使用pytorch复现推荐模型-task3
一、经典召回模型
虽然深度学习发展的非常火热,但是协同过滤、逻辑回归、因子分解机等传统推荐模型仍然凭借其可解释性强、硬件环境要求低、易于快速训练和部署等不可替代的优势,拥有大量适用的应用场景。传统推荐模型仍然是深度学习推荐模型的基础,如图1所示是传统推荐模型的演化关系图。根据图为索引,总结一些经典的召回模型。
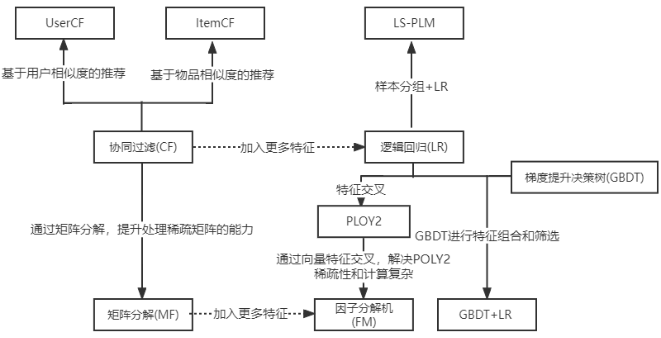
图1 传统推荐系统模型演化关系图
1.1 基于协同过滤的召回
协同过滤(Collaborative Filtering)推荐算法是推荐系统中最经典也是做常用的推荐算法,其基本思想是根据目标用户之前的喜好和与用户兴趣相近的用户的喜好来给目标用户推荐物品。目前比较常用的协同过滤算法分为基于用户的协同过滤(UserCF)算法和基于物品的协同过滤算法(ItemCF)。UserCF负责给目标用户推荐和他兴趣相似的其他用户喜欢的且目标用户没有接触过的item,ItemCF负责给目标用户推荐和他之前喜欢过的物品相似的物品。不管是基于用户还是基于物品的协同过滤推荐算法,其中关键的一步就是用户之间或者物品之间的相似度计算。
1.2 基于向量的召回
在基于向量的召回算法中,FM召回、item2vec召回系列、YouTubeDNN召回和双塔模型是其中最经典的模型。FM模型在协同过滤算法和逻辑回归模型的基础上,加入了二阶特征交互,使得模型具有了特征组合的能力。Item2vec召回系列包括了Word2vec召回、item2vec召回[5]和Airbnb召回。
Word2vec召回是一个用来学习dense word vector的算法,该算法通过使用大量的文本语料库,库中的每个单词都由一个词向量dense word vector来表示,在遍历文本的每个位置时,都会有一个中心词和上下文词,在整个语料库上使用数学法学将最大化上下文单词,从而得到的单词表中每一个单词的dense vector,不断地调整词向量dense Word vector以达到最好的效果。
在论文 Item2Vec:Neural Item Embedding for Collaborative Filtering 中,作者受到 SGNS 的启发,提出了名为 Item2Vec 的方法来生成物品的向量表示,然后将其用于基于物品的协同过滤。Item2Vec 论文假设对于一个集合的物品,它们之间是相似的,与用户购买它们的顺序、时间无关。当然,该假设在其他场景下不一定使用,但是原论文只讨论了该场景下它们实验的有效性。由于忽略了空间信息,原文将共享同一集合的每对物品视为正样本。
Airbnb召回模型使用 Embedding 来实现相似房源推荐以及实时个性化搜索。Airbnb 在用户和房源的 Embedding 上的生成都是基于谷歌的 Word2Vec 模型,并描述了两种 Embedding 的构建方法,分别为:用于描述短期实时性的个性化特征 Embedding:listing Embeddings和用于描述长期的个性化特征 Embedding:user-type & listing type Embeddings。
YouTubeDNN模型是工业界论文的典范,为了解决从大量的YouTube视频中检索出数百个和用户相关的视频来,该模型将其看作是一个二分类的问题,即用户在某一时刻点击了某个视频,可以建模成输入一个用户向量,从海量视频中预测出被点击的那个视频的概率。
1.3 基于图的召回
