4.K均值算法--应用
1. 应用K-means算法进行图片压缩
读取一张图片
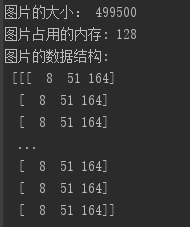
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
from sklearn.datasets import load_sample_image
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import matplotlib.image as img
import sys
import numpy as np
picture = img.imread("C://Users/lucas-lyw/Desktop/Lyw/sky.jpg") # 读取自己准备的图片
print("图片的大小:", picture.size)
print("图片占用的内存:", sys.getsizeof(picture))
print("图片的数据结构:\n", picture)
plt.rcParams['font.sans-serif'] = ['SimHei']
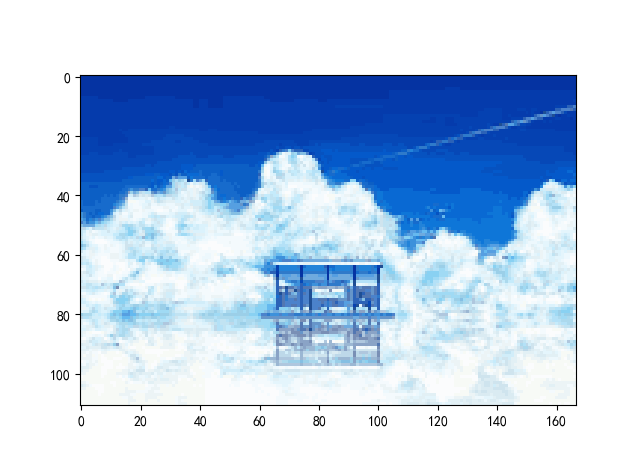
plt.imshow(picture) # 显示图片
plt.show()
image = picture[::3,::3] # 降低图片3倍的分辨率
x = image.reshape(-1,3)
print(image.shape,x.shape,picture.shape)
n_colors = 45
model = KMeans(n_colors) # 对颜色进行聚类
labels = model.fit_predict(x) # 获取每个像素的颜色类别
colors = model.cluster_centers_ # 每个类别的颜色
new_image = colors[labels].reshape(image.shape)
# 压缩图片
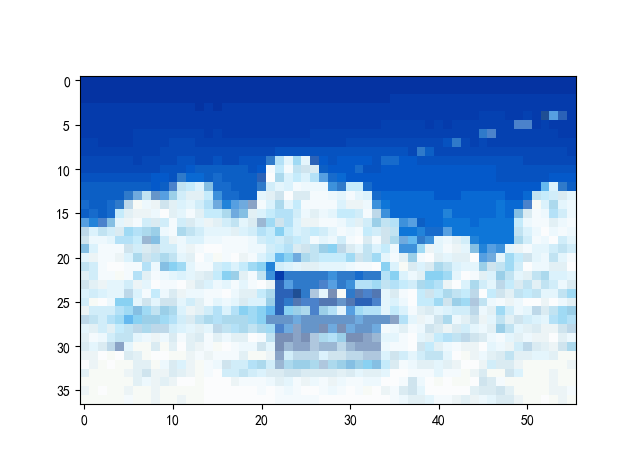
plt.imshow(new_image.astype(np.uint8))
plt.show()
# 二次压缩图片
plt.imshow(new_image.astype(np.uint8)[::3, ::3])
plt.show()
运行结果:
原图:

第一次压缩:
第二次压缩:
2. 观察学习与生活中可以用K均值解决的问题
from sklearn.cluster import KMeans
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
data = pd.read_csv('./data/house.csv',index_col=0)
#x = data.iloc[:,[2,7]].astype('int')
#x = np.array(x)
x = data.iloc[: ,[2]] #获取“总价”
y = data.iloc[:,[7]] #面积
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=5) #划分成功
km_model = KMeans(n_clusters=3)
km_model.fit(x)
y_kmeans= km_model.predict(x)
# price_high=np.array(data[y_kmeans==2]['总价'])
# price_mid=np.array(data[y_kmeans==1]['总价'])
# price_low=np.array(data[y_kmeans==0]['总价'])
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
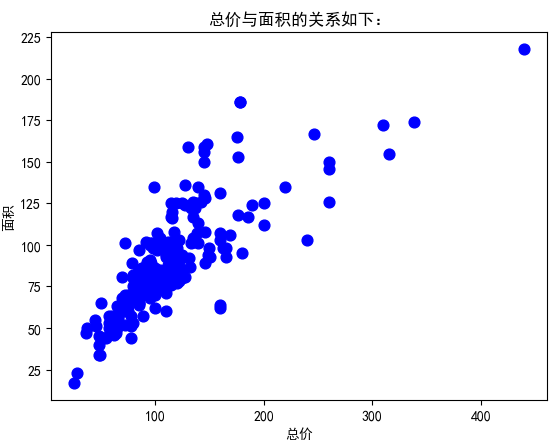
plt.xlabel('总价')
plt.ylabel('面积')
plt.title("总价与面积的关系如下:")
plt.scatter(x_test,y_test,s=60,c='blue')
运行结果: