

python模块学习心得
初始模块
1.什么是模块
模块是用来实现某项功能的一大堆代码,为什么会有模块呢?过程式编程的时候为了减少程序员编程代码的重复性,就利用函数的调用减少了代码的重复性,但是某些时候程序会过于的庞大,我们会用到很多很多
的函数,同样是为了方便,我们就把某些函数在一起共同产生的一些功能放在同一个py文件里面,这个py文件就称为一个模块,或者多个py文件在一个文件夹里面,这个文件夹也称为一个模块。模块的功能和函数
一样是可以调用的。
库和模块的关系:一个库可以有很多模块,但一个库最少有一个模块。
2.模块的导入
在我们执行一个模块的时候,python会自己去调用sys里面的功能,让我们所在的py文件调用其它的py文件。并且我们还可以添加它搜寻文件时候的路径

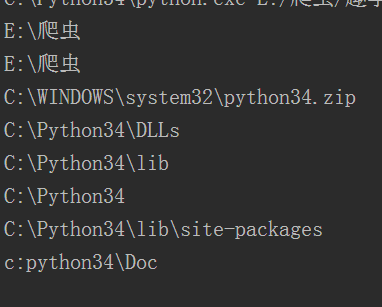
注意有两个爬虫目录的原因是pycharm会多找一次,正在调用其它文件的py文件的上一层目录,由于正在执行的趣学.py是在爬虫目录下面的,然而爬虫上面已经没有目录了,所以才会有第一个和第二个搜索都是
爬虫目录,但是这样的搜索仅限于pycharm。正常第一次就执行文件所在目录。代码的第二行是添加搜索路径的功能,在执行的时候所添加的路径在最后一行。
3.模块的调用
模块的调用主要有两种方法:


注意在导入模块的时候用''.''一步一步的深入到文件所在的模块,但是这种直接用import的方法在调用模块内部函数的时候很麻烦,每次都要把导入路径重复
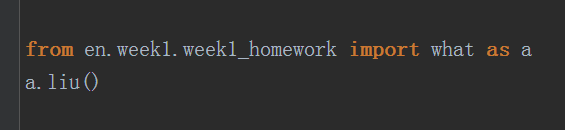
如果用from导入的话,就可以直接用py文件的名字调用内部的函数,或者命名py文件以后用新名字调用内部的函数。
4.模块的分类
- 自定义模块
- 内置模块
- 第三方模块
内置模块:python自己带有的模块
自定义模块:为了满足需要程序员自己写的模块
第三方模块:由全世界的程序员所写的模块,可以在专有的服务器上面下载
5.time模块
sleep():控制时间

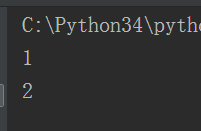
输出1以后,等5秒的时间再输出2
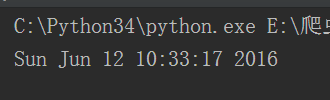
time():时间戳,表示从1970到现在一共用了多少秒
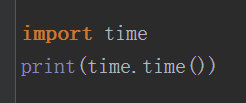
ctime()返回当前时间,并且以字符串格式
将时间戳转换为当前时间的字符串
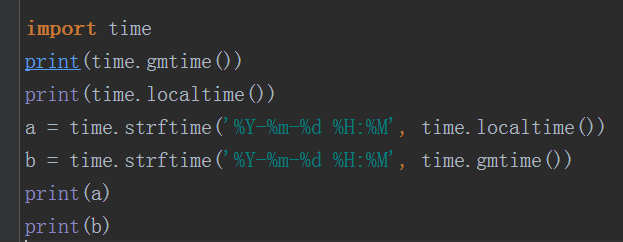
gmtime()返回一个时间结构,里面可以放时间戳
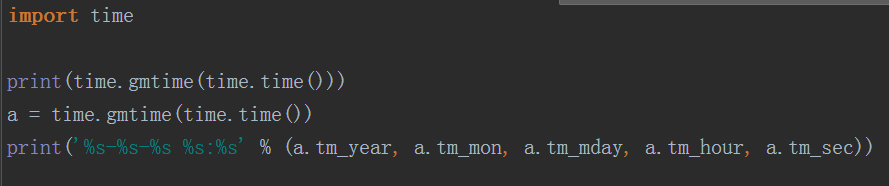

时间戳对应的时间是格林威治时间和中国差8个小时左右
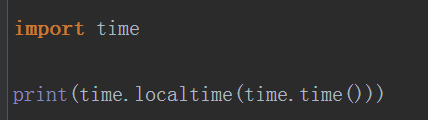
localtime():输出本地的时间

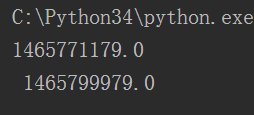
mktime():将时间对象转化为时间戳

strftime:将时间对象转化为字符串格式
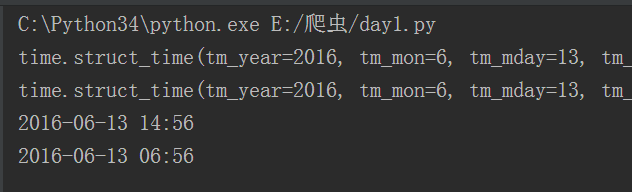
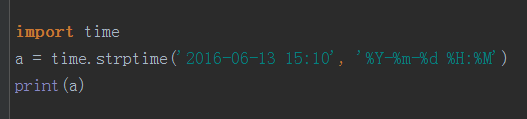
strptime:将字符串格式转化为时间对象

6.sys模块
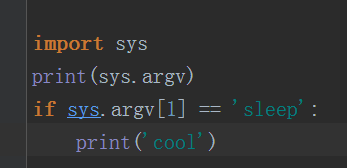
agrv:获取给脚本传人的参数
在pycharm里面运行

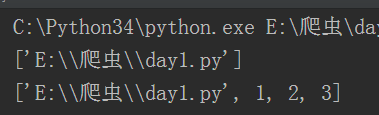
在终端里面运行,在执行py文件的时候就传人参数

exit():结束程序并且可以在()里面传入参数

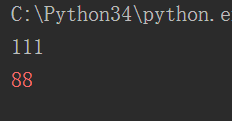
version:python的版本

platform:系统的架构平台

sys.stdout.write()输出相关
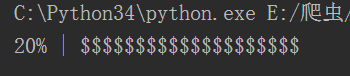
做一个进度条



注意
sys.stdout.write('\r')是清空内存,不让%%%%%。。堆积起来
sys.stdout.flush() 是强制刷新内存缓冲区,让$一个一个的打印出来,要不缓冲区会堆积到一定的数量以后,一起打印出来
7.datatime模块
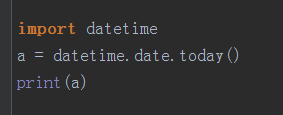
date.today():输出当前时间
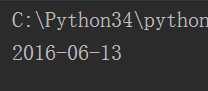
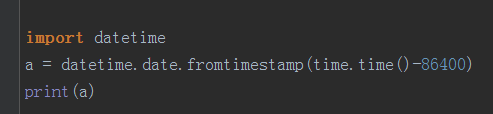
date.fromtimestamp():将时间戳转化为字符串格式
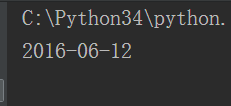
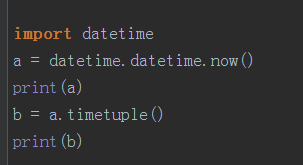
datatime.now输出当前时间 ,timetuple:将对象转化为一个时间对象

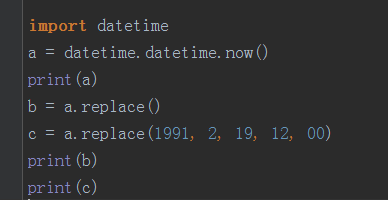
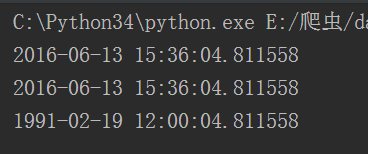
当前时间 . replace()括号里面没有参数则表示当前时间,有参数则参数更换当前时间。
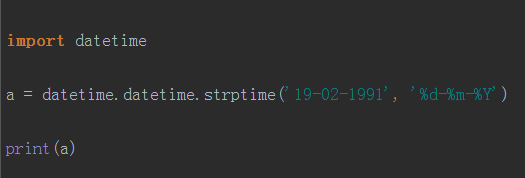
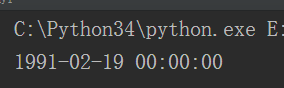
datetime.strptime():将输入的日期字符串格式化
datetime.strftime():datatime.date的对象,进行时间格式化
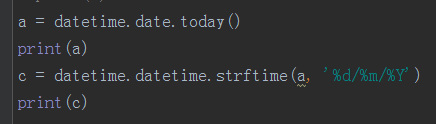

注意Y表示year,m表示month,d表示day,M表示minute,H表示hour
datetime.timedelta:改变时间的增量
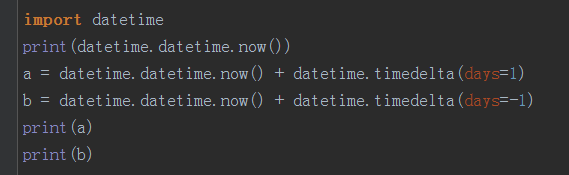
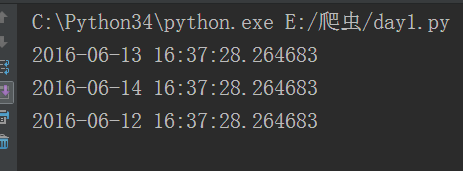
前面的+-号和后面的一起组合形成增量的正负,如果前后都是-号则,则实际是增加的。

这些是可以用来做增量的参数
8.pickle模块
将python的基本数据类型,转换为字节的形式,这样可以保存在文件里面。
dumps和loads可以直接用来转换


dump和load可以直接带文件,但是dump和load只能在文件里面操作
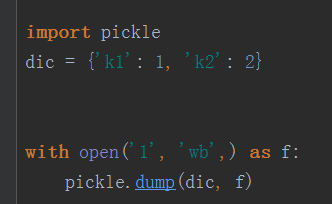

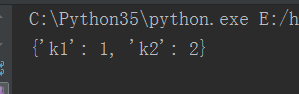
注意用pickle模块以后产生的字节直接写到文件里面,不要加encoding='utf-8',会报错,因为它不是用utf-8编码进去的
pickle只能和python在网上交互
9.json模块
将基本数据类型转换为字符串的类型,dump,dumps,load,loads功能与pickle相同


load和dunm需要带文件操作,json可以和其它语言在网上交互。
10.random模块
利用random模块可以取的规定范围内的随机数

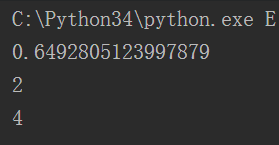
randrange是左闭右开区间,而randint是全部闭区间。
11.re模块
re模块是为了给python引入正则表达式的模块
正则表达式是为了匹配输入的字符串里面某些相应的元素而存在的,这样就可以从一大串字符串里面取出我们想要的元素
字符:
- ''.'' 匹配除换行符以外的任意字符
- \w 匹配数字,字母,下划线,汉字
- \s 匹配任意的空白字符
- \d 匹配数字
- ^ 匹配字符串的开始
- $ 匹配字符串的结束
- [] 字符集,里面代表或的意思 并且^在里面表示非的意思
- \表示除去元字符的特殊意义,变成普通字符
次数:
- * 重复0次和多次
- + 重复1次和多次
- ?重复0次和1次
- {n} 重复n次
- {n:}重复n到多次
- {n:m}重复n到m次
匹配的方法:
match:从头开始匹配,匹配成功返回值,未成功返回一个none
research:游览全部字符串,找到第一符合匹配条件的元素然后返回,如果没有则返回none
findall:游览全部字符串,找到全部符合匹配条件的元素然后全部放在一个列表里面,如果没有则返回none
finditer:可以迭代的findall
match,research,findall,都有两种匹配方式,第一种是正常匹配,第二种是分组匹配
match:


match产生的对象想要拿出匹配的数据,必须用group。group有三次方式拿出数据。全拿,元组,字典。
group在显示匹配元素的时候,可以传人参数进行修改元素的内容
在group参数最后可以传人I ,M ,S,X
- I 忽略匹配元素的大小写
- M 可以进行多行匹配(正常只能匹配一行)
- S 让''.'' 可以匹配任何字符(以前不能匹配换行符)
- X 可以对匹配的对象进行注释 ,一般不会用,例如正常字符串里面是有空格的,一旦用了X则正则表达式里面的空格就会消失 。
search:
search与match功能相同,唯一的区别search不用开头就是匹配正确,它是游览整个字符串之后匹配到第一个符合匹配的元素


findall:
将找到合适的元素全部放到一个列表里面
相对于match和search只匹配一个元素,但是findall是匹配多个元素,一旦匹配成功一个,后面接着匹配的时候,是按照前面匹配成功的最后一个字符后面的第一个字符进行匹配的
如果匹配的是一个空字符串,则也会进行匹配,就把空放在列表里面
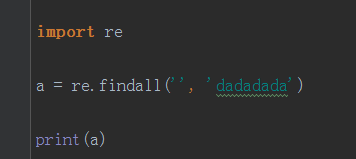
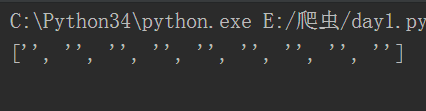
一旦没找到就会返回空值,而且会多一个空值
findall分组的时候,如果是只括号在外面里面没有这列表不会又改变,如果里面有则列表会产生改变



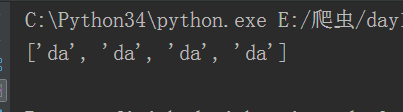


注意:findall默认都是groups里面的元素,所以?P<N1>这样的符号在里面不起作用
\(W)\(W)\(W)\(W)和\(W){4}的区别
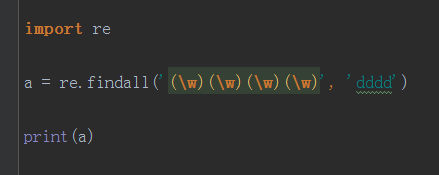
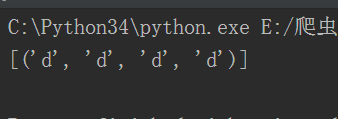
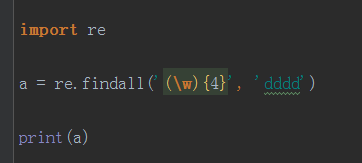
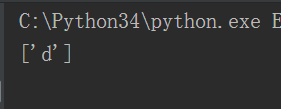
虽然都是重复4次,但是关键在于表达式里面,一个含有4个\(W)一个实际含有一个\(W),所以虽然含有一个\(W)也是表示4次但是它只是逻辑上面的4次,表达式里面只有一个\(W),所以默认取最后一个。
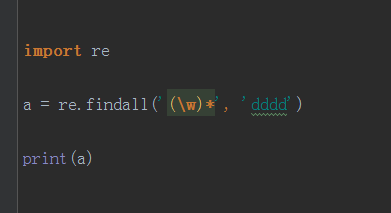
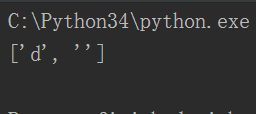
*的贪婪匹配让结果多获得了一个空元素,因为findall是由groups组成\w是全部拿到,(\w)只拿到groups里面,后面再加一个*或者{次数},
相当于将对应的字符串继续往后面去拿元素到groups里面前面拿的元素就只是一个过程,要看最后拿的是那个元素到groups里面

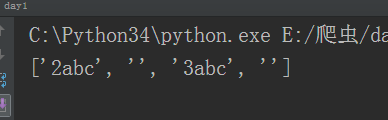
这里的*和{次数}是一样的,由于1abc2abc重复了,所以只取最后一个元素,中间没有匹配成功的变成空字符串,最后多加一个空字符串
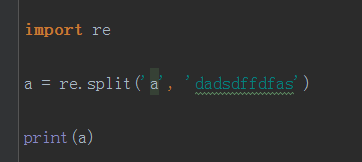
split:分割字符串
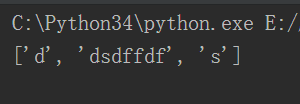
sub:代替字符串

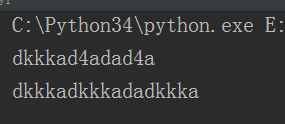
最后一个是控制被替换字符串的个数
注意分组是为了获得匹配里面的特别元素
12.os模块
系统模块
13.xml模块
处理xml格式的模块
14.hashlib模块
hashlib模块为加密模块, 提供了md5 ,sha1 ,sha224,sha256,sha384,sha512加密算法
MD5:

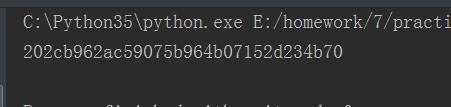
这种加密方法可以通过撞库得到密码

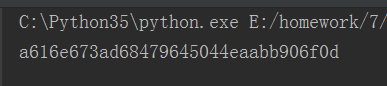
这种第二次的加密,撞库就无法得到
SHA1:
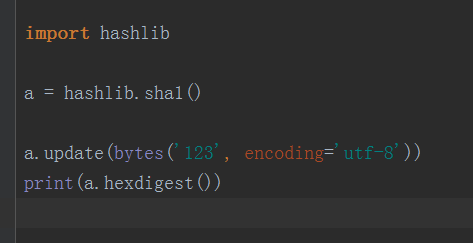


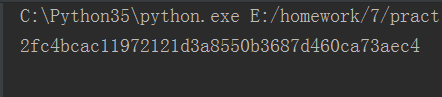
15:requests模块
requsets模块提供了http的请求代码,里面封装的是python标准库提供的urlib模块,使用requests可以轻易的发出网络请求,游览网络
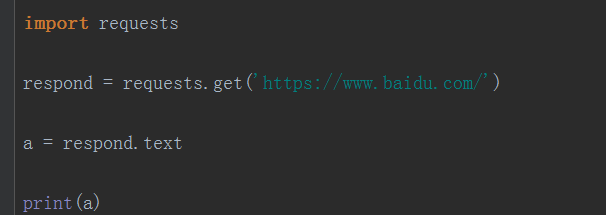
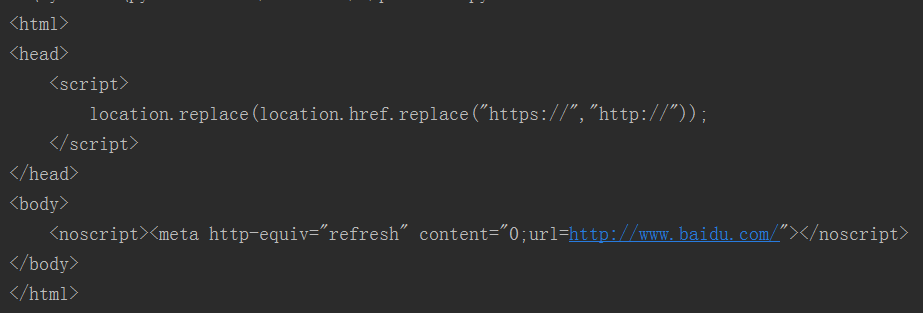
像requests这种第三方安装模块的时候
pip3 install requests
16.configparser模块
configparser用于处理特点格式的文件,其本质利用open来操作文件
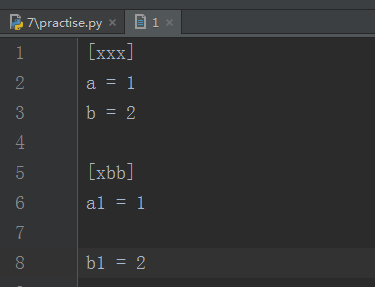

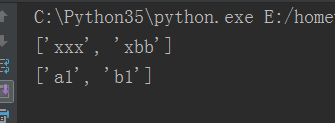
17.shutil模块
高级的文件 文件夹 压缩包处理模块
18.subprocess模块
shell命令相关模模块
19.logging模块
记录文件的模块,也可以叫日志模块