在基于图的召回模型中最经典的模型包括EGES召回模型和PinSAGE模型。EGES召回模型是由阿里巴巴于18年在KDD会议上发表的关于召回阶段的工作。由于传统的推荐系统方法无法扩展到拥有十亿的用户甚至二十亿商品的淘宝中;且所存在的用户与物品的交互行为稀疏,用户的交互大多集中在热门物品,有大量的不热门的物品很少被用户交互;除此之外,在淘宝中,每分钟都会上传很多新的商品,但是这些商品由于没有与用户进行很好地交互,推荐系统无法为用户进行很好地推荐。出于传统推荐模型具有以上可扩展性差、数据稀疏性和冷启动的问题,该模型基于图嵌入的方法,通过引入side information来解决实际问题中的数据稀疏和冷启动问题。在可扩展性方面,图嵌入的随机游走方式可以在物品图上捕获物品之间高阶相似性,该方法不同于CF方法,除了考虑物品的共现,还考虑到了行为的序列信息。在数据具有稀疏性和物品冷启动方面,该模型在图嵌入的基础上,考虑了节点的属性信息。希望通过头部物品,来提高属性信息的泛化能力,进而帮助尾部和冷启物品获取更准确的embedding表示。考虑到不同属性信息对于学习embedding的贡献不同,在聚合不同的属性信息时,动态的学习了不同属性对于学习节点的embedding所参与的重要性权重。
对于PinSAGE模型,该模型是在GraphSAGE的理论基础进行了更改,以适用于实际的工业场景。PinSAGE 模型主要应用的思路是,基于GraphSAGE 的原理学习到聚合方法,并为每个图片(pin)学习一个向量表示,然后基于pin的向量表示做item2item的召回。PinSAGE 除了改进卷积操作中的邻居采样策略以及聚合函数的同时还有一些工程技巧上的改进,使得在大数据场景下能更快更好的进行模型训练。
1.4 基于序列的召回
基于序列的召回中的经典模型包括MIND模型和SDM模型。MIND模型(Multi-Interest Network with Dynamic Routing),是基于天猫APP的背景来对十亿级别的用户进行个性化推荐。论文中提出的MIND模型是应用在召回阶段的工作,考虑到用户的兴趣存在多样性,模型通过使用多个向量来表示用户的兴趣,即在召回阶段建立用户多兴趣模型来模拟用户的多样化数据。
对于SDM(Sequential Deep Matching Model)模型,是如何通过用户的历史行为序列去学习到用户的丰富兴趣。SDM模型把用户的历史序列根据交互的时间分成了短期和长期两类,然后从短期会话和长期行为中分别采取相应的措施(短期的RNN+多头注意力,长期的注意力网络)去学习到用户的短期兴趣和长期行为偏好,并巧妙的设计了一个门控网络有选择的将长短期兴趣进行融合,以此得到用户的最终兴趣向量。 这篇paper中的一些亮点,比如长期偏好的行为表示,多头注意力机制学习多兴趣,长短期兴趣的融合机制等,提供了看待问题的新角度,同时,给出了一种利用历史行为序列去捕捉用户动态偏好的新思路。
1.5 基于树模型的召回
前面所提及的协同过滤技术只能通过用户的历史行为进行建模,由于算力的限制会导致推荐结果的多样性和新颖性比较局限,造成给用户推荐的item可能是用户之前看过或者购买过的商品。在Facebook开源了FASSI库之后,基于内积的模型得到了广泛的应用,召回技术发展到了第二代召回技术,这种技术通过将用户和物品用向量表示,然后用内积的大小度量兴趣,借助向量索引实现大规模的全量检索。但是这种模式仍然存在索引构建和优化目标不一致的问题,于是阿里开发了一种可以承载各种深度模型来检索用户潜在兴趣的推荐算法解决方案。这个TDM模型是基于树结构,利用树结构对全量商品进行检索,将复杂度由O(N)下降到O(logN)。
二、部分召回模型详解
2.1 YouTubeDNN召回模型
- 模型结构
如图2所示,YouTube的视频推荐分了召回和精排两个阶段:
- 召回阶段:负责从大量的视频中挑选成千上百个用户可能感兴趣的视频
- 精排阶段:对召回阶段召回的视频进行排序,最后将前k个视频推荐给目标用户
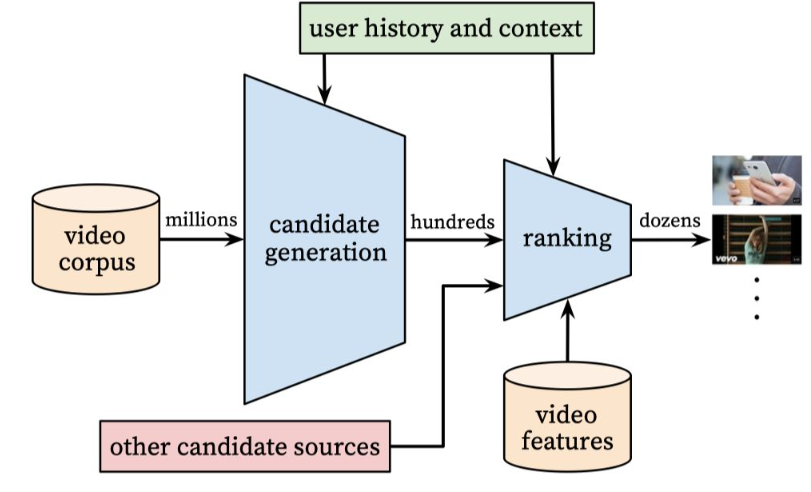
图2 YouTubeDNN模型结构
如图 3 所示是YouTube视频推荐的召回阶段,召回阶段的目标是为每个用户生成1个user vector(利用用户的历史数据行为和上下文特征,经过多层神经网络的输出就是user vector)和为每个视频生成1个video vector(采用的是类似word2vec的方法生成)。然后利用公式\(P(w_t=i|U,C)=\frac {e^{v_iu}}{\sum_{j\in V} e^{v_ju}}\) 计算用户 u 对视频 v 的感兴趣程度。
