动手学数据分析-task2
第二章 数据分析的基本流程
第一节 数据清洗和特征处理
1. 概述
数据清洗(Data cleaning)- 对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。 数据清洗从名字上也看的出就是把"脏"的"洗掉",指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。
import numpy as np
import pandas as pd
df = pd.read_csv("data/train.csv")
df.head()
1.1 缺失值观察与处理
任务一:观察缺失值
- 方法一:
df.info()
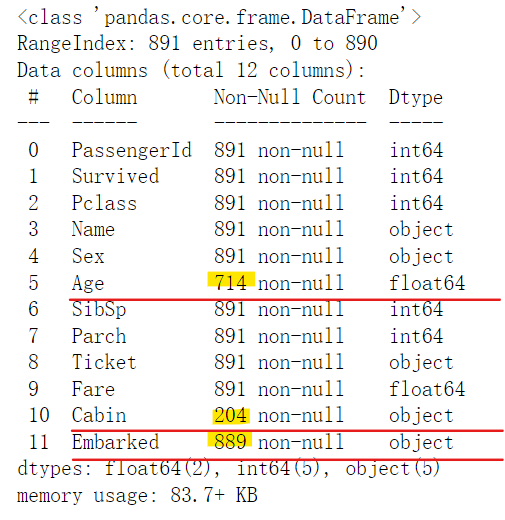
- 方法二:
df.isnull().sum()
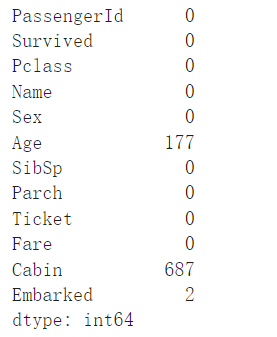
任务二:对缺失值进行处理
处理方式:
- 方式一:
df[df['Age']==None]=0
df.head(3)
- 方式二:
df[df['Age'].isnull()] = 0
df.head(3)
- 方式三:
df[df['Age'] == np.nan] = 0
df.head()
- 方式四:使用 pandas.DataFrame.dropna()函数,默认将包含空值的行删除。[pandas.DataFrame.dropna — pandas 1.4.2 documentation (pydata.org)]
df.dropna().head(3)
- 方式五:使用pandas.DataFrame.fillna()函数,默认将空值用 0 填充
df.fillna(0).head(3)
【思考】检索空缺值用np.nan,None以及.isnull()哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
【回答】数值列读取数据后,空缺值的数据类型为float64所以用None一般索引不到,比较的时候最好用np.nan;
使用完各种方法后最好检查一下空值是否修改成了0,如果没有就换一种方式
1.2 重复值观察和处理
任务一:查看数据中的重复值
df[df.duplicated()]
任务二:对重复值进行处理
方式有很多,下面只是介绍了一个例子
对整个行有重复值的清理的方法举例:
df = df.drop_duplicates()
任务三:将前面清洗的数据保存为csv格式
df.to_csv('data/test_clear.csv')
2 特征观察与处理
我们对特征进行一下观察,可以把特征大概分为两大类:
- 数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征
- 文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征。
数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
2.1 离散化
任务一:对年龄进行分箱(离散化)处理
(1) 分箱操作是什么?
