

排序算法
一、冒泡排序
冒泡排序需要不断遍历需要排序的数组,一次比较两个数组元素,如果他们的排序不符合排序规则(例如从小到大),就将这两个元素的值进行交换。不断遍历数组直到没有数组元素需要置换则说明排序完成。
算法步骤:
1. 比较两个相邻的数组元素,如果他们的排序不符合排序规则就将他们的值进行交换
2. 不断比较每对相邻的数组元素,从第一组到末尾的最后一组。遍历完成后,最后的元素会是最大值。
3. 持续所有元素进行以上两种操作,除了每一轮遍历的最后一个数组元素。
4. 持续每次对越来越少的元素进行以上操作,直到没有数组元素需要置换为止。
时间复杂度: O(n^2) 空间复杂度 :O(1) 稳定性:稳定
动图演示
JAVA 实现
public void sort(int[] arr) { //得到数组的长度 int len = arr.length; // 确定每一次进行冒泡排序遍历的数组范围,从 0 到 i for (int i = len - 1; i >= 0; i--) { // j 表示这组需要进行比较的数据中下标小的那一位,j 从 0 到 i-1 // 比较相邻的元素,如果不符合排序规则就交换他们的值 // 设置标志位 flag,每次开始一轮新的比较是将其设置为 true,有数据进行交换时,将其设置为 false, // 若一轮下来flag 仍为 true,则排序完成 boolean flag = true; for (int j = 0; j < i; j++) { if (arr[j] > arr[j + 1]) { arr[j] = arr[j] + arr[j + 1]; arr[j + 1] = arr[j] - arr[j + 1]; arr[j] = arr[j] - arr[j + 1];
flag = false; } } if (flag) break; } }
二、选择排序
算法描述
1. 每次从未排序的数组中选取最小(大)的元素放在未排序数组的第一位
2. 从剩下的未排序的数组中选取最小(大)的元素放在未排序数组的第一位。
3. 重复步骤二,直至所有元素排序完成
时间复杂度:O(n^2) 空间复杂度:O(1) 稳定性:不稳定
动图演示
JAVA 实现
public void sort(int[] arr) { // 得到数组的长度 int len = arr.length; // 未排序数组从 i 到 len-1 for (int i = 0; i < len; i++) { // min 记录未排序数组最小值的下标 int min = i; // 遍历完整个未排序数组,得到最小值小标,将其与该未排序数组的第一个元素交换 for (int j = i+1; j < len; j++) { if (arr[j] < arr[min]) min = j; } if (min > i) { arr[i] = arr[i] + arr[min]; arr[min] = arr[i] - arr[min]; arr[i] = arr[i] - arr[min]; } } }
三、插入排序
插入排序是一个比较有意思的排序方式,它的实现比较简单,但是又有点值得深究的东西。
插入排序先使得 0 ~ 0 有序(这相当于废话);再往后添加一个元素,使得 0 ~ 1 有序;往后不断添加元素,当排到第 m 个元素时,前 0 ~ m-1 均为顺序排序,此时你要做的就是将 0 ~ m 变为顺序排序,怎么实现呢?