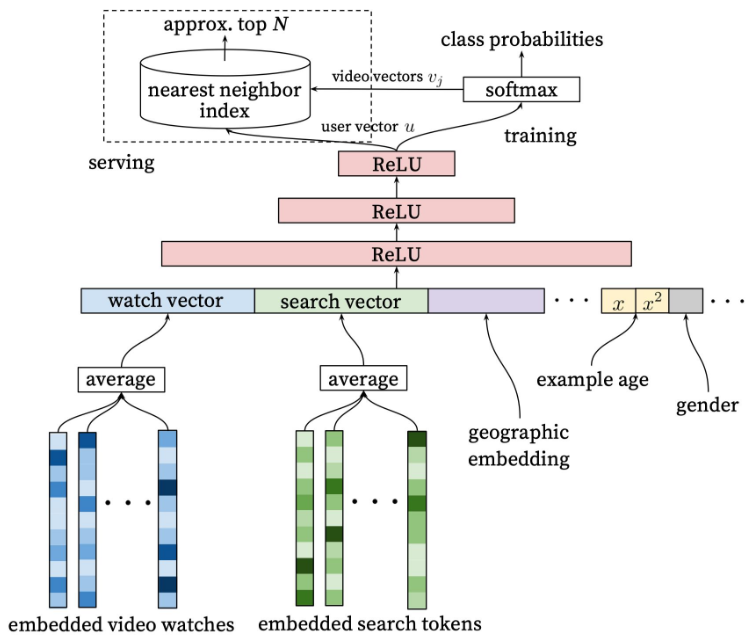
图3 YouTubeDNN模型召回部分
- 模型实现
class YoutubeDNN(torch.nn.Module):
def __init__(self, user_features, item_features, neg_item_feature, user_params, temperature=1.0):
super().__init__()
self.user_features = user_features
self.item_features = item_features
self.neg_item_feature = neg_item_feature
self.temperature = temperature
self.user_dims = sum([fea.embed_dim for fea in user_features])
self.embedding = EmbeddingLayer(user_features + item_features)
self.user_mlp = MLP(self.user_dims, output_layer=False, **user_params)
self.mode = None
def forward(self, x):
user_embedding = self.user_tower(x)
item_embedding = self.item_tower(x)
if self.mode == "user":
return user_embedding
if self.mode == "item":
return item_embedding
# 余弦相似度
y = torch.mul(user_embedding, item_embedding).sum(dim=2)
y = y / self.temperature
return y
def user_tower(self, x):
if self.mode == "item":
return None
input_user = self.embedding(x, self.user_features, squeeze_dim=True)
user_embedding = self.user_mlp(input_user).unsqueeze(1)
user_embedding = F.normalize(user_embedding, p=2, dim=2)
if self.mode == "user":
return user_embedding.squeeze(1)
return user_embedding
def item_tower(self, x):
if self.mode == "user":
return None
pos_embedding = self.embedding(x, self.item_features, squeeze_dim=False)
pos_embedding = F.normalize(pos_embedding, p=2, dim=2)
if self.mode == "item":
return pos_embedding.squeeze(1)
neg_embeddings = self.embedding(x, self.neg_item_feature, squeeze_dim=False).squeeze(1)
neg_embeddings = F.normalize(neg_embeddings, p=2, dim=2)
return torch.cat((pos_embedding, neg_embeddings), dim=1)
2.2DSSM召回模型
-
模型结构
双塔模型结构如图4所示,左侧是user塔,右侧是Item塔,可将特征拆分为两大类:用户相关特征(用户基本信息、群体统计属性以及行为过的Item序列等)与Item相关特征(Item基本信息、属性信息等。对于这两个塔本身,则是经典的DNN模型,从特征OneHot到特征Embedding,再经过几层MLP隐层,两个塔分别输出用户Embedding和Item Embedding编码。在训练过程中,User Embedding和Item Embedding做内积或者Cosine相似度计算,使得用户和正例Item在Embedding空间更接近,和负例Item在Embedding空间距离拉远。损失函数可用标准交叉熵损失,将问题看做一个分类问题。
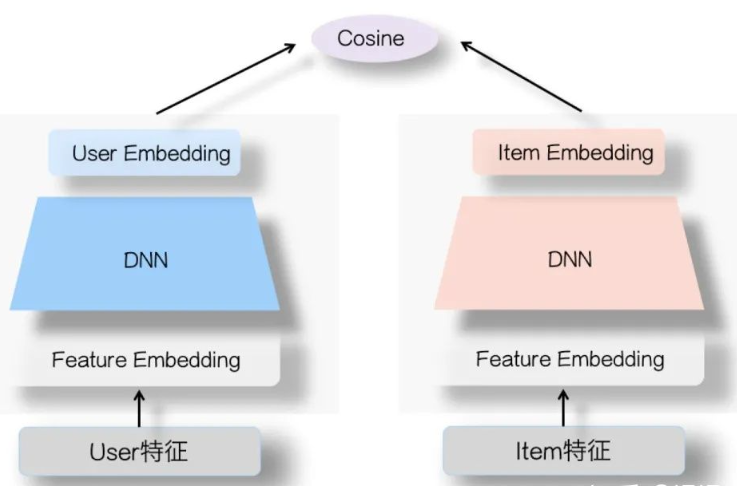
图4 双塔模型结构 -
模型实现
class DSSM(torch.nn.Module):
def __init__(self, user_features, item_features, user_params, item_params, temperature=1.0):
super().__init__()
self.user_features = user_features
self.item_features = item_features
self.temperature = temperature
self.user_dims = sum([fea.embed_dim for fea in user_features])
self.item_dims = sum([fea.embed_dim for fea in item_features])
self.embedding = EmbeddingLayer(user_features + item_features)
self.user_mlp = MLP(self.user_dims, output_layer=False, **user_params)
self.item_mlp = MLP(self.item_dims, output_layer=False, **item_params)
self.mode = None
def forward(self, x):
user_embedding = self.user_tower(x)
item_embedding = self.item_tower(x)
if self.mode == "user":
return user_embedding
if self.mode == "item":
return item_embedding
#余弦相似度
y = torch.mul(user_embedding, item_embedding).sum(dim=1)
return torch.sigmoid(y)
def user_tower(self, x):
if self.mode == "item":
return None
input_user = self.embedding(x, self.user_features, squeeze_dim=True)
user_embedding = self.user_mlp(input_user)
user_embedding = F.normalize(user_embedding, p=2, dim=1)
return user_embedding
def item_tower(self, x):
if self.mode == "user":
return None
input_item = self.embedding(x, self.item_features, squeeze_dim=True)
item_embedding = self.item_mlp(input_item)
item_embedding = F.normalize(item_embedding, p=2, dim=1)
return item_embedding

 浙公网安备 33010602011771号
浙公网安备 33010602011771号