MYSQL常用查询
一、MYSQL查询的五种子句
where(条件查询)、having(筛选)、group by(分组)、order by(排序)、limit(限制结果数)
【1】where:
比较运算符 > , < ,= , != (< >),>= , <= in(param1,param2...paramN) between param1 and param2在param1至param2之间(包含param1,param2) 逻辑运算符 not ( ! ) 逻辑非 or ( || ) 逻辑或 and ( && ) 逻辑与 模糊查询 like 像 通配符: % 任意字符 _ 单个字符 where goods_name like 'TOM%' where goods_name like 'TOM__'
【2】having查询
having与where类似,可以筛选数据,where后的表达式怎么写,having后就怎么写 where针对表中的列发挥作用,查询数据 having对查询结果中的列发挥作用,筛选数据 例子 #查询本店商品价格比市场价低多少钱,输出低200元以上的商品 select goods_id,good_name,market_price - shop_price as s from goods having s>200 ; //这里不能用where因为s是查询结果,而where只能对表中的字段名筛选 如果用where的话则是: select goods_id,goods_name from goods where market_price - shop_price > 200;
【3】Group by分组
一般情况下group需与统计函数(聚合函数)一起使用才有意义
如:select goods_id,goods_name,cat_id,max(shop_price) from goods group by cat_id;
这里取出来的结果中的good_name是错误的!因为shop_price使用了max函数,那么它是取最大的,而语句中使用了group by 分组,那么goods_name并没有使用聚合函数,它只是cat_id下的第一个商品,并不会因为shop_price改变而改变
mysql中的五种统计函数:1)max:求最大值、2)min:求最小值、3)sum:求总数和、4)avg:求平均值、5)count:求总行数
【4】Order by排序
(1)order by price //默认升序排列 (2)order by price desc //降序排列 (3)order by price asc //升序排列,与默认一样 (4)order by rand() //随机排列,效率不高
【5】limit(限制结果数)
做以下实验: 语句1: select * from table limit 150000,1000; 语句2: select * from table while id>=150000 limit 1000; 语句1为0.2077秒;语句2为0.0063秒 LIMIT 150000,1000意味着先要找到前150000条满足where条件的记录而后舍弃这些记录取之后满足where条件的1000条,这样的代价注定会非常高。 比较以上的数据时,我们可以发现采用where...limit....性能基本稳定,受偏移量和行数的影响不大 而单纯采用limit的话,受偏移量的影响很大,当偏移量大到一 定后性能开始大幅下降。不过在数据量不大的情况下,两者的区别不大。 所以应当先使用where等查询语句,配合limit使用,效率才高
二、左连接,右连接,内连接
【0】笛卡尔积
现有表a有10条数据,表b有8条数据,那么表a与表b的笛尔卡积是多少? select * from ta,tb //输出结果为8*10=80条(笛卡尔积)
如果在两张表里有相同字段,做联合查询的时候,要区别表名,否则会报错误(模糊不清)。
【1】左连接
以左表为准,去右表找数据,如果没有匹配的数据,则以null补空位,所以输出结果数>=左表原数据数 ...... from ta left join tb on ta.n1= ta.n2 [这里on后面的表达式,不一定为=,也可以>,<等算术、逻辑运算符]【连接完成后,可以当成一张 新表来看待,运用where等查询
左连接,其实就可以看成左表是主表,右表是从表。
【2】右连接
右连接查询跟左连接查询类似,只是右连接是以右表为主表,会将右表所有数据查询出来,而左表则根据条件去匹配,如果左表没有满足条件的行,则左边默认显示NULL。左右连接是可以互换的。
【3】内连接
内连接查询,就是取左连接和右连接的交集,如果两边不能匹配条件,则都不取出。它也被称为一个等值连接
查询结果是左右连接的交集,【即左右连接的结果去除null项后的并集(去除了重复项)】
语法:select n1,n2,n3 from ta inner join tb on ta.n1= ta.n2
【4】全连接查询 full join ... on ...
全连接会将两个表的所有数据查询出来,不满足条件的为NULL。
全连接查询跟全相乘查询的区别在于,如果某个项不匹配,全相乘不会查出来,全连接会查出来,而连接的另一边则为NULL。
【5】联合查询 union
union是求两个查询的并集。union合并的是结果集,不区分来自于哪一张表,所以可以合并多张表查询出来的数据。
将两张表的数据合并查询出来
SELECT id, content, user FROM comment UNION (SELECT id, msg AS content, user FROM feedback);
union查询,列名不一致时,以第一条sql语句的列名对齐
使用union查询会将重复的行过滤掉
使用union all查询所有,重复的行不会被过滤
union查询,如果列数不相等,会报列数不相等错误
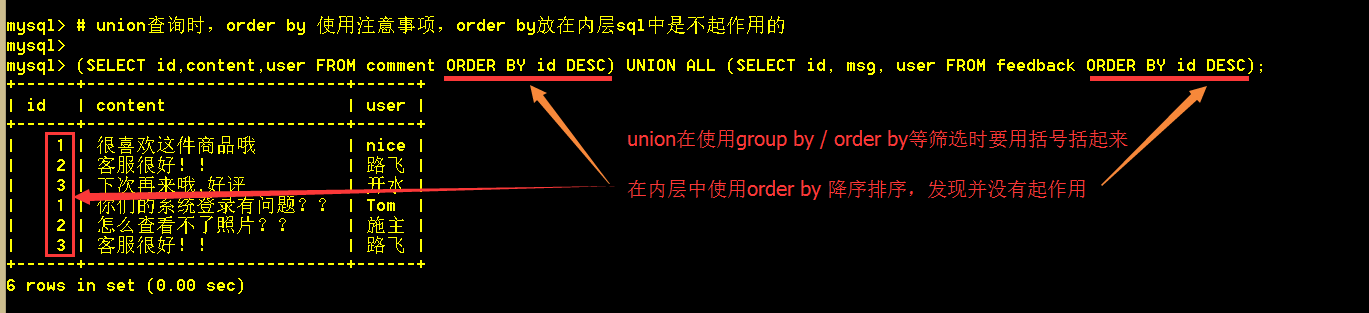
union查询时,order by放在内层sql中是不起作用的;因为union查出来的结果集再排序,内层的排序就没有意义了;因此,内层的order by排序,在执行期间,被mysql的代码分析器给优化掉了。
order by 如果和limit一起使用,就显得有意义了,就不会被优化掉。
( SELECT goods_name,cat_id,shop_price FROM goods WHERE cat_id = 3 ORDER BY shop_price DESC LIMIT 3 ) UNION ( SELECT goods_name,cat_id,shop_price FROM goods WHERE cat_id = 4 ORDER BY shop_price DESC LIMIT 2 );

