7.逻辑回归实践
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
防止过拟合方法:
算法层面-正则化:
- L1正则,通过增大正则项导致更多参数为0,参数系数化降低模型复杂度,从而抵抗过拟合。
- L2正则,通过使得参数都趋于0,变得很小,降低模型的抖动,从而抵抗过拟合。
数据层面:
- 加大样本量。
- 通过特征选择减少特征量。
过拟合的时候,拟合函数的系数往往非常大,而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况。
2.用logiftic回归来进行实践操作,数据不限
来预测客户是否订购定期存款与年龄、婚否、教育水平等因素的关系
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
import pandas as pd
# 读取数据
data = pd.read_csv('./bank.csv')
# 数据预处理
data=data.dropna()
# data['education'].unique()
# data.loc[data['education']=='primary','education']=0
# data.loc[data['education']=='secondary','education']=1
# data.loc[data['education']=='tertiary','education']=2
# data.loc[data['education']=='unknown','education']=3
# data['marital'].unique()
# data.loc[data['marital']=='married','marital']=0
# data.loc[data['marital']=='single','marital']=1
# data.loc[data['marital']=='divorced','marital']=2
# data['housing'].unique()
# data.loc[data['housing']=='yes','housing']=1
# data.loc[data['housing']=='no','housing']=0
#
# data.info()
# 归类(y - 客户是否订购了定期存款?)
data.loc[data['y']=='yes','y']=1
data.loc[data['y']=='no','y']=0
data['y'].value_counts()
# 数据分割
x_data = data.drop(["y"], axis=1)
y_data = data["y"]
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.3)
# 标准化处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 构建和训练模型
lg = LogisticRegression()
lg.fit(x_train, y_train)
print('lg.coef_:\n', lg.coef_)
lg_predict = lg.predict(x_test)
print('准确率:\n', lg.score(x_test, y_test))
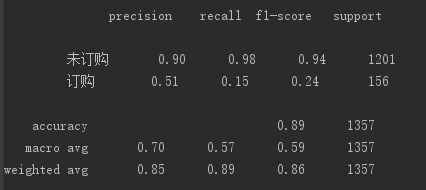
print('召回率:\n', classification_report(y_test, lg_predict, labels=[0, 1], target_names=['未订购', '订购 ']))
运行结果: