使用pytorch复现推荐模型-task04
多任务学习
多任务学习属于迁移学习的一种,通过共享参数,学习出多个分数,最后结合起来。典型的算法有「谷歌的 MMOE(Multi-gate Mixture-of-Experts)以及阿里的 ESMM(Entire Space Multi-Task Model)」
ESMM模型
-
解决什么问题?
- 样本选择偏差:构建的训练样本集相当于是从一个与真实分布不一致的分布中采样得到的,这一定程度上违背了机器学习中训练数据和测试数据独立同分布的假设。
- 训练数据稀疏:如下图所示,点击样本占曝光样本的很小一部分,转换样本又只占点击样本的很小一部分。
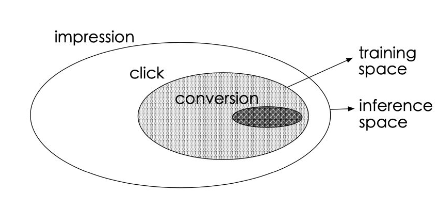
-
如何解决?
ESMM模型结构如下所示:
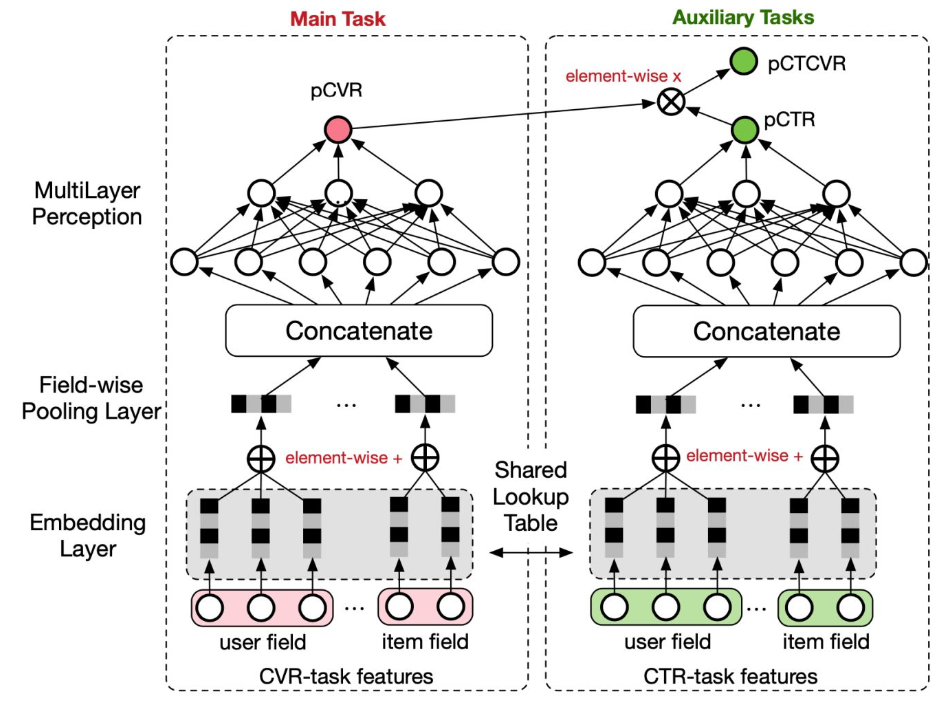
ESMM借鉴多任务学习的思路,引入两个辅助任务CTR、CTCVR(已点击然后转化),同时消除以上两个问题。
三个预测任务如下:
-
pCTR:p(click=1 | impression);
-
pCVR: p(conversion=1 | click=1,impression);
-
pCTCVR: p(conversion=1, click=1 | impression) = p(click=1 | impression) * p(conversion=1 | click=1, impression)。
三个任务之间的关系为:其中x表示曝光,y表示点击,z表示转化。
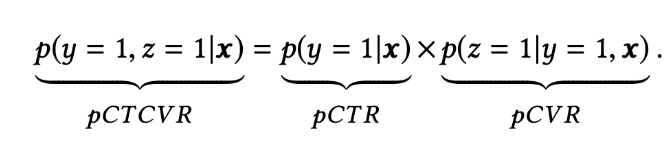
主任务和辅助任务共享特征,不同任务输出层使用不同的网络,将cvr的预测值*ctr的预测值作为ctcvr任务的预测值,利用ctcvr和ctr的label构造损失函数:
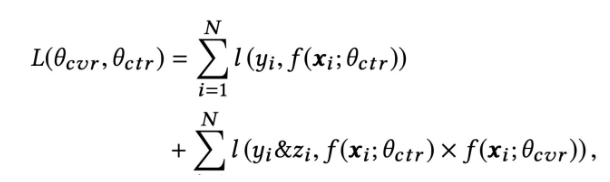
模型训练完成后,可以同时预测cvr、ctr、ctcvr三个指标,线上根据实际需求进行融合或者只采用此模型得到的cvr预估值
- 代码实现
def ESSM(dnn_feature_columns, task_type='binary', task_names=['ctr', 'ctcvr'],
tower_dnn_units_lists=[[128, 128],[128, 128]], l2_reg_embedding=0.00001, l2_reg_dnn=0,
seed=1024, dnn_dropout=0,dnn_activation='relu', dnn_use_bn=False):
features = build_input_features(dnn_feature_columns)
inputs_list = list(features.values())
sparse_embedding_list, dense_value_list = input_from_feature_columns(features, dnn_feature_columns,l2_reg_embedding,seed)
dnn_input = combined_dnn_input(sparse_embedding_list, dense_value_list)
ctr_output = DNN(tower_dnn_units_lists[0], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
cvr_output = DNN(tower_dnn_units_lists[1], dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=seed)(dnn_input)
ctr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(ctr_output)
cvr_logit = tf.keras.layers.Dense(1, use_bias=False, activation=None)(cvr_output)
ctr_pred = PredictionLayer(task_type, name=task_names[0])(ctr_logit)
cvr_pred = PredictionLayer(task_type)(cvr_logit)
ctcvr_pred = tf.keras.layers.Multiply(name=task_names[1])([ctr_pred, cvr_pred])#CTCVR = CTR * CVR
model = tf.keras.models.Model(inputs=inputs_list, outputs=[ctr_pred, cvr_pred, ctcvr_pred])
return model
MMOE模型
- 解决什么问题?
对于多个优化任务,引入了多个专家进行不同的决策和组合,最终完成多目标的预测。解决的是硬共享里面如果多个任务相似性不是很强,底层的embedding学习反而相互影响,最终都学不好的痛点。
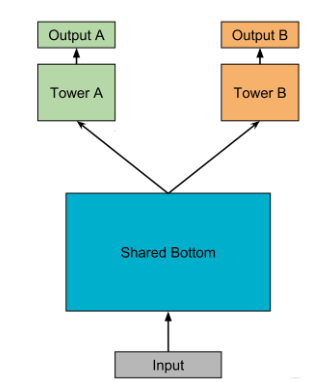
tip: 什么是硬共享?
如下图所示, 硬共享方式的底层是采用共享的隐藏层,学习各个任务的共同模式,上层用一些特定的全连接层学习特定任务模式。
-
优点:Task越多, 单任务更加不可能过拟合,即可以减少任务之间过拟合的风险;
-
缺点:底层强制的shared layers难以学习到适用于所有任务的有效表达。 尤其是任务之间存在冲突的时候。
MMOE中给出了实验结论,当两个任务相关性没那么好(比如排序中的点击率与互动,点击与停留时长),此时这种结果会遭受训练困境,毕竟所有任务底层用的是同一组参数。
- 如何解决?
MMOE模型结构图如下:
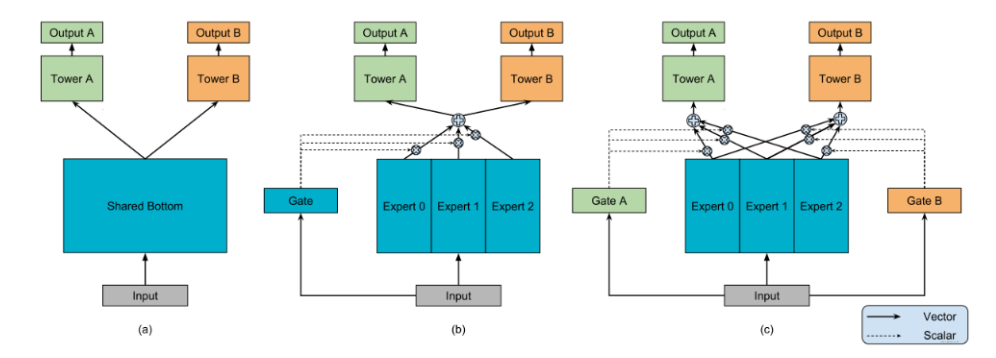
MMOE模型对每个任务都会设计一个门控网络,这样,对于每个特定的任务都会有一组对应的专家组合去进行预测,参数量也不会增加太多,公式如下:
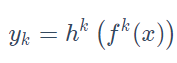
每个门控网络是一个注意力网络:
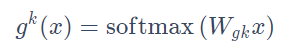
\(W_{gk}\in R^{n×d}\)表示权重矩阵, n是专家的个数, d是特征的维度。
- 代码实现?
def MMOE(dnn_feature_columns, num_experts=3, expert_dnn_hidden_units=(256, 128), tower_dnn_hidden_units=(64,),
gate_dnn_hidden_units=(), l2_reg_embedding=0.00001, l2_reg_dnn=0, dnn_dropout=0, dnn_activation='relu',
dnn_use_bn=False, task_types=('binary', 'binary'), task_names=('ctr', 'ctcvr')):
num_tasks = len(task_names)
# 构建Input层并将Input层转成列表作为模型的输入
input_layer_dict = build_input_layers(dnn_feature_columns)
input_layers = list(input_layer_dict.values())
# 筛选出特征中的sparse和Dense特征, 后面要单独处理
sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
dense_feature_columns = list(filter(lambda x: isinstance(x, DenseFeat), dnn_feature_columns))
# 获取Dense Input
dnn_dense_input = []
for fc in dense_feature_columns:
dnn_dense_input.append(input_layer_dict[fc.name])
# 构建embedding字典
embedding_layer_dict = build_embedding_layers(dnn_feature_columns)
# 离散的这些特特征embedding之后,然后拼接,然后直接作为全连接层Dense的输入,所以需要进行Flatten
dnn_sparse_embed_input = concat_embedding_list(sparse_feature_columns, input_layer_dict, embedding_layer_dict, flatten=False)
# 把连续特征和离散特征合并起来
dnn_input = combined_dnn_input(dnn_sparse_embed_input, dnn_dense_input)
# 建立专家层
expert_outputs = []
for i in range(num_experts):
expert_network = DNN(expert_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=2022, name='expert_'+str(i))(dnn_input)
expert_outputs.append(expert_network)
expert_concat = Lambda(lambda x: tf.stack(x, axis=1))(expert_outputs)
# 建立多门控机制层
mmoe_outputs = []
for i in range(num_tasks): # num_tasks=num_gates
# 建立门控层
gate_input = DNN(gate_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=2022, name='gate_'+task_names[i])(dnn_input)
gate_out = Dense(num_experts, use_bias=False, activation='softmax', name='gate_softmax_'+task_names[i])(gate_input)
gate_out = Lambda(lambda x: tf.expand_dims(x, axis=-1))(gate_out)
# gate multiply the expert
gate_mul_expert = Lambda(lambda x: reduce_sum(x[0] * x[1], axis=1, keep_dims=False), name='gate_mul_expert_'+task_names[i])([expert_concat, gate_out])
mmoe_outputs.append(gate_mul_expert)
# 每个任务独立的tower
task_outputs = []
for task_type, task_name, mmoe_out in zip(task_types, task_names, mmoe_outputs):
# 建立tower
tower_output = DNN(tower_dnn_hidden_units, dnn_activation, l2_reg_dnn, dnn_dropout, dnn_use_bn, seed=2022, name='tower_'+task_name)(mmoe_out)
logit = Dense(1, use_bias=False, activation=None)(tower_output)
output = PredictionLayer(task_type, name=task_name)(logit)
task_outputs.append(output)
model = Model(inputs=input_layers, outputs=task_outputs)
return model

 浙公网安备 33010602011771号
浙公网安备 33010602011771号