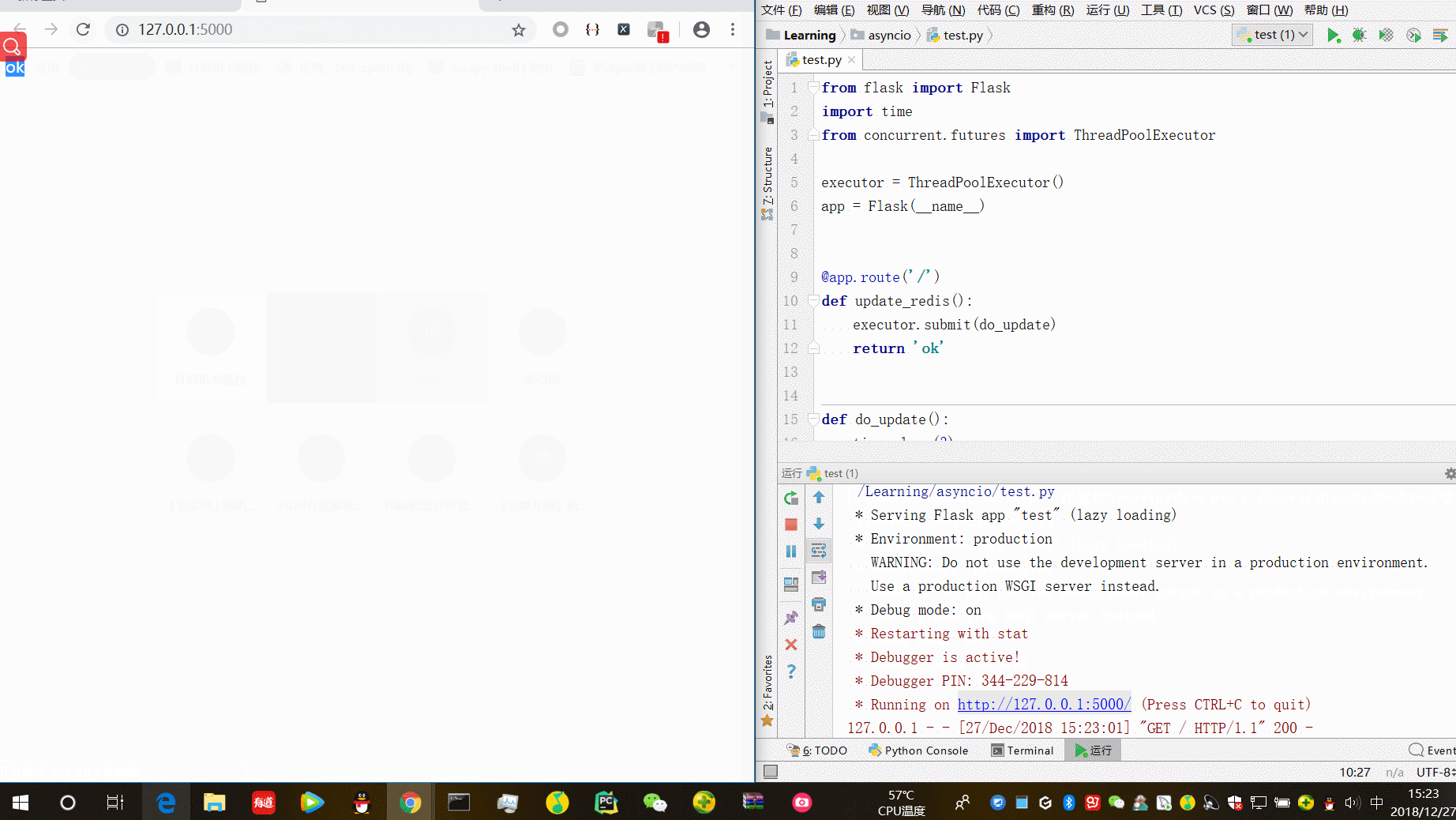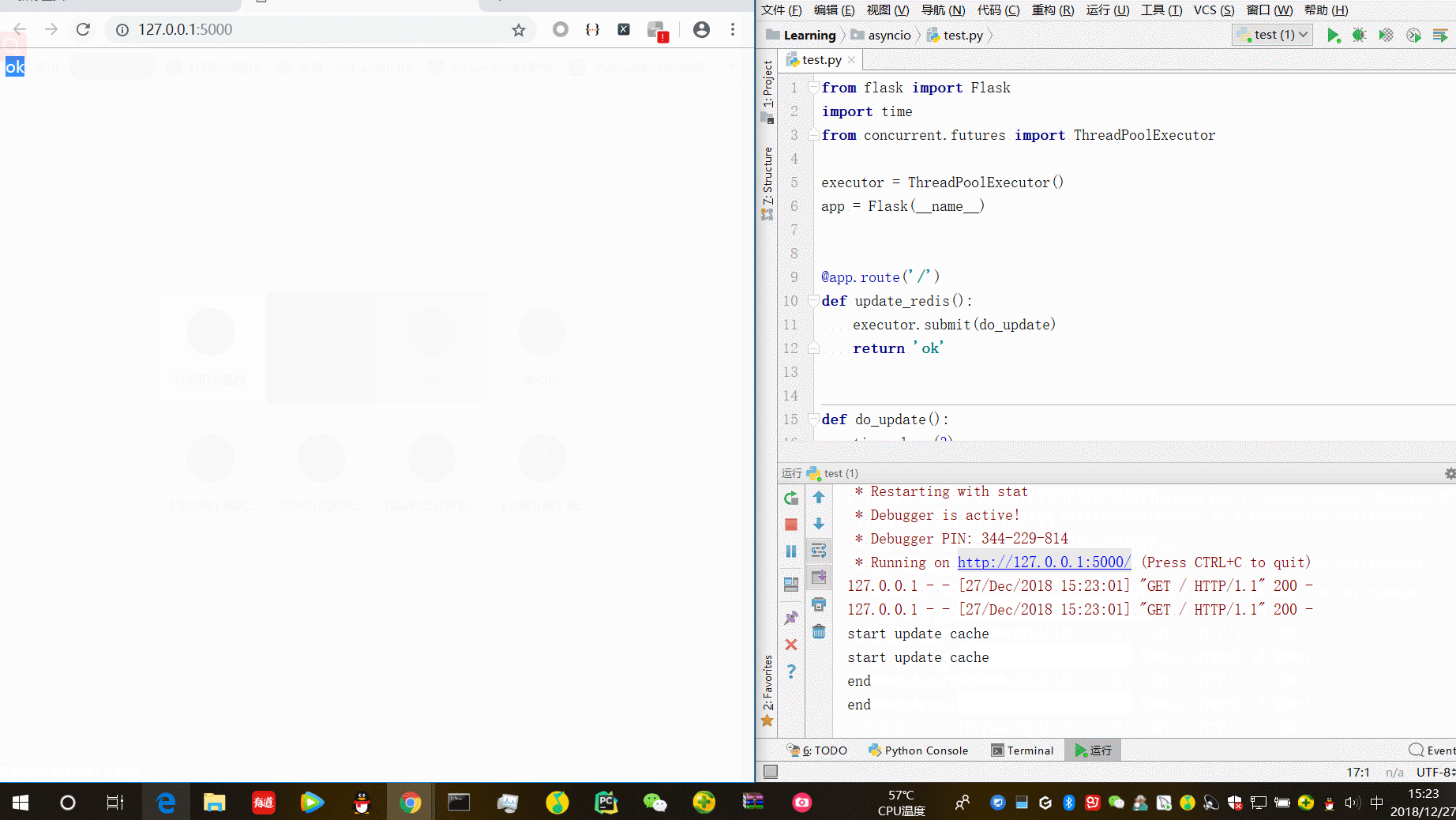
“ok“在更新缓存前已经返回。
本文到这里就结束了,着重介绍了线程实现异步的方法。当然还有其他的方法,比如yied实现,还有asyncio模块,后续会继续更新异步编程的文章。
温馨提示
- 本文代码是在python3.5版本测试运行。
- 如果您对本文有疑问,请在评论部分留言,我会在最短时间回复。
- 如果本文帮助了您,也请评论关注,作为对我的一份鼓励。
- 如果您感觉我写的有问题,也请批评指正,我会尽量修改。
- 本文为原创,转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号