
机器学习:集成学习(ensemble learning)(一)——原理概述
集成学习(ensemble learning)
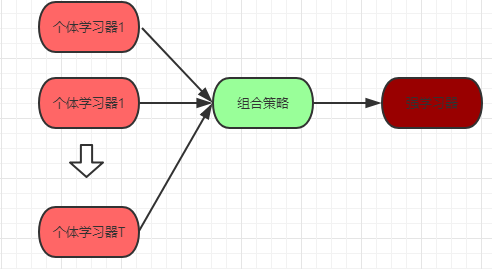
集成学习通过构建多个个体学习器,然后再用某种策略将他们结合起来,产生一个有较好效果的强学习器来完成任务。基本原理如下图所示。这里主要有三个关键点:个体学习器的同质异质、个体学习器的生成方式、结合策略。
- 同质异质。首先需要明确的是个体学习器至少不差于弱学习器。弱学习器常指泛化性能略优于随机猜测的学习器,例如二分类问题中精度略高于50%的分类器。对于训练数据若集成中的个体学习器为同一类型,例如都为BP神经网络或者都为决策树,则称同质集成。同样的道理,若个体学习器类型不同,例如既有决策树又有神经网络,则称异质集成。
- 个体学习器的生成方式。主要可以分为两种,个体学习器之间存在强依赖关系、必须串行生成的序列化方法,以及个体学习器件不存在强依赖关系、可同时生成的并行化方法。前者代表是Boosting,后者代表是Bagging和随机森林(Random Forest)。
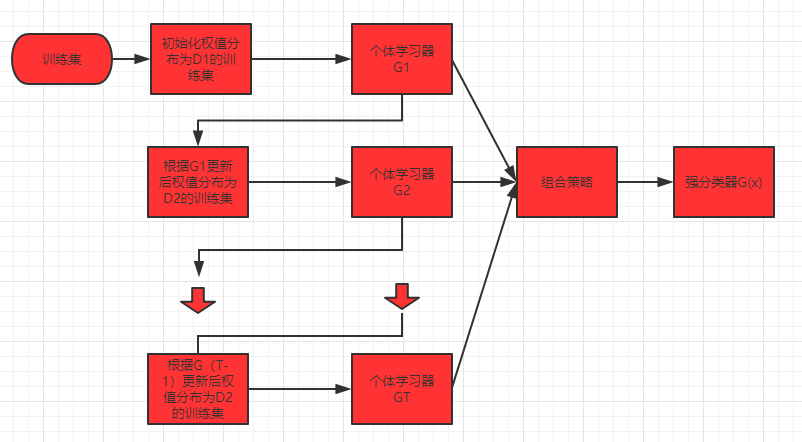
1.Boosting基本原理如图所示。大多数提升方法都是改变训练数据的概率分布(训练数据的权值分布),针对不同训练数据分布获得不同个体学习器,最终组合。因此需要解决两个问题,一是每一轮怎样改变权值分布的,二是如何将个体学习器进行组合的。Adaboost做法是,对于前者提高被前一轮预测错误样本的的权重,降低预测正确样本的的权重,对于后者加大误差率小的个体学习器的权值,减小误差率小的个体学习率的权值。Boosting算法要求个体学习器能够对特定的数据分布进行学习,这可以通过“重赋权法”实施,即在训练过程每一轮中,根据样本分布对每个样本重新赋予权重。对于无法接受带权样本的个体学习器(算法),可以通过“重采样法”来处理,即在每一轮学习中,根据样本分布对训练集重新采样,再用重采样得到的样本集对个体学习器进行训练。一般情况下两者差别不大。需要注意的是每一轮训练中需要检查当前生成的学习器是否满足基本条件,一旦不满足,则被抛弃,并且学习停止,此时可能还远远没有达到最大学习轮数,导致最终学习器性能欠佳。若采用“重采样法”,则会“重启动”,以避免过早停止。
![]()
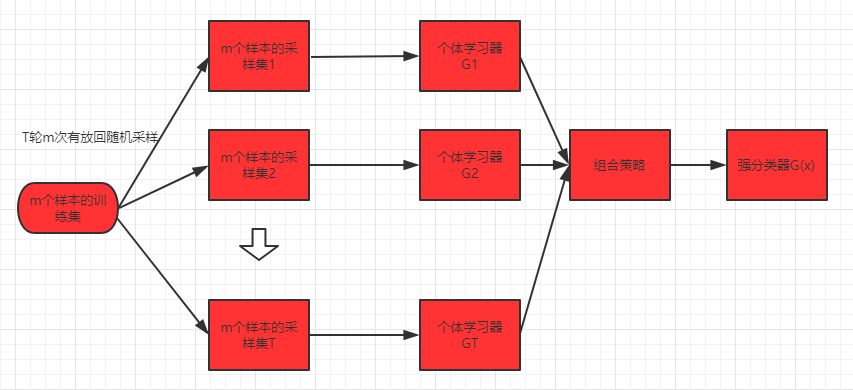
2.Bagging基本原理如图所示。要想得到泛华性较强的集成,其中每个学习器应尽量独立,在现实中无法做到,但可以设法使之差异较大。一种做法就是对训练集采样产生多个子集,对各个子集训练学习器,从而得到差异较大的学习器。但是我们还希望个体学习器不能太差,如果子集都完全不同,,每个学习器只学习到一小部分数据,无法确保产生比较好的学习器。为解决这个问题,我们考虑使用相互重叠的采用子集(有放回采样)。自主采样法:给定包含m个样本的数据集,先随机取出一个放入采样集,再放回初始训练集,使得下次采样仍然可能被选中,这样,经过m次随机采样,可以得到含m个样本的采样集,初始训练集中有样本在采样集里多次出现,有的则从未出现。关于比例很好求,求极限,63.2%出现在采样集中。预测输出时,对于分类任务使用简单投票法,回归任务使用简单平均法。
![]()
- 集成的组合策略。
- 平均法。对于回归问题一般使用平均法,分为算术平均与加权平均等。$$\begin{array}{l}
G(x) = \frac{1}{T}\sum\limits_{i = 1}^T {{G_i}} (x)\
G(x) = \sum\limits_{i = 1}^T {{\alpha _i}{G_i}} (x),{\alpha i} \ge 0;;;;\sum\limits^T {{\alpha _i} = 1}
\end{array}$$ - 投票法。对于分类问题一般使用投票法。相对多数投票法,取学习器分类结果中数目最多的类为最终类别。绝对多数投票法,票数最多,且必须大于半数。加权投票法。
- 学习法。即通过一个学习器来进行组合。Stacking为典型代表。实际上上面两种方法可以看做其中的特例。
- 平均法。对于回归问题一般使用平均法,分为算术平均与加权平均等。$$\begin{array}{l}
偏差、方差与泛化误差
- “偏差-方差分解”是解释学习算法泛化性能的一种重要工具。我们知道,算法在不同训练集上学得的结果可能不同,即便这些训练集来自同一分布。
- 对测试样本\(x\),令\(y_D\)为其在数据集D上的标记,\(y\)为其真实标记(因为由于噪声存在,会出现两者不等情况),\(f(x;D)\)为在训练集D上学得得模型\(f\)在\(x\)上的预测输出。
- 由上有学习算法的期望预测$$\bar f(x) = {{\rm E}_D}[f(x;D)]$$使用样本数相同的训练集产生的方差为$${\mathop{\rm var}} ( \cdot ) = {{\rm E}_D}[{(f(x;D) - \bar f(x))^2}]$$噪声满足$${\varepsilon ^2} = {{\rm E}_D}[{(\bar f(x) - {y_D})2}]$$期望输出与真实标记的差别称为偏差,满足$$bia{s2}( \cdot ) = {(\bar f(x) - y)^2}$$为便于讨论,假定噪声期望为0,通过简单多项式计算,可对算法的期望泛华误差进行分解,最后得到$${\rm E}(f;D) = bia{s^2} + {\mathop{\rm var}} + {\varepsilon ^2}$$
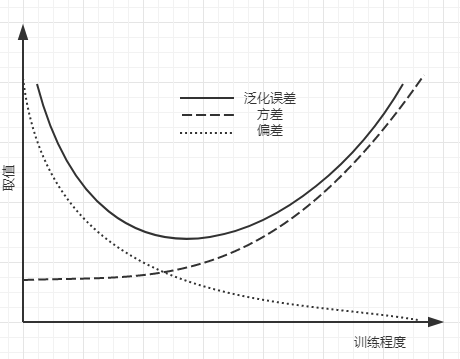
- 回顾三者含义。偏差度量学习算法的期望预测与真实结果的偏离程度,即刻画了算法本身的拟合程度。方差度量了同样大小的训练集的变动导致的预测偏离期望预测的能力(单纯从训练集来说,好的算法应该是变动较小的),刻画了数据扰动造成的影响。噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。偏差-方差分解说明,泛化性能由学习算法的能力,数据的充分性以及任务本身的难度共同决定。给定任务,为取得较好的泛化性能,则需偏差较小,即能充分拟合数据,并使方差较小,即使得数据扰动产生的误差较小。
- 一般来说,两者是有冲突的,称为“偏差-方差窘境”
![]()
- 偏差-方差分解,这种简单优美形式由[Geman et al., 1992]给出,仅在基于均方误差的回归任务中推导出,确实可以反映各种学习任务中的误差决定因素。对于分类任务,由于0/1损失函数跳变性,理论上推导出偏差-方差分解很难。但是已经有多种其他方法对偏差方差估计。
- 从偏差-方差分解角度看,Boosting主要关注降低偏差,Bagging主要关注降低方差。
关于集成学习的错误率分析以及研究核心
为便于分析,我们考虑二分类问题,正例为+1,负例为-1,真实函数为\(f\),假定基分类器错误率为\(e\),即对每个分类器\(G_i\),有$$P({G_i}(x) \ne f(x)) = e$$假设集成通过相对多数投票法结合T个分类器,因为二分类,那么超过半数学习器分类正确,集成分类器就正确,则集成分类器$$G(x) = sign(\sum\limits_{i = 1}^T {{G_i}} (x))$$假设个体学习器错误率相互独立,则由Hoeffding不等式,$$P(G(x) \ne f(x)) = \sum\limits_{i = 1}^{T/2} {\left( {\begin{array}{*{20}{c}}
T\
k
\end{array}} \right)} {(1 - e)k}{e{T - k}} \le \exp ( - \frac{1}{2}T{(1 - 2e)^2})$$上式表明,随着个体学习器数目增大,集成错误率将指数级下降,最终趋于零。
另外,我们注意到,上面的关键假设:学习器相互独立。实际上他们为解决同一问题训练出来的,显然不可能相互独立。事实上,个体学习器的准确性与多样性本身就存在冲突,如何产生并组合“好而不同”的学习器,恰恰是集成学习的研究核心。
如有错误,欢迎批评指正。转载请注明出处。沟通交流liuyingxinwy@163.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号