例如以下数组 array
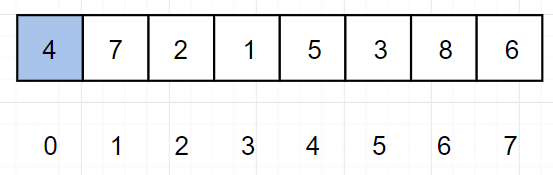
(1)使得 0 ~ 0 有序(完成)
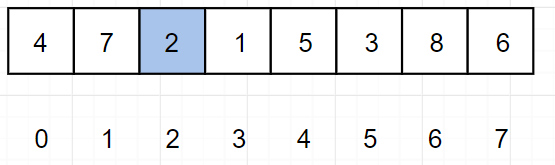
(2)m = 1,使得 0 ~ 1 有序

因为 array[0] > array[1] 不成立,所以排序完成。
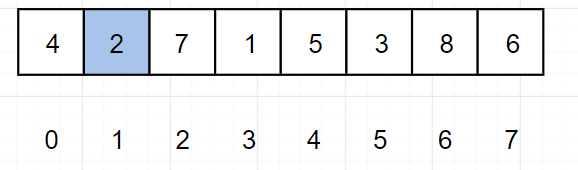
(3)m = 2 ,使得 0 ~ 2有序
因为 array[1] > array[2] ,所以将 array[1] 与 array[2] 调换位置,变成
因为 array[0] > array[1] ,所以将 array[0] 与 array[1] 调换位置,变成
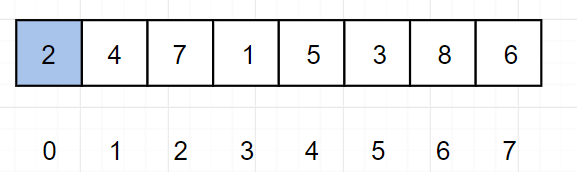
因为此时已经到达了下标为 0 的位置,因此排序完成。
(4)往后的元素也是这样,原下标为 m 的元素,不断与 0 ~ m- 1 中的元素进行比较、交换,直到左边相邻的数小于等于它 或者 已经到达了边界,则该轮排序完成。
JAVA 实现
public void insertionSort(int[] arr) { if (arr == null || arr.length < 2) { return; } // 0 ~ i-1 有序 // 使得 0 ~ i 之间有序 for (int i = 1; i < arr.length; i++) { // 比较相邻两个元素 j 和 j+1,当 arr[j] > arr[j+1] 并且 j >= 0 时将两个数交换并继续向前比较,否则排序完成 for (int j = i - 1; j >= 0 && arr[j] > arr[j + 1]; j--) { swap(arr, j, j + 1); } } } public void swap(int[] arr, int i, int j) { if(arr[i] == arr[j]) return; arr[i] = arr[i] ^ arr[j]; arr[j] = arr[i] ^ arr[j]; arr[i] = arr[i] ^ arr[j]; }
插入排序的 时间复杂度为 O(n^2),但是插入排序和选择排序、冒泡排序不同的是:选择排序和冒泡排序的算法流程与数据状况无关,时间复杂度没有变化,例如
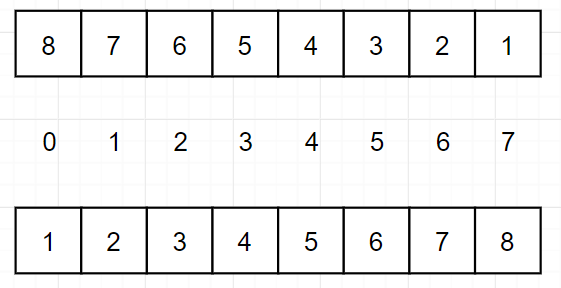
这两个特殊数组,
选择排序在两个数组中都会遍历 0~ n-1, 1~n-1,...., n-2~n-1,时间复杂度为 O(N^2);插入排序在两个数组中都会遍历 0 ~ n-1, 0 ~ n-2,... ,0~1,时间复杂度为 O(N^2)
插入排序与之不同的是,在第一个数组中,每次在 0 ~ m 个元素中都会进行 m 次比较、交换,时间复杂度为 O(N^2);但是在第二个数组中,每次在 0 ~ m 中只需要进行一次比较,不需要交换,时间复杂度为 O(N).
因此,如果需要排序的数组大部分是有序的,使用插入排序的效率甚至会比 O(N*logN) 级别的算法还好。例如对日志进行排序,因为日志是按时间顺序生成的,所以大部分是有序的,可能小部分在传输的过程中调换位置导致错序,这种情况下,使用插入排序效率就很高。
插一句:我个人觉得,插入排序和冒泡排序虽然思想不一样,但是实现是差不多的。然而插入排序是在一段已经排好序的数组上进行操作,而冒泡排序虽然每次都缩短了需要操作的数组的长度,但是数组都是无序的,没有利用上一次排序的结果,所以大部分时候冒泡排序的效率更低一些也不是不能理解了。
希尔排序
希尔排序是插入排序的一种拓展运用,与插入排序不同的是,一次希尔排序两个比较的值之间的距离不一定是 1,可以是任意长度,逐渐减小,但是最后都需要进行一次距离为 1 的插入排序,而插入排序两个值之间的距离一直都是 1。这里具体不展开了,只提供了代码参考。
public void ShellSort(int[] arr, int len) { int h = 0; while (h < len / 3) { h = h * 3 + 1; // 1,4,13,40,... h 的规则可以自己设置 } while (h > 0) { for (int i = h; i < len; i++) { // i : 现在正在排序的元素下标 int temp = arr[i]; int j = i; for (; j >= h && temp <= arr[j - h]; j -= h) { arr[j] = arr[j - h]; } arr[j] = temp; } h = h / 3; } }
四、归并排序
归并排序的 时间复杂度为 O(N*logN),空间复杂度为 O(N);
1. 算法流程
(1)实际上是一个简单递归,从数组的中间 mid 将数组分开,使之左边排好序,右边排好序,再将其整体排序
(2)将其整体排序的过程里使用了排外序方法。
2. 所谓排外序方法,就是创建一个与排序数组等大的数组空间,将其从中间分为两段,分别从两端的第一个元素(设为 p1,p2)开始比较,若 p1 指向元素小于等于 p2指向元素,则将 p1 放入新数组,p1++,反之放入 p2,p2++
不断比较放置,直至两组元素中一组的元素已全部拷进新数组空间,则将另一组的剩下所有元素拷进新数组空间。
最后,将新数组空间中的值全部拷贝回原数组的原数组区间中即可。
3. JAVA 实现
public static void mergeSort(int[] arr) { if(arr == null || arr.length <2) { return; } process(arr, 0, arr.length-1); } // 在 [L,...,R]上,排好序 public static void process(int[] arr, int L, int R) { // 终止条件:当需要排序的数组区间中只有一个元素时,说明排序完成,返回 if (L == R) return; // 排序数组中位数的下标 int mid = L + ((R - L) >> 1); // 得到以 mid 为中电划分的两个数组的有序数组 process(arr, L, mid); process(arr, mid + 1, R); // 将该排序数组区间的元素进行整体的排序 merge(arr, L, mid, R); } public static void merge(int[] arr, int L, int M, int R) { // 先开辟一个与传进来的需排序数组等大的空间 int[] space = new int[R - L + 1]; int i = 0;// 新数组的下标 int p1 = L;// 左边数组的下标 int p2 = M + 1;// 右边数组的下标 // 当以mid 划分的两个数组都没有越界时 while (p1 <= M && p2 <= R) { // 当 arr[p1] <= arr[p2] ,将arr[p1] 赋值给 arr[i],接着 p1 ++,i++ space[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++]; } // 当左边数组越界时 //由于上一个 while 的跳出条件必须为一边越界,所以右边没有越界,说明左边一定越界, //因此可以省略判断左边是否越界的 p1 > M 这个条件,下同 while ( p2 <= R) { space[i++] = arr[p2++]; } // 当右边数组越界时 while ( p1 <= M) { space[i++] = arr[p1++]; } // 将新开辟的空间中的数组拷贝回原数组 for (i = 0; i < space.length; i++) { arr[L + i] = space[i]; } }
4. 特别注意,归并排序的时间复杂度只有 O(N*logN),你可能一下子没有明白为什么它就比选择排序,冒泡排序好呢?
首先先不提它为什么好,先来说说为什么选择排序这个 O(N^2),为什么不好。
选择排序第一步在 0 ~ n-1 中比较 n-1 次 选择最小值将其放进 arr[0],从而完成第一个数的排序;第二部在 1 ~ n-1 中比较 n-2 次选择最小的值放进 arr[1],.....
也就是说,选择排序每轮会比较 n 次以完成一个数的排序任务,并且每轮之间的比较是独立的,很显然,这大大的浪费了比较资源,导致效率降低。
而归并排序每一次的比较都会完成一个元素的排序,并且每一轮排序的结果(数组),会和下一个数组 merge,并没有浪费比较资源。
5. 我们都知道,递归都是可以写成循环的,在归并排序中,我们可以用 p 进行控制,
当 p = 1 时表示相邻一个数之间 进行merge,相当于废话,因为相邻一个属即只有一个数;
下一步,p = 2 表示相邻两个数之间进行 merge(mid = L + p/2 - 1);
下一步,p = 4 mid = L + p/2 - 1,也就是 p 的一半。
左右数组的长度为 p/2,如果没有右数组,则不进行 merge。
( 这个算法是我根据自己的理解写出来,如果有不完备的地方,希望可以得到指点)
public static void mergeSort(int[] arr) { int len = arr.length; int p = 2; // 当由数组至少还有一个数时,都要进行排序 while (p / 2 < len) { int L = 0; int M = L + p / 2 - 1; int R = p - 1; while (R <= len - 1) { merge(arr, L, M, R); // 和递归算法中的 merge 相同 L += p; M += p; R += p; } if (R > len - 1 && M < len - 1) { merge(arr, L, M, len - 1); } p = (p << 1); }
}
从循环实现可以很明显得看出为什么归并排序的时间复杂度是 O(N*logN)
因为 p 取值为 2,4,8,16,.......,log2(N)
每一轮循环都会进行 N 进比较。
所以就是 O(N*logN)
五、堆排序
详解 堆结构及堆排序:https://www.cnblogs.com/lyw-hunnu/p/12762698.html
// 堆排序 public static void heapSort(int[] arr) { if (arr == null || arr.length < 2) { return; } // 形成大根堆: // O(N) for (int index = arr.length - 1; index >= 0; index--) { heapify(arr, index, arr.length); } // 将堆中最大值逐个放在 arr.length-1,arr.length-2,...,1 的位置 // O(N*logN) int heapSize = arr.length;// 记录堆中元素的个数,如果一个数排序完成(放在堆数组的最后),就将他从堆数组中除去(heapSize--); swap(arr, 0, --heapSize);// 将堆中的最大值放在数组的最后,此时最大值排序完成,堆数组的个数减一 while (heapSize > 0) {// O(N) heapify(arr, 0, heapSize);// O(logN) swap(arr, 0, --heapSize);// O(1) } }
六、快速排序
快速排序采用分治的思想来进行排序,将一个序列分为较小和较大两个子序列,在递归地排序两个子序列,
算法步骤
1. 在数组中寻找一个”基准“,选取”基准“有很多方法,可以直接将数组地第一个元素当作”基准“
2. 对数组进行分割:将数组中比”基准“小的值都排到”基准“的前面,比”基准“大的值都排到”基准“的后面。
3. 递归排序子序列:递归地将小于基准值的序列 和 大于基准值的序列进行排序。
时间复杂度:O(nlogn ) 空间复杂度:O(nlogn) 稳定性:不稳定
JAVA 实现
public void sort(int[] arr) { quick(arr, 0, arr.length - 1); } /** * 快速排序的递归方法,当数组序列中的元素个数 大于等于 1 时调用 * @param arr 需要排序的数组 * @param start 数组序列的开始的下标 * @param end 数组序列的结束的下标 */ public void quick(int[] arr, int start, int end) { if (1 == start - end) return; // 保存参数值 int left = start; int right = end; // 选取基准数 int base = arr[start]; // 将数组序列分割为两个子序列 while (left < right) { // 从right开始向左遍历,找到比 基准小的元素的下标 while (left < right && arr[right] > base) { right--; } // 从 left 向有遍历,找到比基准大的元素的下标 while (left < right && arr[left] < base) { left++; } // 根据设置的条件可知,left > right 在这里不会存在 // 当两边分别找到与 基准相同的值而停止时,打破僵局 // 否则,将下标为 left 和 right 的值进行交换, if (arr[left] == arr[right] && left < right) { left++; } else { // 不可以用这种置换方式,最后一次内循环,到达这一步时, left == right // arr[left] = arr[left] + arr[right]; // arr[right] = arr[left] - arr[right]; // arr[left] = arr[left] - arr[right]; int temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; } } // 递归排序两个子序列 if (start < left - 1) quick(arr, start, left - 1); if (end > right + 1) quick(arr, right + 1, end); }