(2) 将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
#将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'], 5,labels = [1,2,3,4,5])
(3) 将连续变量Age划分为(0,5] (5,15] (15,30] (30,50] (50,80]五个年龄段,并分别用类别变量12345表示
#将连续变量Age按10% 30% 50 70% 90%五个年龄段,并用分类变量12345表示
df['AgeBand'] = pd.cut(df['Age'],[0,5,15,30,50,80],labels = [1,2,3,4,5])
(4) 将连续变量Age按10% 30% 50% 70% 90%五个年龄段,并用分类变量12345表示
#将连续变量Age按10% 30% 50 70% 90%五个年龄段,并用分类变量12345表示
df['AgeBand'] = pd.qcut(df['Age'],[0,0.1,0.3,0.5,0.7,0.9],labels = [1,2,3,4,5])
(5) 将上面的获得的数据分别进行保存,保存为csv格式
df.to_csv('data/test_pr.csv')
任务二:对文本变量进行转换
(1) 查看文本变量名及种类
#查看类别文本变量名及种类
#方法一: value_counts
df['Sex'].value_counts()
#方法二: unique
df['Sex'].unique()
(2) 将文本变量Sex, Cabin ,Embarked用数值变量12345表示
#将类别文本转换为12345
#方法一: replace
df['Sex_num'] = df['Sex'].replace(['male','female'],[1,2])
df.head()
#方法二: map
df['Sex_num'] = df['Sex'].map({'male': 1, 'female': 2})
df.head()
#方法三: 使用sklearn.preprocessing的LabelEncoder
from sklearn.preprocessing import LabelEncoder
for feat in ['Cabin', 'Ticket']:
lbl = LabelEncoder()
label_dict = dict(zip(df[feat].unique(), range(df[feat].nunique())))
df[feat + "_labelEncode"] = df[feat].map(label_dict)
df[feat + "_labelEncode"] = lbl.fit_transform(df[feat].astype(str))
df.head()
(3) 将文本变量Sex, Cabin, Embarked用one-hot编码表示
#将类别文本转换为one-hot编码
#方法一: OneHotEncoder
for feat in ["Age", "Embarked"]:
x = pd.get_dummies(df[feat], prefix=feat) # get_dummies()是抽特征的方法,详解见官网
df = pd.concat([df, x], axis=1)
df.head()
任务三(附加):从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
df['Title'] = df.Name.str.extract('([A-Za-z]+)\.', expand=False)
df.head()
第二节 数据重构
# 载入data文件中的:train-left-up.csv
text = pd.read_csv('/Users/chenandong/Documents/datawhale数据分析每个人题目设计/招募阶段/第二章项目集合/data/train-left-up.csv')
text.head()
1. 数据的合并
任务一:将data文件夹里面的所有数据都载入,与之前的原始数据相比,观察他们的之间的关系
text_left_up = pd.read_csv("data/train-left-up.csv")
text_left_down = pd.read_csv("data/train-left-down.csv")
text_right_up = pd.read_csv("data/train-right-up.csv")
text_right_down = pd.read_csv("data/train-right-down.csv")
任务二:使用concat方法:将数据train-left-up.csv和train-right-up.csv横向合并为一张表,并保存这张表为result_up
list_up = [text_left_up,text_right_up]
result_up = pd.concat(list_up,axis=1)
result_up.head()
任务三:使用concat方法:将train-left-down和train-right-down横向合并为一张表,并保存这张表为result_down。然后将上边的result_up和result_down纵向合并为result
list_down=[text_left_down,text_right_down]
result_down = pd.concat(list_down,axis=1)
result = pd.concat([result_up,result_down])
result.head()
任务四:使用DataFrame自带的方法join方法和append:完成任务二和任务三的任务
resul_up = text_left_up.join(text_right_up)
result_down = text_left_down.join(text_right_down)
result = result_up.append(result_down)
result.head()
任务五:使用Panads的merge方法和DataFrame的append方法:完成任务二和任务三的任务
result_up = pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down = pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
result = resul_up.append(result_down)
result.head()
【思考】对比merge、join以及concat的方法的不同以及相同。思考一下在任务四和任务五的情况下,为什么都要求使用DataFrame的append方法,如何只要求使用merge或者join可不可以完成任务四和任务五呢?
任务六:完成的数据保存为result.csv
result.to_csv('result.csv')
2. 换一种角度看数据
任务一:将我们的数据变为Series类型的数据
这个stack函数是干什么的?
# 将完整的数据加载出来
text = pd.read_csv('result.csv')
text.head()
# 代码写在这里
unit_result=text.stack().head(20)
unit_result.head()
#将代码保存为unit_result,csv
unit_result.to_csv('unit_result.csv')
test = pd.read_csv('unit_result.csv')
3. 数据聚合与运算
Groupby 函数:
-
groupby函数功能
:根据一个或多个键拆分pandas对象,计算分组摘要统计,如计数、平均值、标准差或用户自定义函数等。 -
groupby函数原理
:可将 groupby 函数分组聚合的过程分为两步:- 分组split:按照指定键值或分组变量对数据分组
- 聚合combine:应用python自带函数或自定义函数进行聚合计算
第三节 数据可视化
-
Matplotlib:它可以很轻松地画一些或简单或复杂地图形,几行代码即可生成线图、直方图、功率谱、条形图、错误图、散点图等等。
- matplotlib官网:Matplotlib — Visualization with Python
- win安装方法:pip install matplotlib
-
Seaborn:如果单单使用matplotlib会显示非常简单,不够美观。Seaborn是基于matplotlib产生的一个模块,专攻于统计可视化,可以和pandas进行无缝链接,初学者很容易上手。相对于matplotlib,Seaborn语法更简洁,两者关系类似于numpy和pandas之间的关系。它能够让绘制图像的样式更加丰富。
- seabom官网:http://seaborn.pydata.org/
- win安装方法:pip install seaborn
等等各种python数据可视化工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号